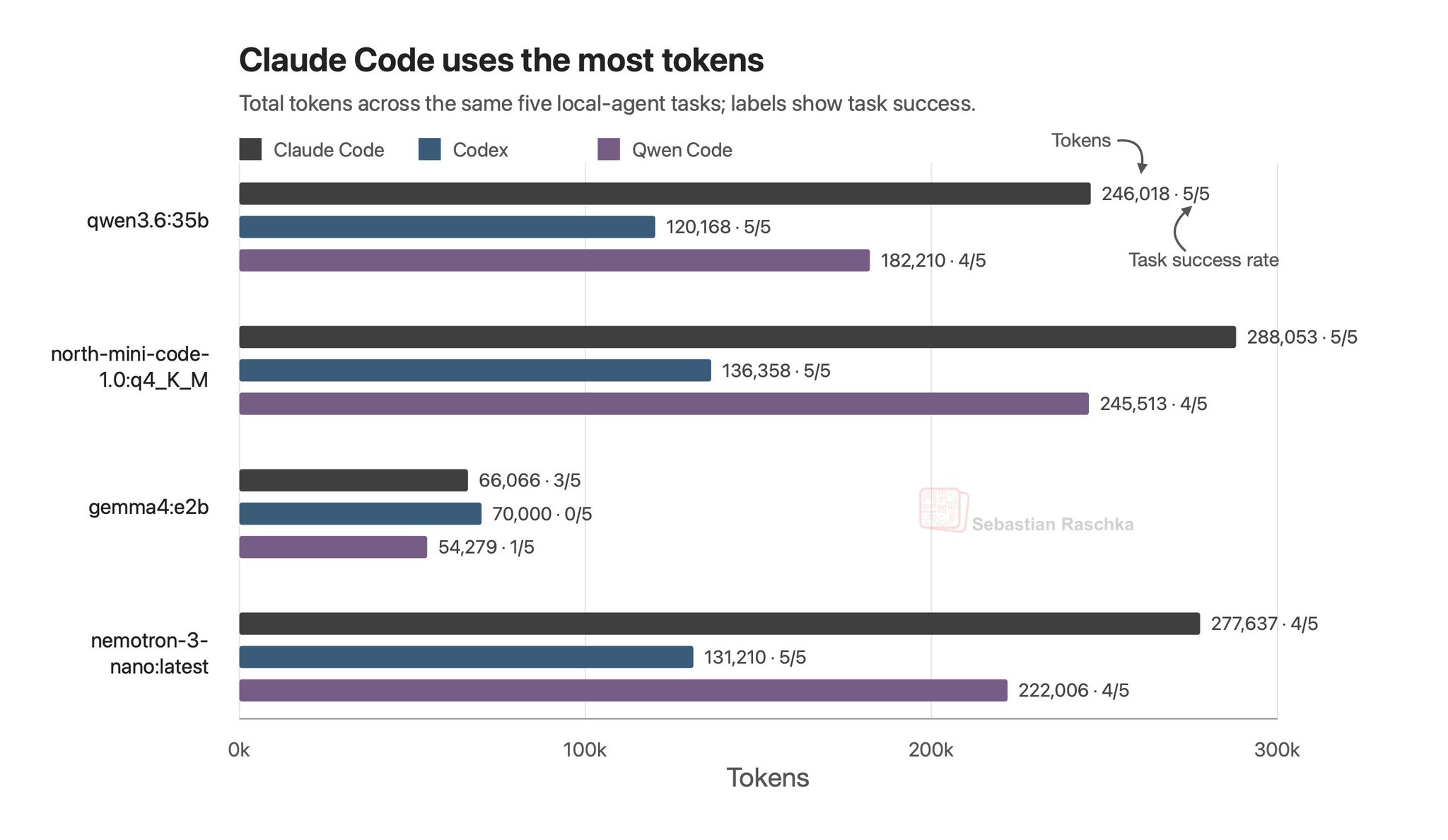
108 real-world, long-horizon computer-use workflows. Average rollout: 318 tool calls.
— Snorkel AI (@SnorkelAI) 26 juin 2026
Top frontier agent (Claude Opus 4.8 with max thinking + batched tool calls): 20.6% end-to-end completion (54.8% partial progress). Partial progress is real. Reliable end-to-end computer use is… https://t.co/aK42mNsHdx
108 real-world, long-horizon computer-use workflows. Average rollout: 318 tool calls. Top frontier agent (Claude Opus 4.8 with max thinking + batched tool calls): 20.6% end-to-end completion (54.8% partial progress). Partial progress is real. Reliable end-to-end computer use is