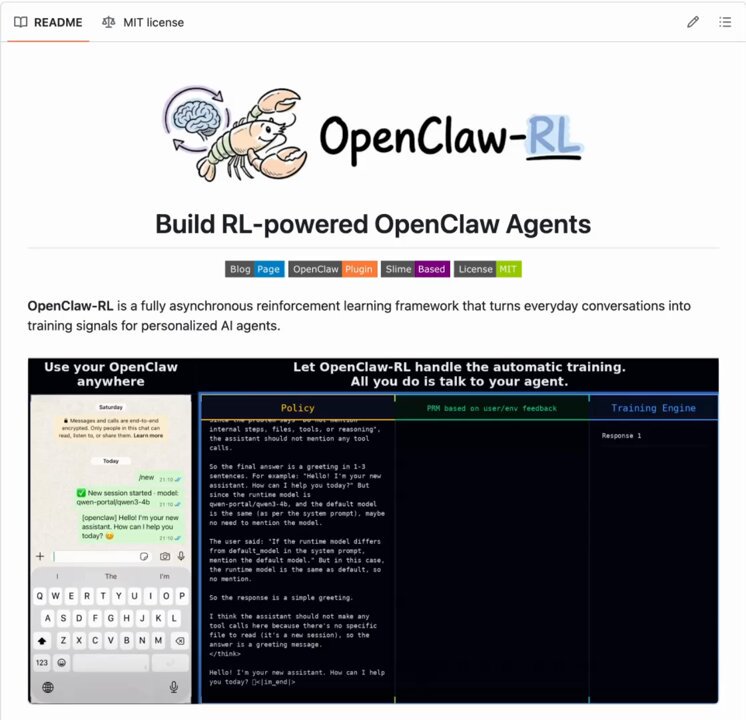
OpenClaw meets RL!
— Akshay 🚀 (@akshay_pachaar) 12 avril 2026
OpenClaw Agents adapt through memory files and skills, but the base model weights never actually change.
OpenClaw-RL solves this!
It wraps a self-hosted model as an OpenAI-compatible API, intercepts live conversations from OpenClaw, and trains the policy in… pic.twitter.com/4kxY1b2wSC
OpenClaw meets RL! OpenClaw Agents adapt through memory files and skills, but the base model weights never actually change. OpenClaw-RL solves this! It wraps a self-hosted model as an OpenAI-compatible API, intercepts live conversations from OpenClaw, and trains the policy in the background using RL. The architecture is fully async. This means serving, reward scoring, and training all run in parallel. Once done, weights get hot-swapped after every batch while the agent keeps responding. Currently, it has two training modes: – Binary RL (GRPO): A process reward model scores each turn as good, bad, or neutral. That scalar reward drives policy updates via a PPO-style clipped objective. – On-Policy Distillation: When concrete corrections come in like "you should have checked that file first," it uses that feedback as a richer, directional training signal at the token level. When to use OpenClaw-RL? To be fair, a lot of agent behavior can already be improved through better memory and skill design. OpenClaw's existing skill ecosystem and community-built self-improvement skills handle a wide range of use cases without touching model weights at all. If the agent keeps forgetting preferences, that's a memory problem. And if it doesn't know how to handle a specific workflow, that's a skill problem. Both are solvable at the prompt and context layer. Where RL becomes interesting is when the failure pattern lives deeper in the model's reasoning itself. Things like consistently poor tool selection order, weak multi-step planning, or failing to interpret ambiguous instructions the way a specific user intends. Research on agentic RL (like ARTIST and Agent-R1) has shown that these behavioral patterns hit a ceiling with prompt-based approaches alone, especially in complex multi-turn tasks where the model needs to recover from tool failures or adapt its strategy mid-execution. That's the layer OpenClaw-RL targets, and it's a meaningful distinction from what OpenClaw offers. I have shared the repo in the replies!
→ View original post on X — @akshay_pachaar, 2026-04-12 13:35 UTC