This is a nice paper, well executed! @scott_e_reed had this in mind when developing Gato https://
arxiv.org/abs/2205.06175 — I’m glad to see the idea executed with a humanoid and I’d love to see more work along this direction. Gato stood for General AgenT One. Sadly, we weren’t able to
AGI
-
Paper praised for executing Gato idea with humanoid; more work desired
By
–
-
Anthropic predicts AI self-improvement by end of 2028
By
–
Anthropic is fully RSI pilled:
— Chubby♨️ (@kimmonismus) 27 juin 2026
"My prediction is by the end of 2028, it's more likely than not that we have an AI system where you would be able to say to it, 'Make a better version of yourself.' Completely autonomously."
pic.twitter.com/OURncC4PHlAnthropic is fully RSI pilled: "My prediction is by the end of 2028, it's more likely than not that we have an AI system where you would be able to say to it, 'Make a better version of yourself.' Completely autonomously."
-
Debate on steady-state vs exponential intelligence value
By
–
It is entirely possible that the steady-state people will prove to be right in the future, but there's no sign of a slowdown yet. And if greater intelligence brings greater value at an exponential pace (which it has, but may not always) then it matters a lot which world we're in.
-
More companies falling behind frontier models, early RSI acceleration
By
–
More companies are falling behind the frontier than keeping up with it (Mistral, Grok, etc.) & we are in the era of early RSI where there is acceleration. I haven’t seen any evidence of sudden frontier models emerging, but interested in seeing what you are hinting at.
-
Next-token prediction compresses latent structure into understanding
By
–
A model trained for next-token prediction is forced to build compressed representations of latent structure in text. Ilya Sutskever correctly refers to this phenomenon as understanding. Here, a model trained for next-step sensor prediction, with a robot that has proprioception… pic.twitter.com/rHh1nFjJxd
— Nando de Freitas (@NandoDF) 27 juin 2026A model trained for next-token prediction is forced to build compressed representations of latent structure in text. Ilya Sutskever correctly refers to this phenomenon as understanding. Here, a model trained for next-step sensor prediction, with a robot that has proprioception
-
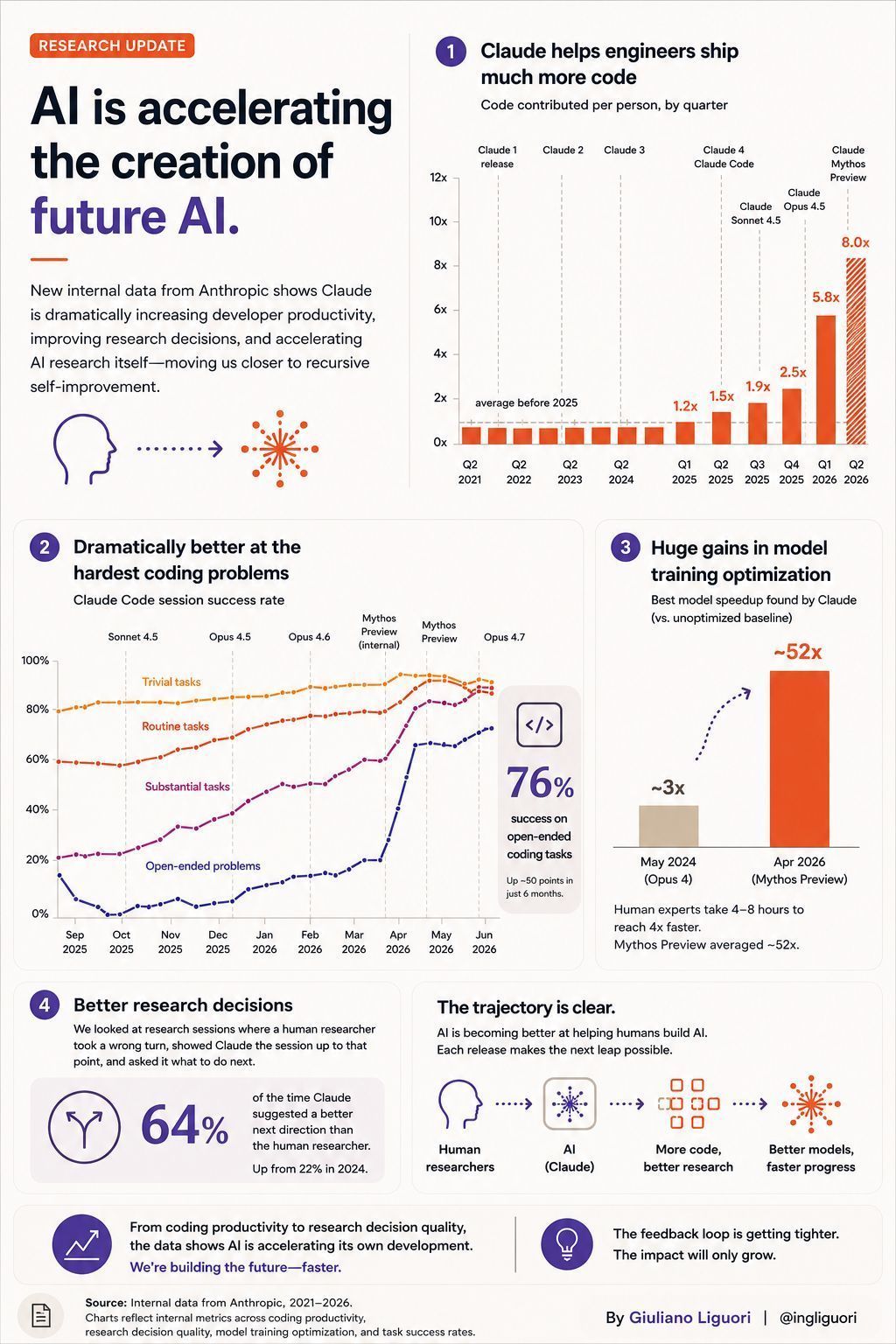
AI outperforms humans in research
By
–
The most interesting result in Anthropic's latest paper isn't the 8x increase in code output. It's this: Claude Mythos Preview suggested a better research direction than humans 64% of the time. We're moving beyond AI that writes code. We're approaching AI that helps decide.
-
Access to frontier models cut off, changing the future
By
–
It is absolutely crazy how the last two weeks have changed the entire future. It is unprecedented that access to "frontier" models was cut off,and presumably remains cut off forever. It feels like a watershed moment, as if access to the highest level of human intelligence had
-
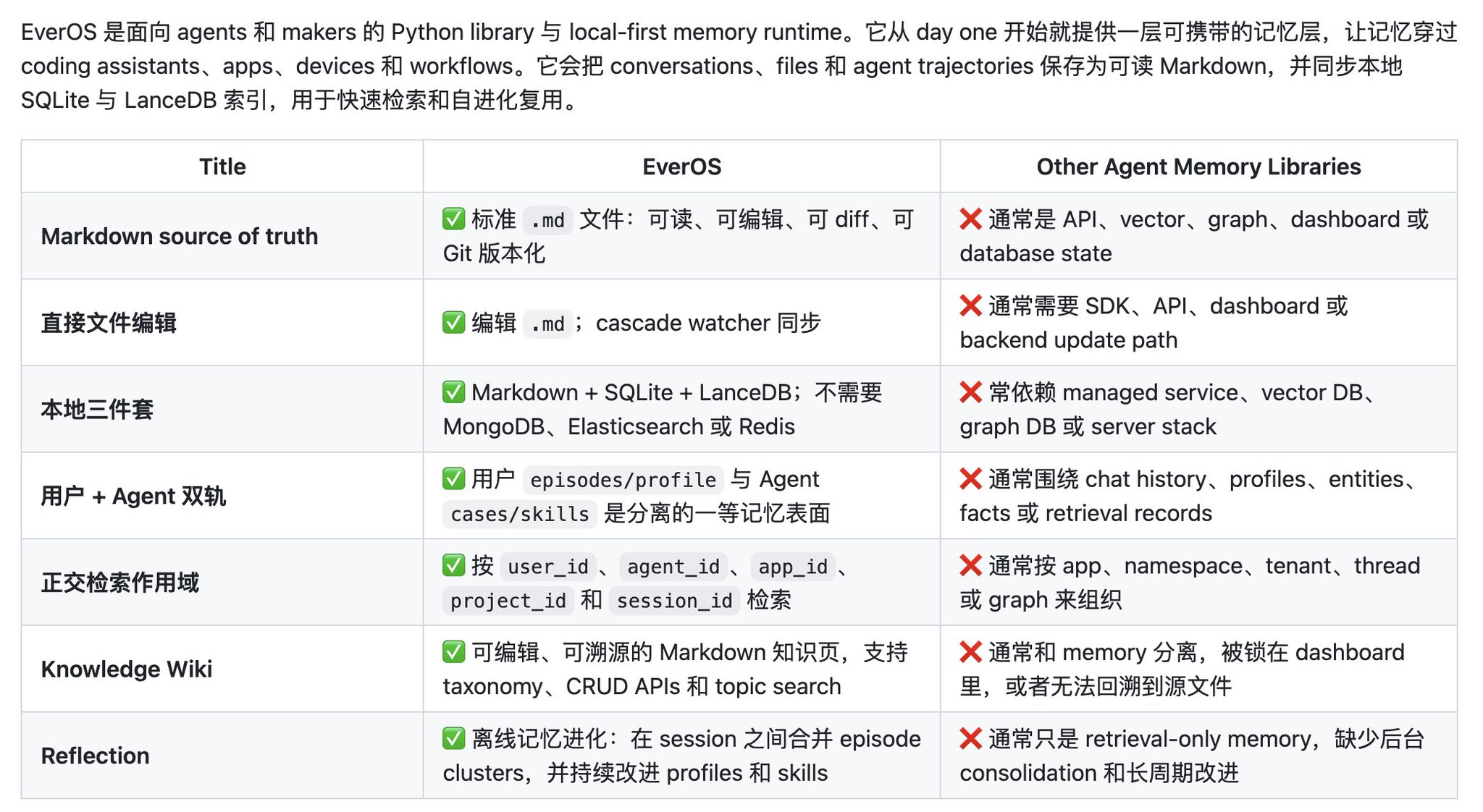
Raven: Memory-First Self-Evolving Agent Coming Soon
By
–
Perhaps the market won't even give us six months. We are also juggling research, development, product, design, and operations. However, under this pace, it is difficult to ensure academic results, code quality, product experience, and even design taste. Fortunately, the team atmosphere is very good, and everyone wants to make this happen. You can also look forward to our upcoming release of Raven, a Memory-first, ultra-strong self-evolving Agent.
-
The closing frontier of AI exploration and opportunity loss
By
–
It’s sad anyone with a credit card will no longer be able to explore the jagged frontier. The quirky Twitter path I followed to a career in AI (frontier LLM poasting) is closing. The best AI will be seen by fewer people and something important will be lost.
-

GoalOS aims for proof-gated autonomous work generating verified capability
By
–
GoalOS is architecturally pointed at one of the Holy Grails: proof-gated, economically coordinated, open-ended autonomous work that can generate verified experience and reusable capability. #AGIALPHA