
"Improved Large Language Diffusion Models" ByteDance just made bidirectional masked diffusion on-par with autoregessive LM! This paper iLLaDA trains an 8B Transformer from scratch on 12T tokens, then keeps the same denoising objective for SFT on a 25B-token instruction corpus.
@askalphaxiv
-
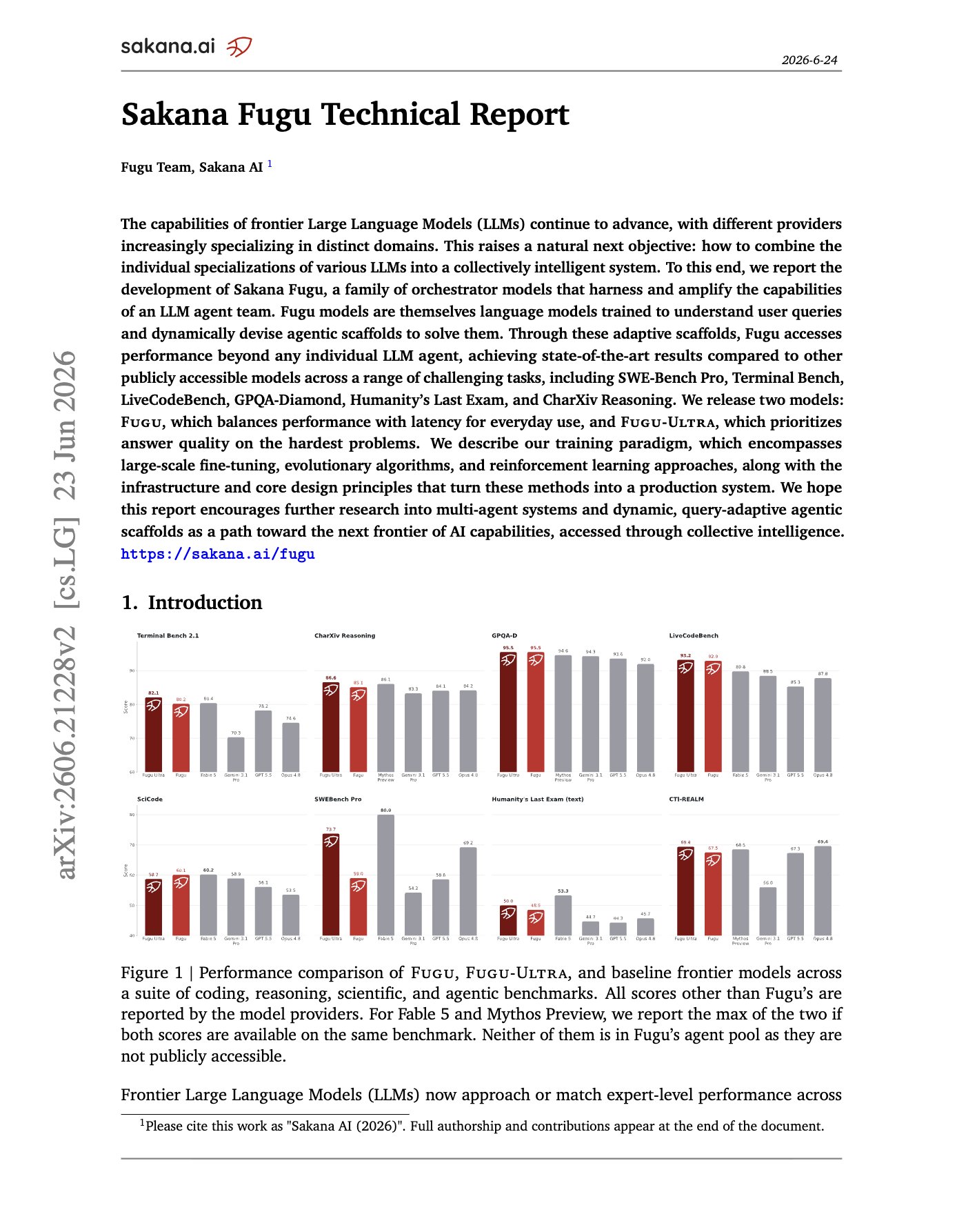
Sakana AI’s Fugu dynamically routes queries to multiple models
By
–
Sakana Fugu Technical Report Instead of training one larger model, Sakana AI trains an orchestrator that reads each query and dynamically routes or composes GPT-5.5, Gemini-3.1-Pro, Claude Opus 4.8 and other agents into query-specific workflows. With Fugu being the fast router,
-

PACE: Training optimizers for the averaged model you return
By
–
"Training for the Model You Return" Most LM pipelines return an EMA or averaged checkpoint, but optimizers still train like the final iterate is what matters. So if the output is an averaged model, can we shape training so that average gets better? This paper introduces PACE,
-

Autodata: An agentic data scientist to create high quality synthetic data
By
–
"Autodata: An agentic data scientist to create high quality synthetic data" If there's auto-research, shouldn't there also be a auto-data generation? In this new Meta paper, they proposed Autodata, which makes synthetic data generation work more like a data scientist, with an
-
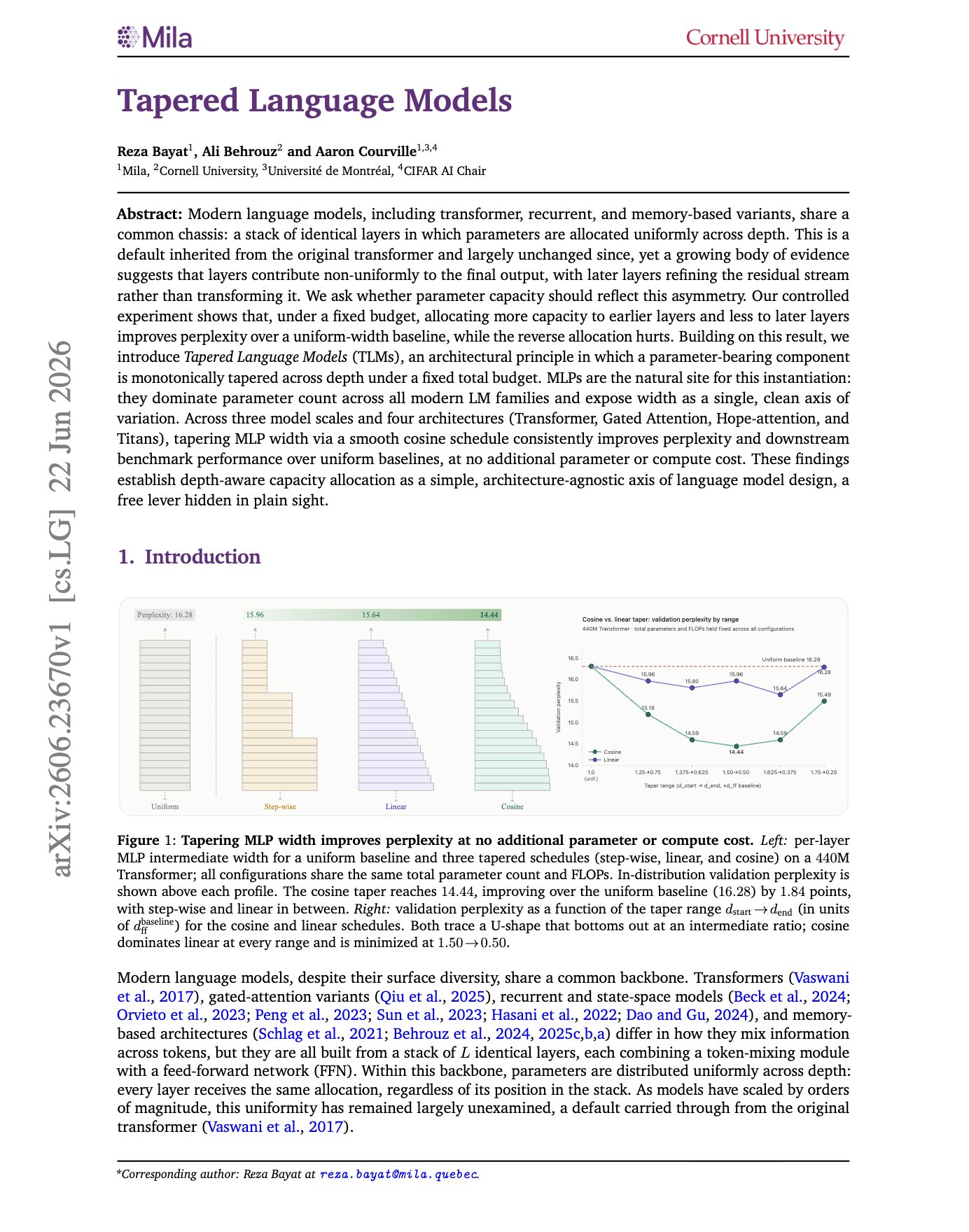
Tapered LMs: Early layers write more, later layers refine
By
–
“Tapered Language Models” Most LMs give every layer the same MLP width, but the paper shows this is probably wasteful. Early layers seem to write more new information into the residual stream, while later layers mostly refine what is already there. So instead of making the
-
GLM 5.2 enables trusted open model for automated research tasks
By
–
1/2 This is obviously not a comprehensive benchmark, but it’s clear that we finally have an open model that can be trusted and depended upon on difficult research tasks. You can easily run autoresearch yourself with GLM 5.2 by changing ‘arxiv’ to ‘autoarxiv’ for any arXiv URL:
-
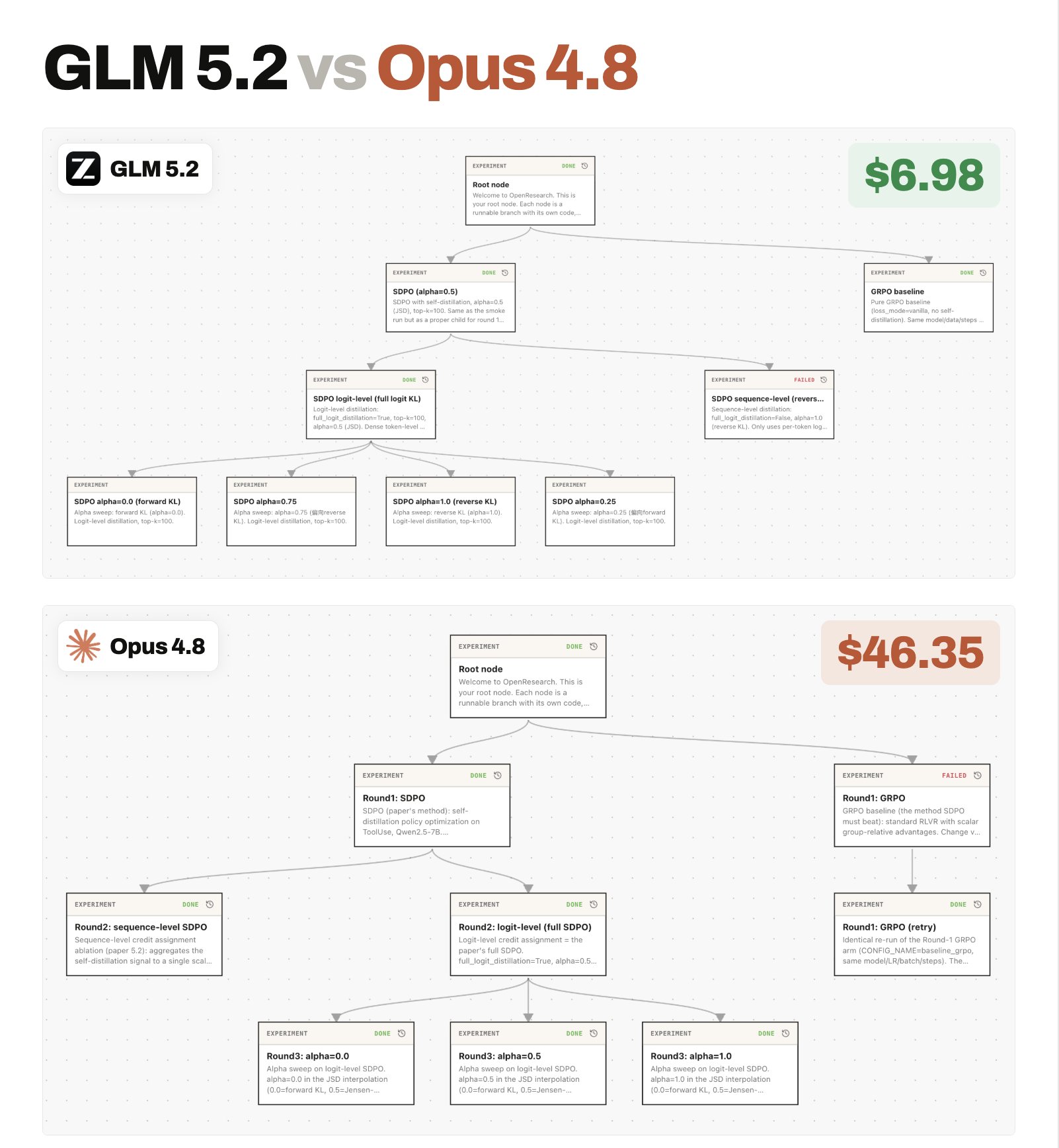
Comparison of GLM 5.2 and Opus 4.8 on SDPO paper reproduction
By
–
Here’s a fun comparison between GLM 5.2 and Opus 4.8 on a one-shot reproduction of the SDPO paper This is a hard task: the model must resolve messy verl issues and then run ablations to completion and confirm the paper’s claims. – GLM 5.2 costs $6.21 while Opus 4.8 cost us
-

TMAX: Open Reinforcement Learning Recipe for Terminal Agents
By
–
A first-of-its-kind open reinforcement learning recipe for terminal agents has just been released. As terminal agents become the primary interface for coding models, this paper, TMAX, shares a reproducible training recipe.
-

VisualClaw: Real-time personalized agent using only key video moments.
By
–
"VisualClaw: A Real-Time, Personalized Agent for the Physical World" AI agents for video are too expensive because they usually send too many frames to the model, and they do not learn from past mistakes. This paper proposes a way to keep only the important video moments,
-

Multimodal AI connects 3D atomistic models with language
By
–
"Atomistic Language Models Understand and Generate Materials" Most materials AI still treats crystals and language separately, either turning atoms into lossy text formats or making LLMs call atomistic tools. This paper makes materials natively multimodal by connecting a 3D