This is a nice paper, well executed! @scott_e_reed had this in mind when developing Gato https://
arxiv.org/abs/2205.06175 — I’m glad to see the idea executed with a humanoid and I’d love to see more work along this direction. Gato stood for General AgenT One. Sadly, we weren’t able to
MACHINE LEARNING
-
Paper praised for executing Gato idea with humanoid; more work desired
By
–
-
Using video to learn control representations, touch important
By
–
I think they also emerge from video. This is what I was the most excited about when helping with projects like Veo. My intent was never to create slop videos, but rather to use video to learn representations for control. I must say however that touch is super important and highly
-
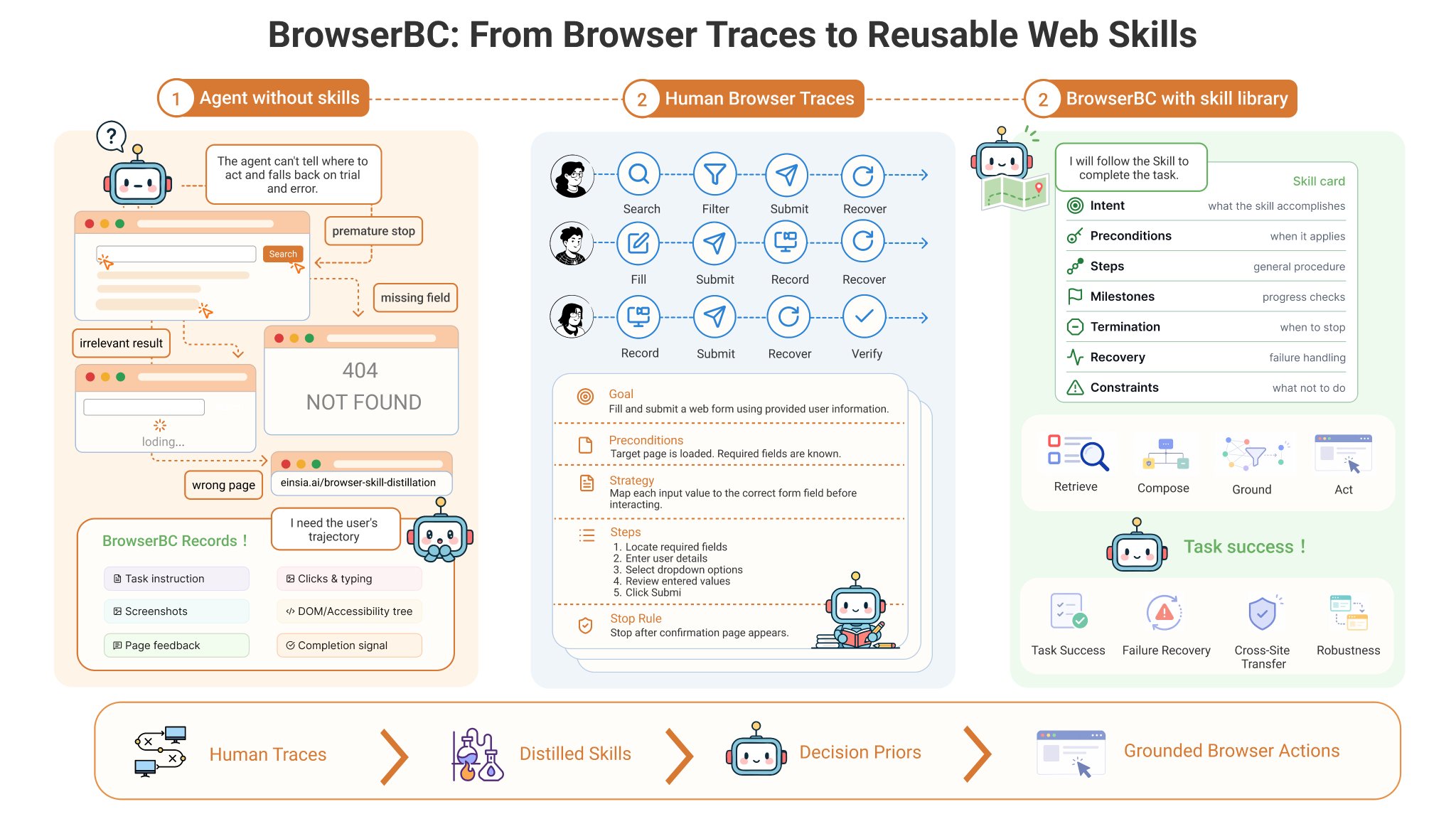
BrowserBC explores efficient web agents by distilling human flows
By
–
BrowserBC, a new open-source project from the ViDA team, explores a more efficient way to run web agents. Instead of using a frontier model for every step of an agent workflow, BrowserBC records a human web flow once with a stronger model, distills it into a reusable skill, and
-

Combining LLMs: analysis of routing, voting, cascades
By
–
When does combining LLMs help? Great analysis on combining language models, measured across 67 models from 21 providers. Any policy that routes, votes, cascades, or runs a mixture of agents and then returns one model's answer is bounded above by 1 minus beta, where beta is the
-
World Labs improves at large open sky scenes
By
–
Nice, world labs is getting good at large open sky scenes!
-
Anthropic predicts AI self-improvement by end of 2028
By
–
Anthropic is fully RSI pilled:
— Chubby♨️ (@kimmonismus) 27 juin 2026
"My prediction is by the end of 2028, it's more likely than not that we have an AI system where you would be able to say to it, 'Make a better version of yourself.' Completely autonomously."
pic.twitter.com/OURncC4PHlAnthropic is fully RSI pilled: "My prediction is by the end of 2028, it's more likely than not that we have an AI system where you would be able to say to it, 'Make a better version of yourself.' Completely autonomously."
-
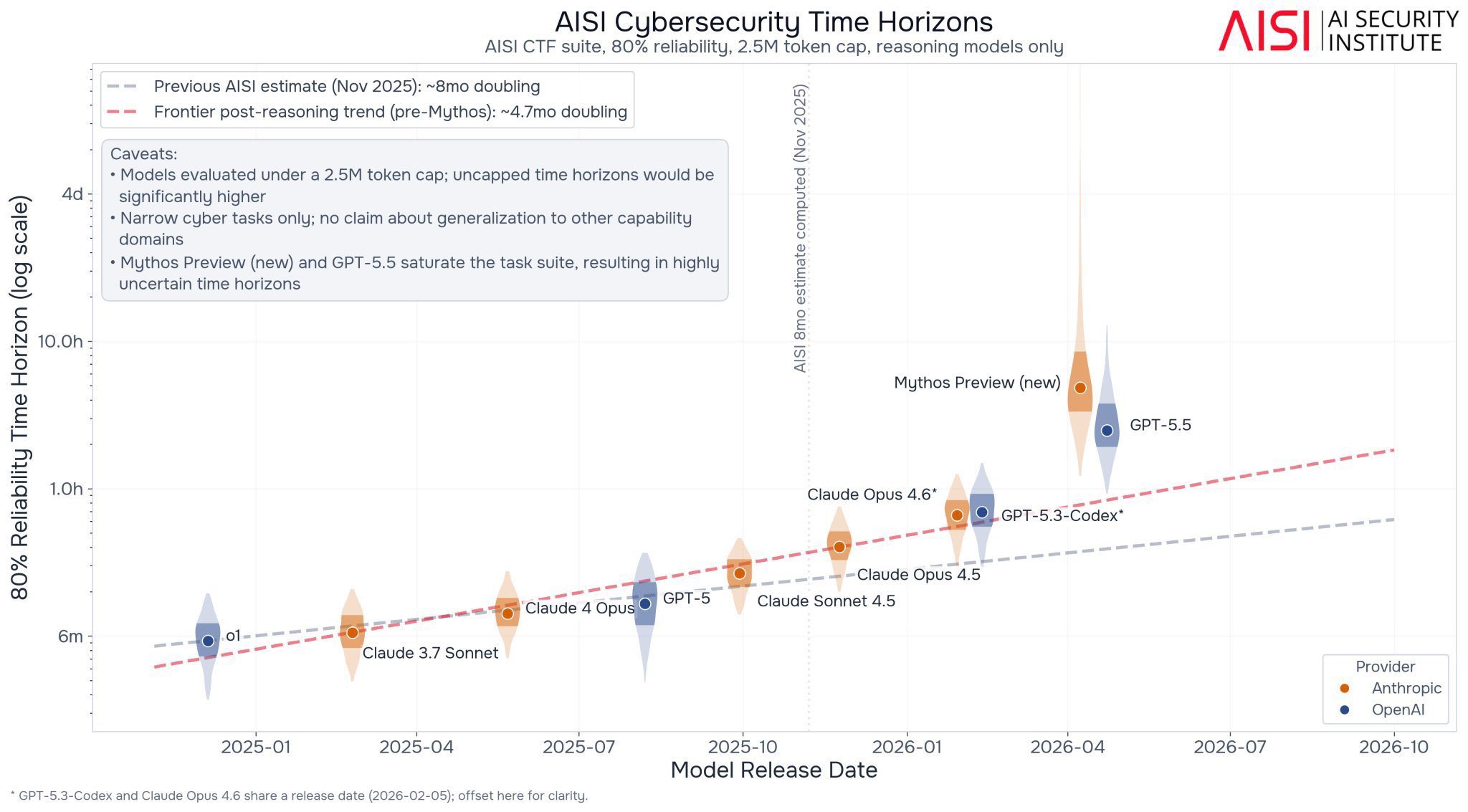
Exponential growth confirmed by multiple AI benchmarks
By
–
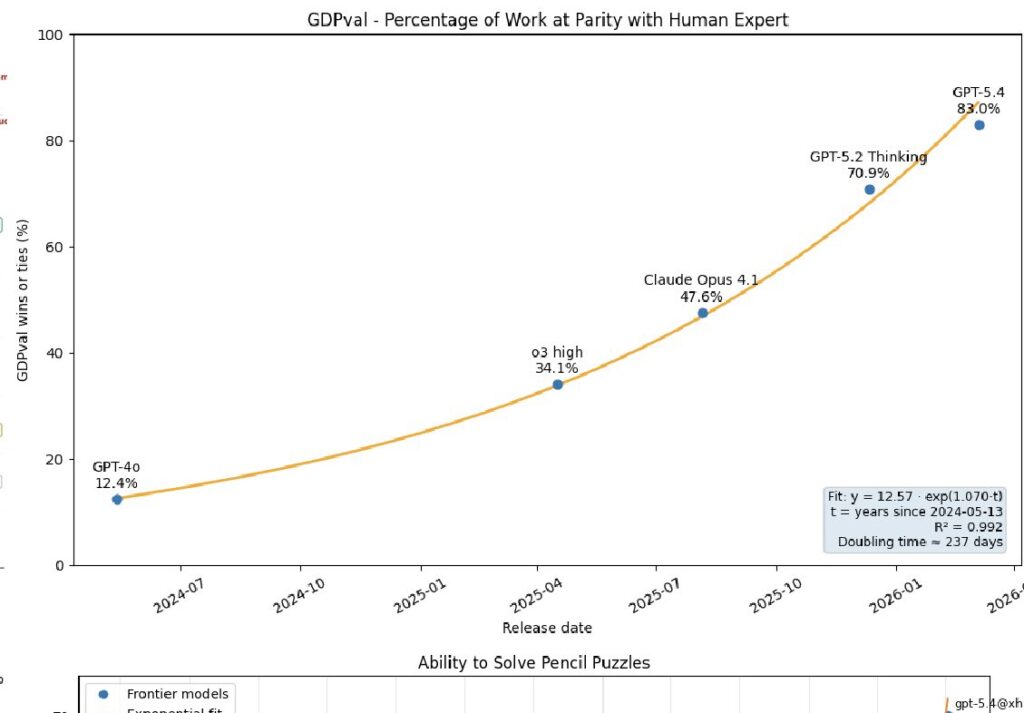
Basically every chart that attempts to benchmark real work shows exponentials. If you don’t like the METR chart the UK’s governmental assessment shows the same thing. So does GDPval. The frontier is jagged, of course, so not in every aspect of AI, but still.
-

Free online guide for running LLMs locally on all hardware
By
–
Wanna replace Anthropic/OpenAI? START WITH THIS The bible for running LLMs locally is now available online to read for free Covers what to use on – Laptop / edge / odd hardware
– Mac-first workflows
– Single RTX GPUs
– 2-4+ NVIDIA / CUDA GPUs
– General production serving
– -
Open models have better dollar per token than closed APIs
By
–
An interesting way to take Noam at his word in regards to always keeping a constant inference budget for any eval reporting –
— swyx @aiDotEngineer WF (@swyx) 27 juin 2026
is that open models have a lot more dollar per token mileage than closed model APIs. So anyone launching an open model today or situationally… https://t.co/vGl7tQZgWnAn interesting way to take Noam at his word in regards to always keeping a constant inference budget for any eval reporting – is that open models have a lot more dollar per token mileage than closed model APIs. So anyone launching an open model today or situationally
-
Debate on open vs frontier model capability gap and switching difficulty
By
–
That is probably right on where we disagree. I believe the capability delta outside of coding between open & frontier is much larger. I also am suspicious that open models will continue to stay at the frontier. I also think switching between models is harder for many tasks in