This is a nice paper, well executed! @scott_e_reed had this in mind when developing Gato https://
arxiv.org/abs/2205.06175 — I’m glad to see the idea executed with a humanoid and I’d love to see more work along this direction. Gato stood for General AgenT One. Sadly, we weren’t able to
MULTIMODAL AI
-
Paper praised for executing Gato idea with humanoid; more work desired
By
–
-
Using video to learn control representations, touch important
By
–
I think they also emerge from video. This is what I was the most excited about when helping with projects like Veo. My intent was never to create slop videos, but rather to use video to learn representations for control. I must say however that touch is super important and highly
-

GPT Image 2 Edit used to improve orders, offering replacements
By
–


Okay inputted that one and made a new one with GPT Image 2 Edit, if anyone who ordered likes this better, let me know and I'll replace your order 😀 x.com/levelsio/statu…
-
World Labs improves at large open sky scenes
By
–
Nice, world labs is getting good at large open sky scenes!
-
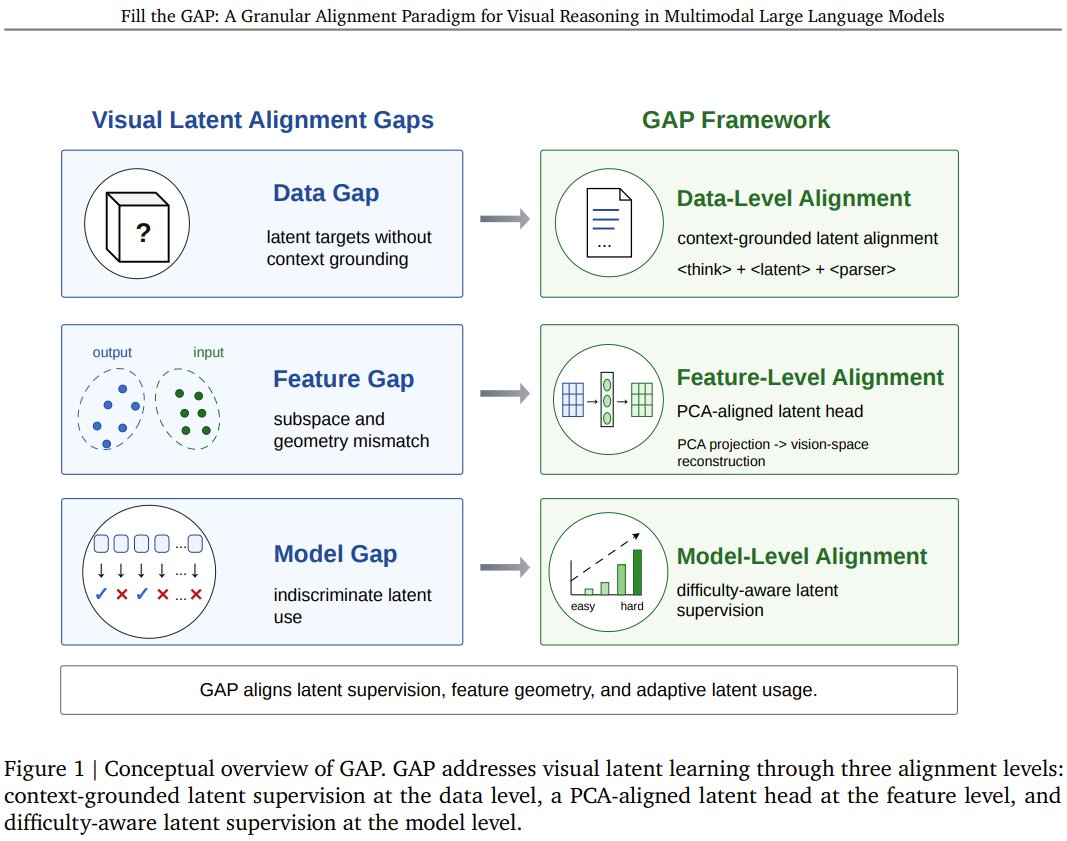
GAP fixes hidden mismatch in multimodal AI visual evidence generation
By
–
Why do multimodal AI models struggle to “think” visually without external tools? Alibaba, University of Waterloo, and the Vector Institute present GAP—a new method that fixes a hidden mismatch in how models generate internal visual evidence. Instead of feeding raw decoder
-
Streaming 3D reconstruction from single camera, real-time, open-source
By
–
🚨 Forget LIDAR.
— Charly Wargnier (@DataChaz) 27 juin 2026
The Robbyant team just dropped a streaming 3D model that reconstructs scenes live, at ~20 FPS, over long sequences.
One single camera. Runs in real time. Open-source.
Entirely end-to-end.
NO iterative optimization tricks and no post-processing cleanup steps!… pic.twitter.com/zo8GuGQYdIForget LIDAR. The Robbyant team just dropped a streaming 3D model that reconstructs scenes live, at ~20 FPS, over long sequences. One single camera. Runs in real time. Open-source. Entirely end-to-end. NO iterative optimization tricks and no post-processing cleanup steps!
-

Baton: AI Framework for Joint Video-Audio Generation
By
–
What if AI could plan video and audio together before generating? Researchers from Fudan University and Tencent Hunyuan present Baton, a new framework that creates shared semantic blueprints for joint video-audio generation. Instead of relying on coarse text prompts, Baton
-

AI cannot yet generate skill-teaching videos, says KIVI benchmark
By
–
Can AI generate videos that actually teach you a skill or explain a concept? Fudan University and Shanghai Jiao Tong University researchers say not yet. They introduce KIVI, a benchmark that tests video generation on factual, information-seeking prompts—like procedures or
-
Describing vs directing: video models revolutionize camera movement
By
–
“This is the difference between describing a shot and directing one.”
— Bilawal Sidhu (@bilawalsidhu) 26 juin 2026
Video models are getting so good that people are finally getting 3d pilled
Way more fun to grab a phone and record the exact camera move you want vs. endlessly hitting the slot machine pic.twitter.com/wQRT2wsyLn“This is the difference between describing a shot and directing one.” models are getting so good that people are finally getting 3d pilled Way more fun to grab a phone and record the exact camera move you want vs. endlessly hitting the slot machine
-
Senya turns any song into ASL performance using Pika stitching
By
–
3. Senya: Turns any song into an ASL performance, using Pika to stitch and transform real signing clips into a music video that maintains both the accuracy of the lyrics and the original energy of the song.
— Pika (@pika_labs) 26 juin 2026
Team: Tejas Mundhe, Nithila Sadheesh, Deeksha Vaidyanathan pic.twitter.com/KqJjalzeRP3. Senya: Turns any song into an ASL performance, using Pika to stitch and transform real signing clips into a music video that maintains both the accuracy of the lyrics and the original energy of the song. Team: Tejas Mundhe, Nithila Sadheesh, Deeksha Vaidyanathan