Two quick updates in image world. Try adding –preview to your prompt for a early peak at V8.2 aesthetics & personalization. We've also updated our big batch draft mode to work with –sref random so you can explore style space 24x faster than before. Enjoy!
MULTIMODAL AI
-
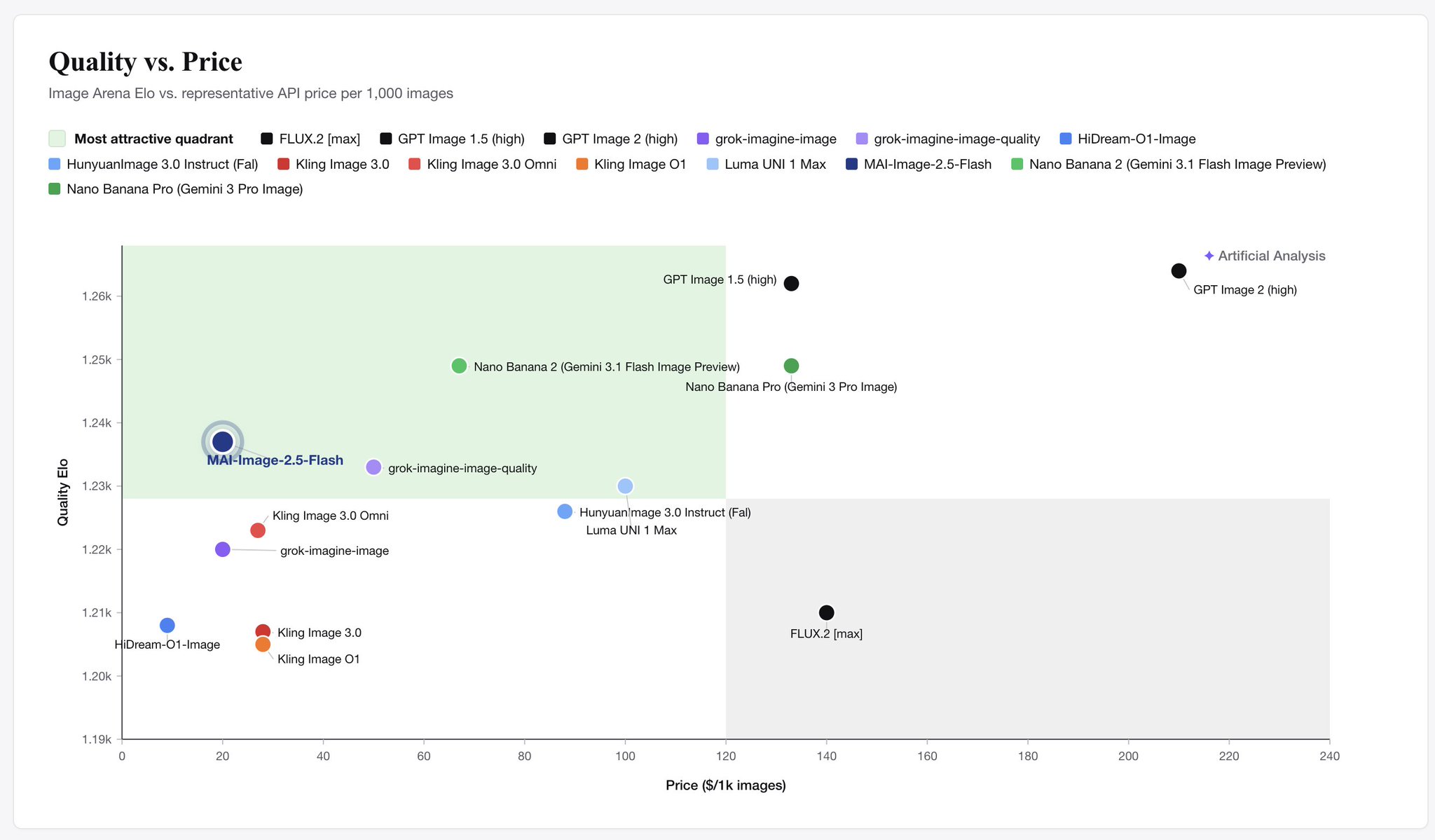
MAI-image-2.5 ranks #2 text-to-image, #3 editing; Flash best quality/price
By
–
MAI-image-2.5 is new at #2 for text-to-image and #3 for image editing on @ArtificialAnlys
! We’re second now only to GPT models. Also, MAI-Image-2.5-Flash is world-beating for quality/price. Super proud of the team. Now available through the Foundry API and rolling out across -
DomainShuttle: Freeform Open Domain Subject-driven Text-to-Video
By
–
DomainShuttle
— AK (@_akhaliq) 25 juin 2026
Freeform Open Domain Subject-driven Text-to-video Generation pic.twitter.com/QC9jYvfnnQDomainShuttle Freeform Open Domain Subject-driven Text-to-video Generation
-
Genspark Design: AI Tool Creates Production-Ready Assets from Ideas
By
–
-
Conversational video editing with Google Gemini Omni explained
By
–
I explored exactly how this works in my latest video. If you want to see conversational video editing in action, check it out here. Built with @Google
's Gemini Omni. What part of your content workflow would you automate first? Don't miss out on the latest AI advancements! -

Rapid evolution of AI image generation in under 5 years
By
–


State of the art in AI image generation less than 5 years ago.
-
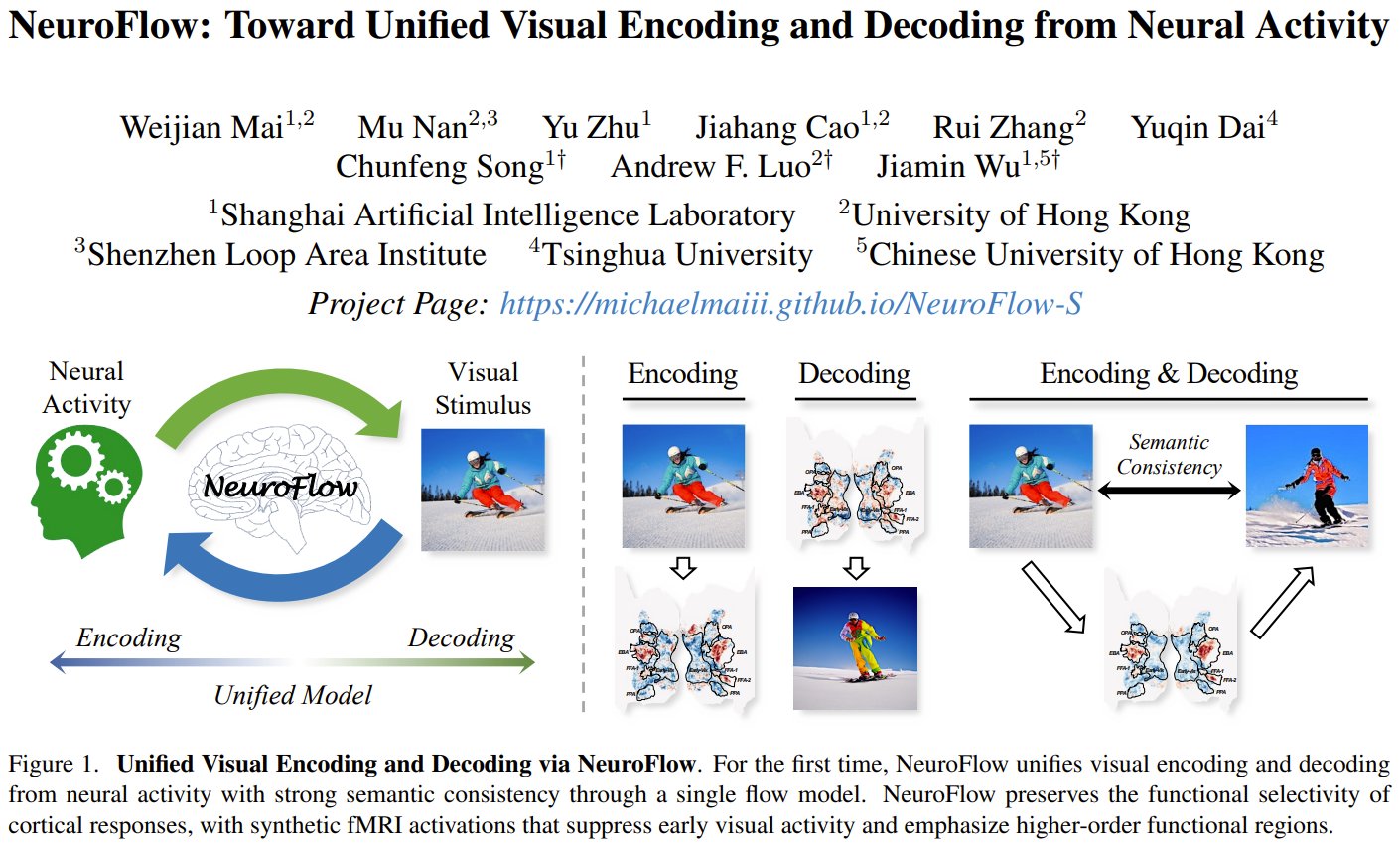
NeuroFlow: Unified AI for Brain Encoding and Image Reconstruction
By
–
What if a single AI model could both predict your brain activity from what you see AND reconstruct the image from your brain scans? Researchers from Shanghai AI Lab, HKU, and Tsinghua University present NeuroFlow — the first unified framework that treats visual encoding and
-

Text-to-Image Generator from Scratch with Transformers and Diffusions
By
–
Build a Text-to-Image Generator (from Scratch), with transformers and diffusions: http://
amzn.to/3MFbyK4 by @mark_h_liu v/ @ManningBooks -
Asking which model created her perfect appearance
By
–
What model did you use to create her? She looks so perfect.
-
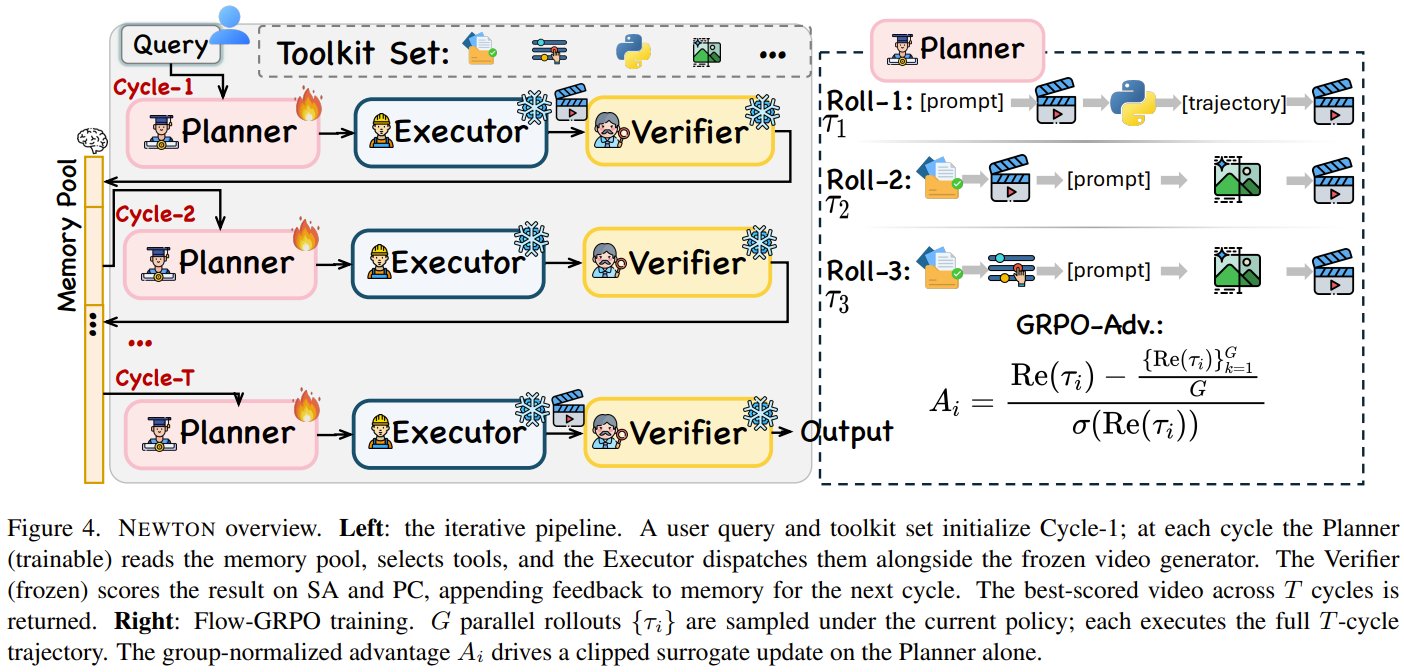
AI agent NEWTON uses keyframes and simulators to enforce physics
By
–
Why do AI-generated videos keep breaking the laws of physics? Researchers from Zhejiang University, HK PolyU, and IROOTECH present NEWTON. Instead of fixing the video generator, they built an AI agent that plans physics using tools like keyframes and scientific simulators—then