Annoying that OpenAI doesn’t seem to give a GDPval measure for GPT 5.6. One of the best measures of economically valuable work.
@emollick
-
Exponential growth confirmed by multiple AI benchmarks
By
–
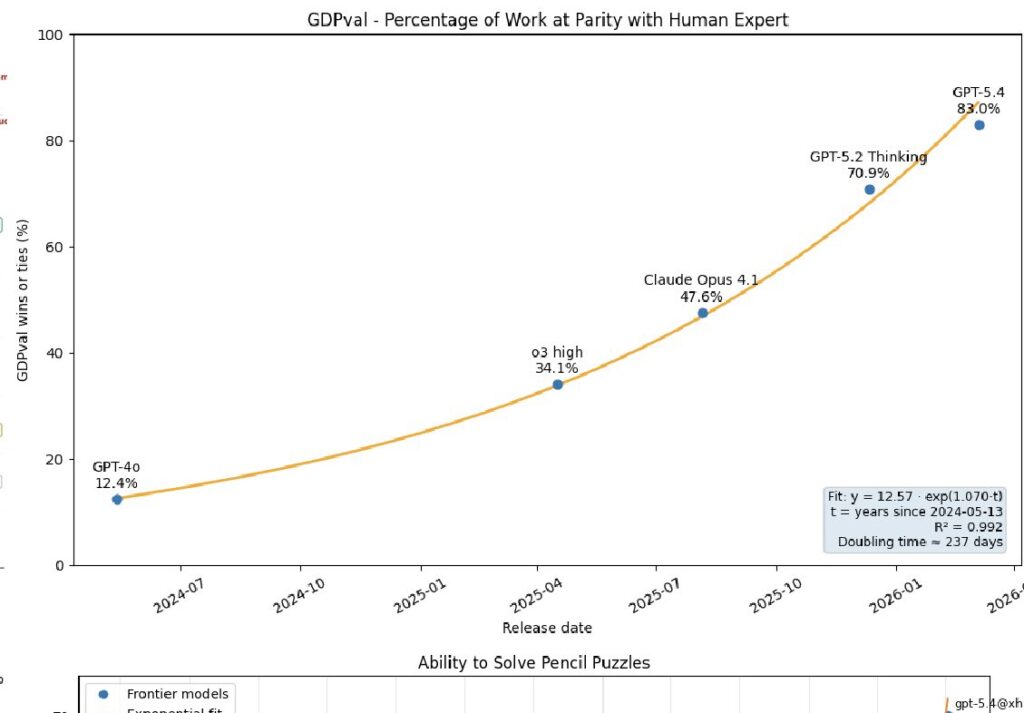
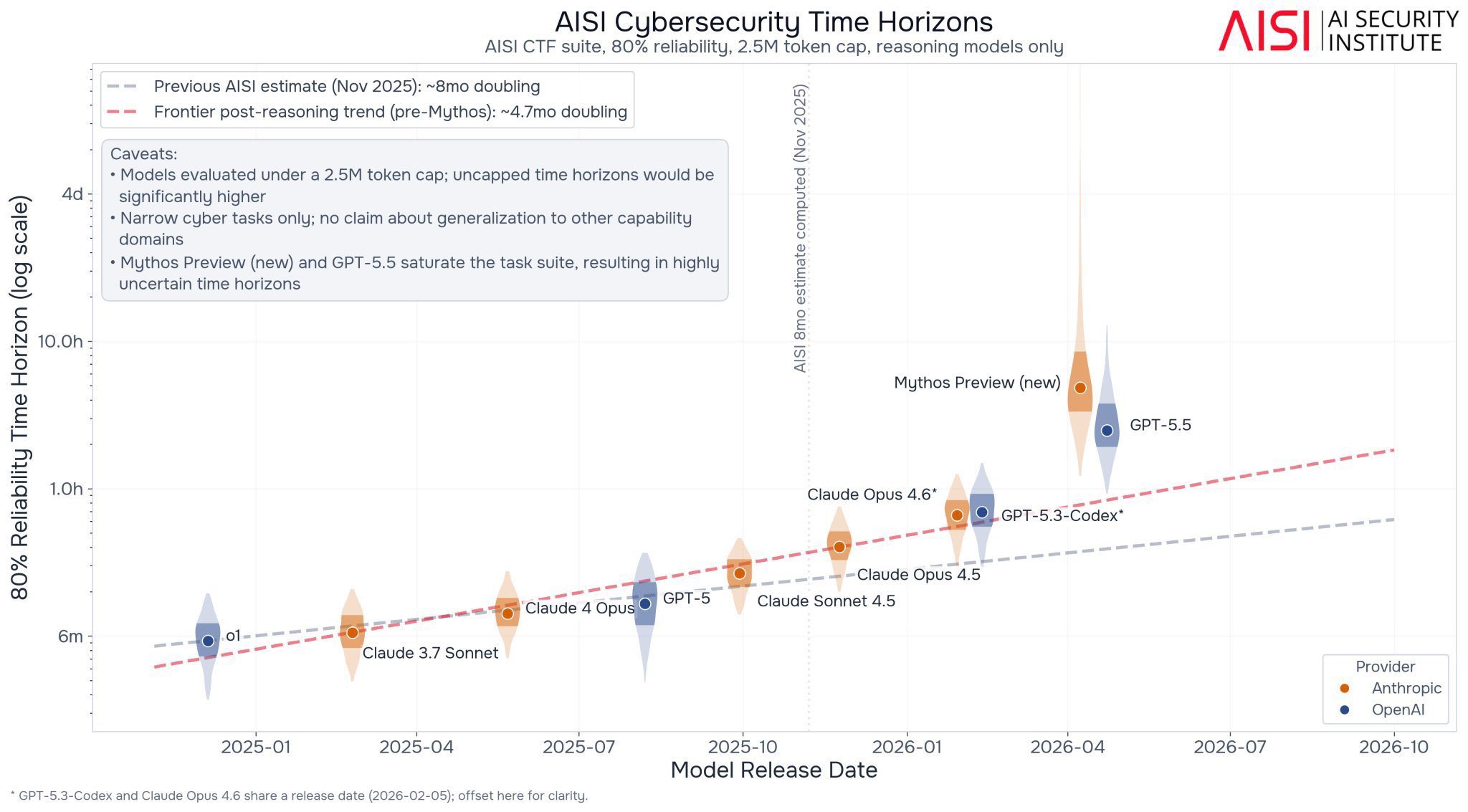
Basically every chart that attempts to benchmark real work shows exponentials. If you don’t like the METR chart the UK’s governmental assessment shows the same thing. So does GDPval. The frontier is jagged, of course, so not in every aspect of AI, but still.
-
Debate on steady-state vs exponential intelligence value
By
–
It is entirely possible that the steady-state people will prove to be right in the future, but there's no sign of a slowdown yet. And if greater intelligence brings greater value at an exponential pace (which it has, but may not always) then it matters a lot which world we're in.
-
Growing division between exponential and steady-state AI beliefs
By
–
A thing I am noticing is the number of folks who believe AI is “real” is larger, but now there is a growing division between people who know that we are on an exponential & those whose mental model is that we are at a sort of steady state. The difference leads to misunderstanding
-
Debate on open vs frontier model capability gap and switching difficulty
By
–
That is probably right on where we disagree. I believe the capability delta outside of coding between open & frontier is much larger. I also am suspicious that open models will continue to stay at the frontier. I also think switching between models is harder for many tasks in
-
Open weights models debate – request for persuasive project links
By
–
I talk to lots of people in the open weights space, including some of the key players. I use open weights models, I think I just disagree with you (in part because I care a log about non-coding uses). Feel free to send a link to the project/idea that might persuade me otherwise
-
Open source importance vs closed frontier models lead
By
–
I think open source is important (it was literally the subject of a bunch of my pre-AI academic research). I also think that closed frontier models have a current lead with sustaining forces for now. And that more intelligent models can do more. Not sure we disagree on that much.
-
More companies falling behind frontier models, early RSI acceleration
By
–
More companies are falling behind the frontier than keeping up with it (Mistral, Grok, etc.) & we are in the era of early RSI where there is acceleration. I haven’t seen any evidence of sudden frontier models emerging, but interested in seeing what you are hinting at.
-
Fragility of frontier open weights model releases
By
–
And the idea that frontier open weights models will continue to be released was fragile even before the current de facto licensing regime.
-
Open source harness advances depend on model intelligence from few firms
By
–
Lots of advances coming from the open source harness movement (including Moltbook, RAG approaches back in the day, etc.) but they depend on the intelligence of the models created by a small handful of companies & the more intelligent those models, the more others can do with them