Wanna replace Anthropic/OpenAI? START WITH THIS The bible for running LLMs locally is now available online to read for free Covers what to use on – Laptop / edge / odd hardware
– Mac-first workflows
– Single RTX GPUs
– 2-4+ NVIDIA / CUDA GPUs
– General production serving
–
COMPUTING
-

Free online guide for running LLMs locally on all hardware
By
–
-
Every enterprise will have its own model-harness-sandbox-eval flywheel
By
–
Every enterprise will have its own model-harness-sandbox-eval flywheel with token value per watt optimization. This is the future. Simple reason: tacit knowledge about the domain and customers and their workflows that the company uniquely understands and has built trust around.
-

NVIDIA SOLAR automates speed-of-light performance analysis from PyTorch/JAX
By
–
NEW paper from NVIDIA. (bookmark it) Speed-of-light performance analysis tells you the theoretical floor of a workload, but teams still derive it by hand and freeze it. SOLAR automates the whole thing straight from PyTorch or JAX source. An LLM frontend translates arbitrary
-
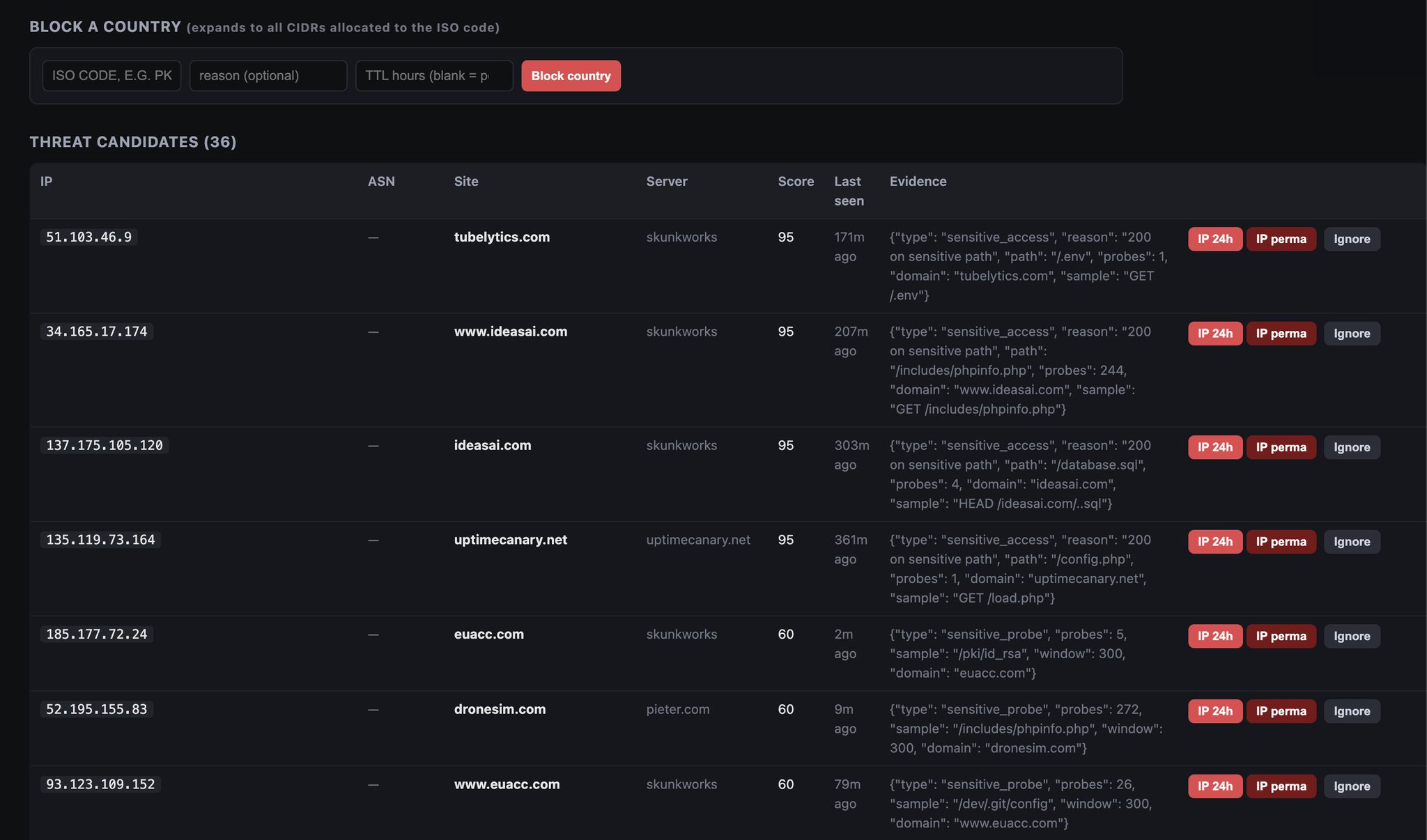
Pietflare: A DDOS and probe detector with AI central block list
By
–
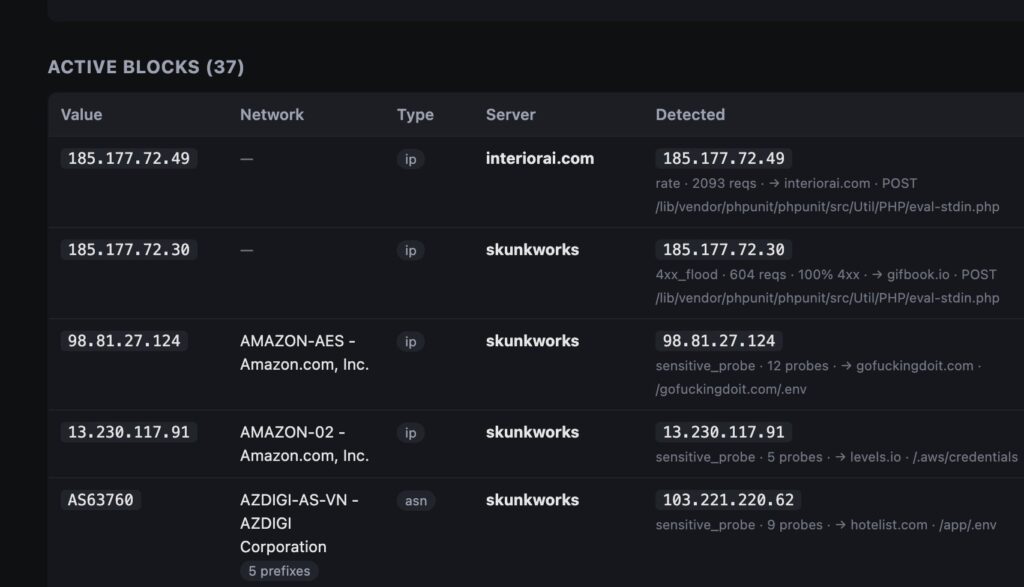
I made my own little Cloudflare called Pietflare, it's a DDOS and probe detector with AI and with a central IP / ASN / country block list Each server (VPS) sends suspicious probes, or DDOS attempts etc, from the access logs to the central admin and each server pulls a central
-
LMCache offloads KV cache to CPU, disk, or S3 instead of evicting
By
–
Compression is one way to fight the KV cache wall. The other is to not throw the KV away. LMCache reuses and offloads it to CPU, disk, or S3 instead of evicting. Already plugs into vLLM, SGLang, and NVIDIA Dynamo. Worth a star if you serve LLMs.
-
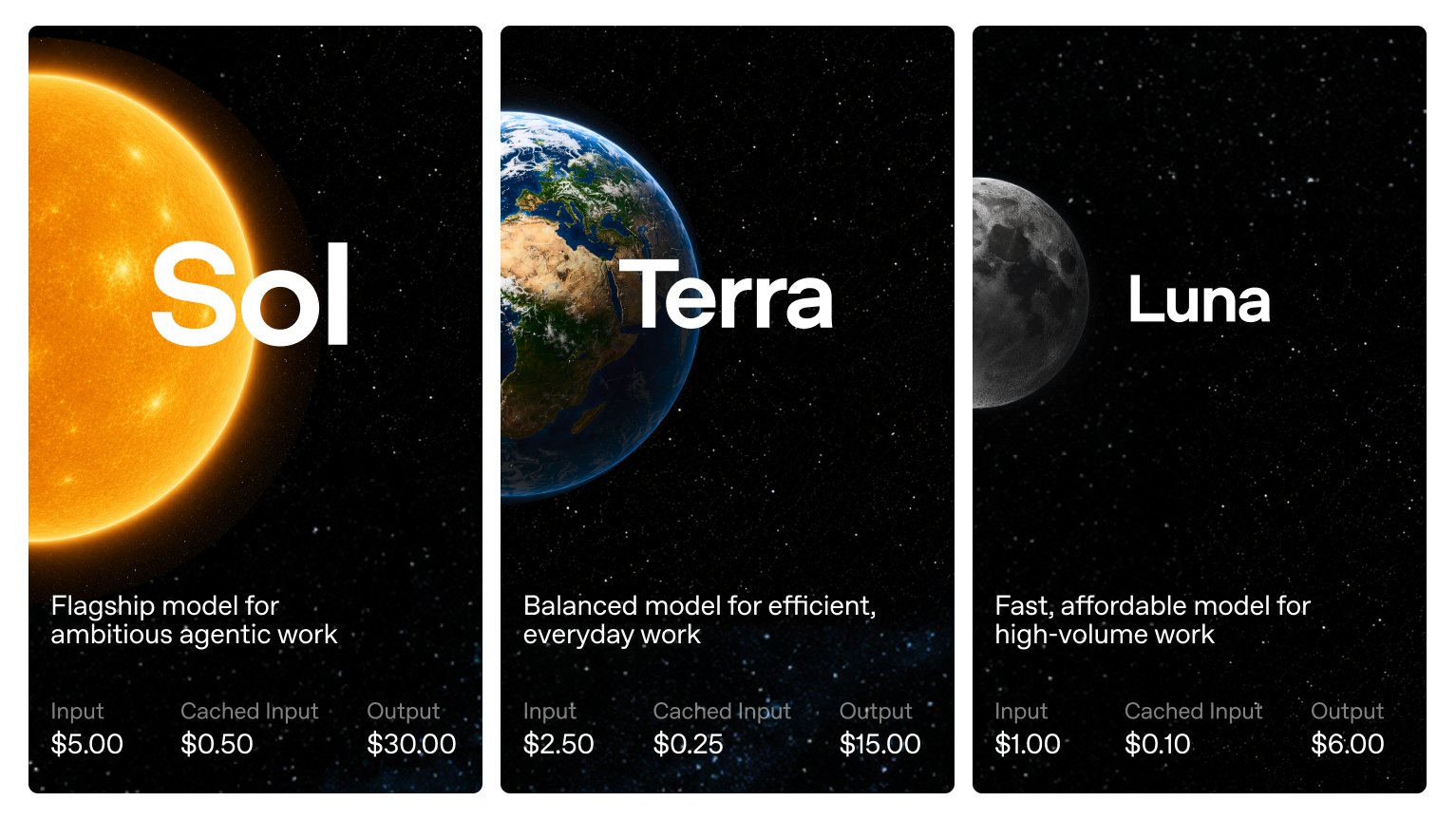
GPT-5.6 ships in three capability tiers, Sol is flagship
By
–
@OpenAI just turned the frontier into a choice.
Instead of one model, GPT-5.6 ships as three capability tiers: Sol — the new flagship. Sets a state of the art on Terminal-Bench 2.1 (complex command-line, multi-step agent work) and is OpenAI's most capable model yet for -
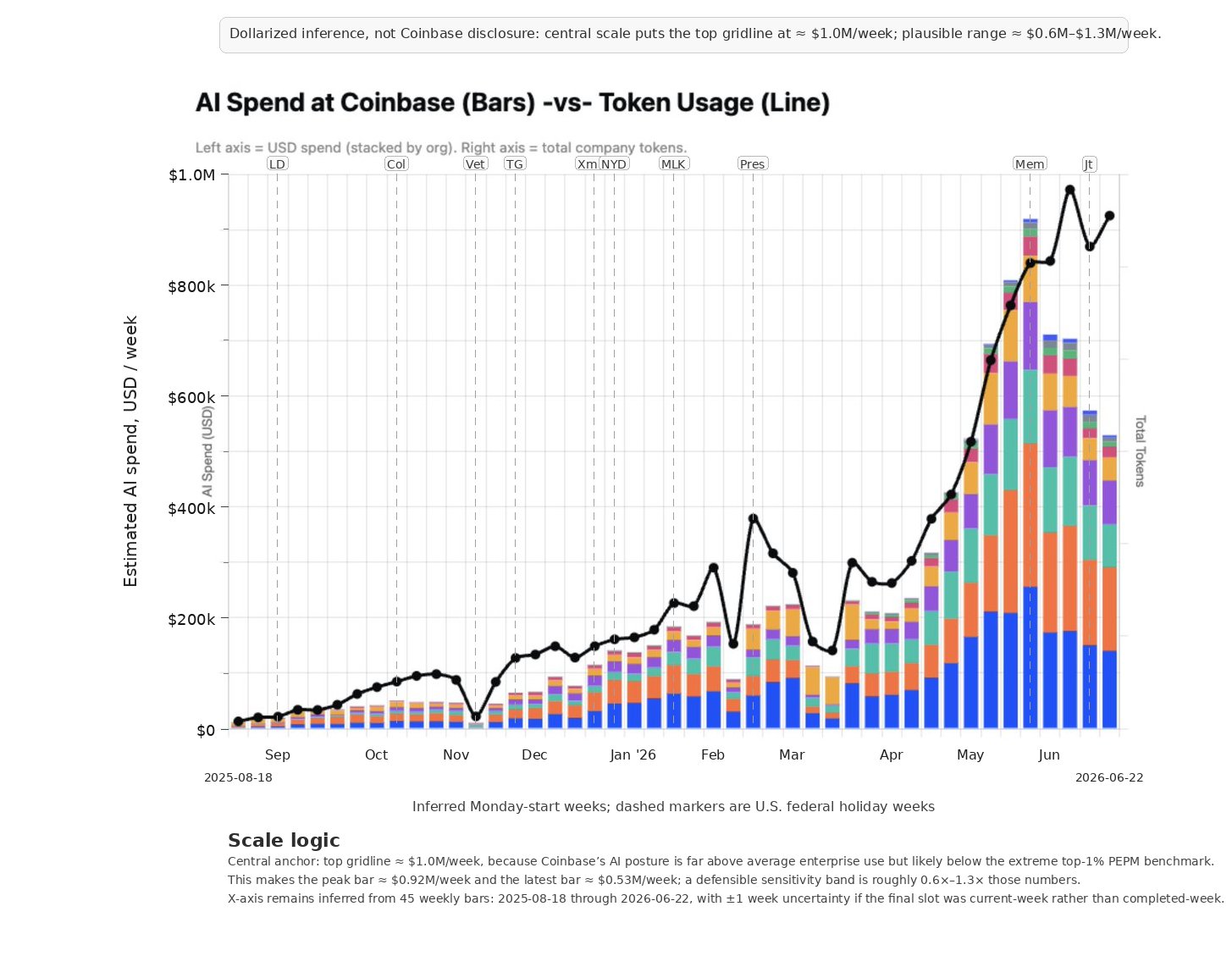
GPT-5.5-Pro vs Y axis: triangulating spend at $500k/week
By
–
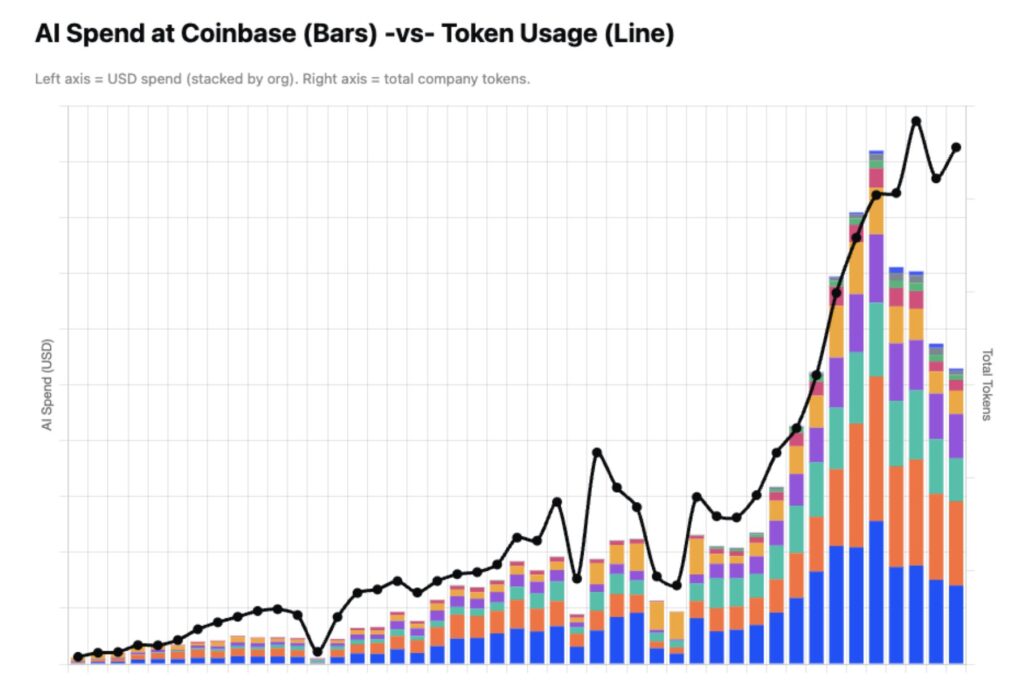
Next in the series of GPT-5.5-Pro vs the Y axis, where we try to triangulate information to add the missing axes. Explanation:
"I anchored the top of the chart at roughly $1M/week because that makes the latest spend about $500k/week, or ~$500 per employee per month for -
How open source and local AI can defeat Microsoft
By
–
Except that we can make Opensource and Local AI win. Anthropic isn’t Google, it’s Microsoft , and Microsoft was beaten; they even ship Linux now.
-
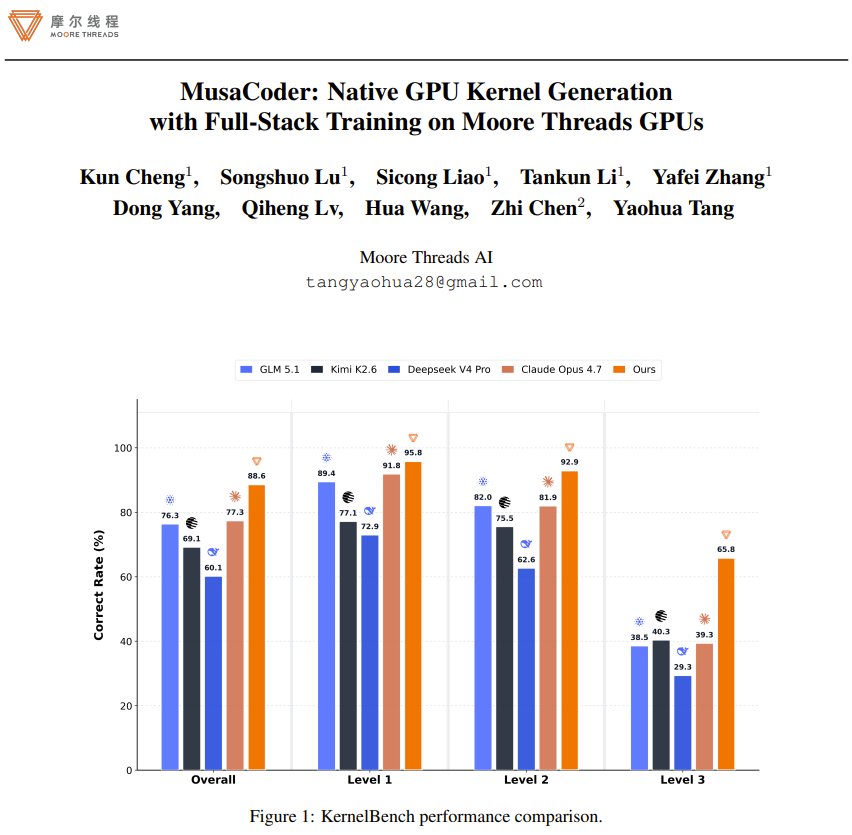
MusaCoder: AI framework for generating efficient GPU kernels
By
–
Can AI write efficient GPU code from scratch? Moore Threads AI presents MusaCoder, a full-stack training framework for native GPU kernel generation. It combines progressive data synthesis, rejection fine-tuning, and execution-feedback reinforcement learning. To stabilize
-

AI Agent Tech Stack Explained with Key Technologies and Tools
By
–
The AI Agent Tech Stack Explained! #BigData #Analytics #DataScience #AI #MachineLearning #NLProc #LLM #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode