
AI is most impactful when it's tailored to the way teams already work. Discover how Zaha Hadid Architects uses local compute, fine-tuned AI models, and NVIDIA technologies to build custom AI tools that accelerate design while keeping proprietary data secure.
COMPUTING
-
Offline voice assistant on tiny Axelera AI Mini PC
By
–
A full voice assistant, running with no internet connection at all, on a tiny, self-contained device you can put anywhere. This is the new Axelera AI Mini PC running Llama 3.2 1B as the language model, with separate speech-to-text and text-to-speech models alongside it, all on… pic.twitter.com/MUXkSdlJ7P
— Axelera AI (@AxeleraAI) 26 juin 2026A full voice assistant, running with no internet connection at all, on a tiny, self-contained device you can put anywhere. This is the new Axelera AI Mini PC running Llama 3.2 1B as the language model, with separate speech-to-text and text-to-speech models alongside it, all on
-
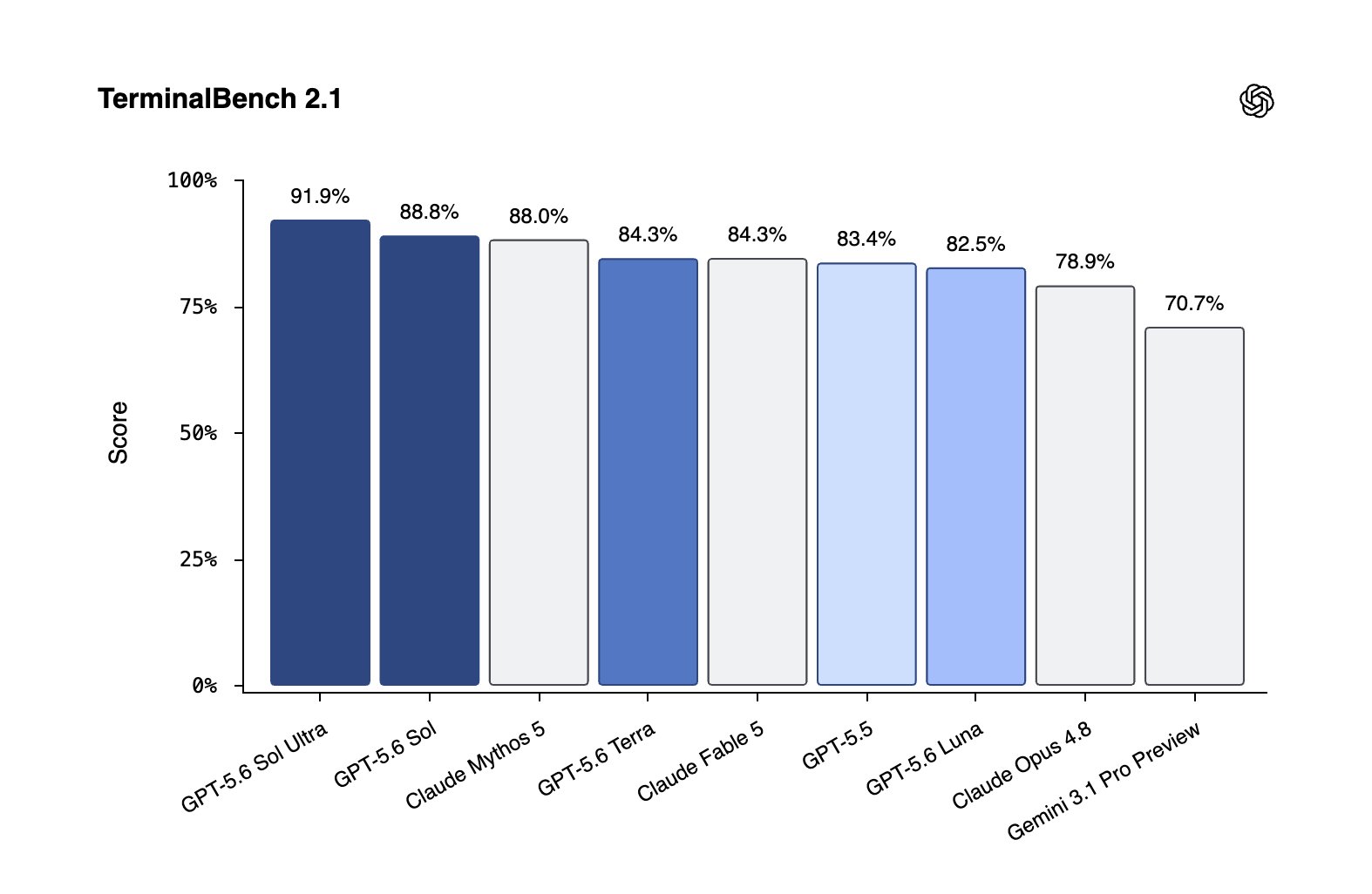
GPT-5.6 Sol sets new state-of-the-art on Terminal-Bench 2.1
By
–
GPT‑5.6 Sol sets a new state of the art on Terminal‑Bench 2.1, which tests complex command-line workflows requiring planning, iteration, and tool coordination.
-
108 real-world computer-use workflows: 20.6% agent completion
By
–
108 real-world, long-horizon computer-use workflows. Average rollout: 318 tool calls.
— Snorkel AI (@SnorkelAI) 26 juin 2026
Top frontier agent (Claude Opus 4.8 with max thinking + batched tool calls): 20.6% end-to-end completion (54.8% partial progress). Partial progress is real. Reliable end-to-end computer use is… https://t.co/aK42mNsHdx108 real-world, long-horizon computer-use workflows. Average rollout: 318 tool calls. Top frontier agent (Claude Opus 4.8 with max thinking + batched tool calls): 20.6% end-to-end completion (54.8% partial progress). Partial progress is real. Reliable end-to-end computer use is
-
Heterogeneous disaggregated inference is the future of AI
By
–
Training builds models. Inference builds businesses. At @deeptechweek SF, our Chief Product & Strategy Officer Abhi Ingle shared why heterogeneous, disaggregated inference is the future of AI, and why "more intelligence per joule" is the metric that matters. @LipBuTan1
-
HyperExtract: LLM framework converting unstructured text to knowledge
By
–
/4 HyperExtract turns messy documents into actual knowledge systems. It is an LLM-powered framework for converting unstructured text into strongly typed Knowledge Abstracts. It can extract simple lists, Pydantic models, knowledge graphs, hypergraphs, and spatio-temporal graphs.
-
Lack of compute forces AI researchers to relocate
By
–
If you can't get compute, you can't build AI. And if you're a researcher who can't build AI, you go somewhere where you can get compute so you can build it. https://t.co/pjHacwzm0C
— Robert Scoble (@Scobleizer) 26 juin 2026If you can't get compute, you can't build AI. And if you're a researcher who can't build AI, you go somewhere where you can get compute so you can build it.
-
RMUX: True multiplexer for agent-based workflows with dynamic panes
By
–
3/ because RMUX is a true multiplexer first, you aren't just launching a fragile web wrapper. You get a real environment perfectly designed for modern, agent-based workflows. → Safely inspect long-running AI shells
→ Resize splits and manage panes dynamically
→ Share -

Loop Engineering: Building Systems That Prompt Agents Instead
By
–
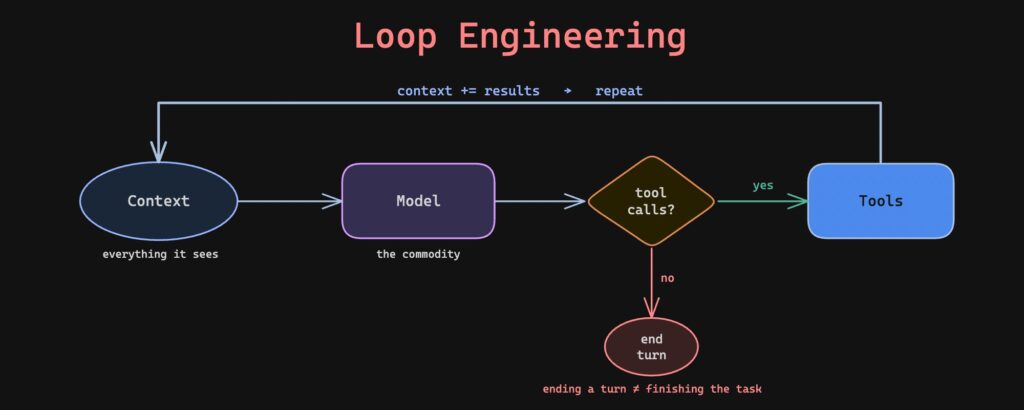
A SENIOR ANTHROPIC ENGINEER JUST DROPPED AN 11-PAGE PDF ON LOOP ENGINEERING. The core shift: stop prompting the agent. Build the system that prompts it. Inside the autonomous loop: – Discover → Finds its own work (failing CI, open issues).
– Isolate → Uses separate git -
Hunt an RTX 3090 to run Qwen 3.5 27B now
By
–
I am not kidding, now is the time more than ever to hunt an RTX 3090 and learn how to run Qwen 3.5 27B