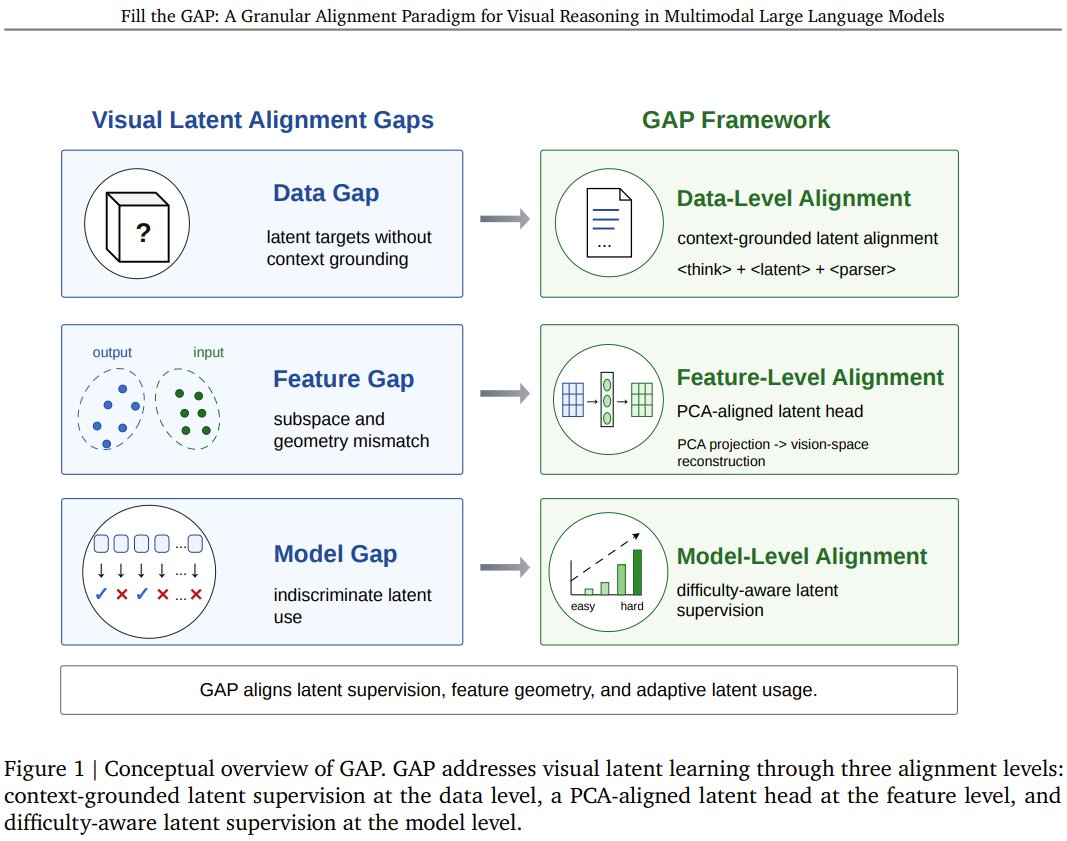
Why do multimodal AI models struggle to “think” visually without external tools? Alibaba, University of Waterloo, and the Vector Institute present GAP—a new method that fixes a hidden mismatch in how models generate internal visual evidence. Instead of feeding raw decoder
@jiqizhixin
-

AgentSociety2 lets AI be social scientist and test subjects
By
–
What if AI could run entire social science experiments from hypothesis to manuscript—while also being the test subjects? Tsinghua University researchers present AgentSociety2: an Integrated Research Environment that lets LLM agents play both roles—AI social scientists designing
-

Baton: AI Framework for Joint Video-Audio Generation
By
–
What if AI could plan video and audio together before generating? Researchers from Fudan University and Tencent Hunyuan present Baton, a new framework that creates shared semantic blueprints for joint video-audio generation. Instead of relying on coarse text prompts, Baton
-
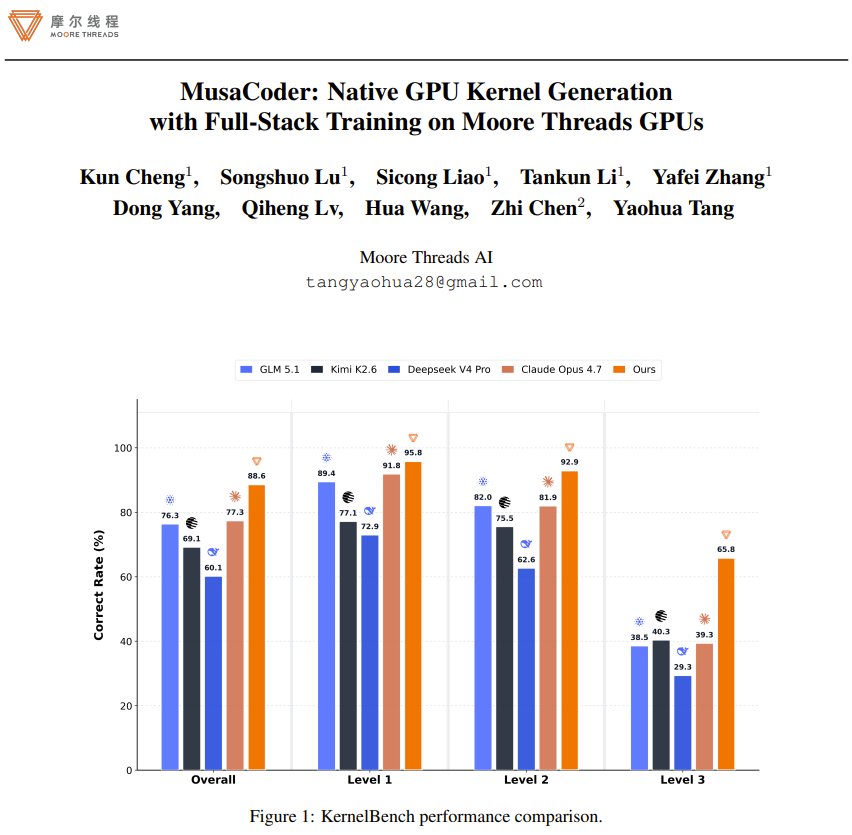
MusaCoder: AI framework for generating efficient GPU kernels
By
–
Can AI write efficient GPU code from scratch? Moore Threads AI presents MusaCoder, a full-stack training framework for native GPU kernel generation. It combines progressive data synthesis, rejection fine-tuning, and execution-feedback reinforcement learning. To stabilize
-

AI cannot yet generate skill-teaching videos, says KIVI benchmark
By
–
Can AI generate videos that actually teach you a skill or explain a concept? Fudan University and Shanghai Jiao Tong University researchers say not yet. They introduce KIVI, a benchmark that tests video generation on factual, information-seeking prompts—like procedures or
-
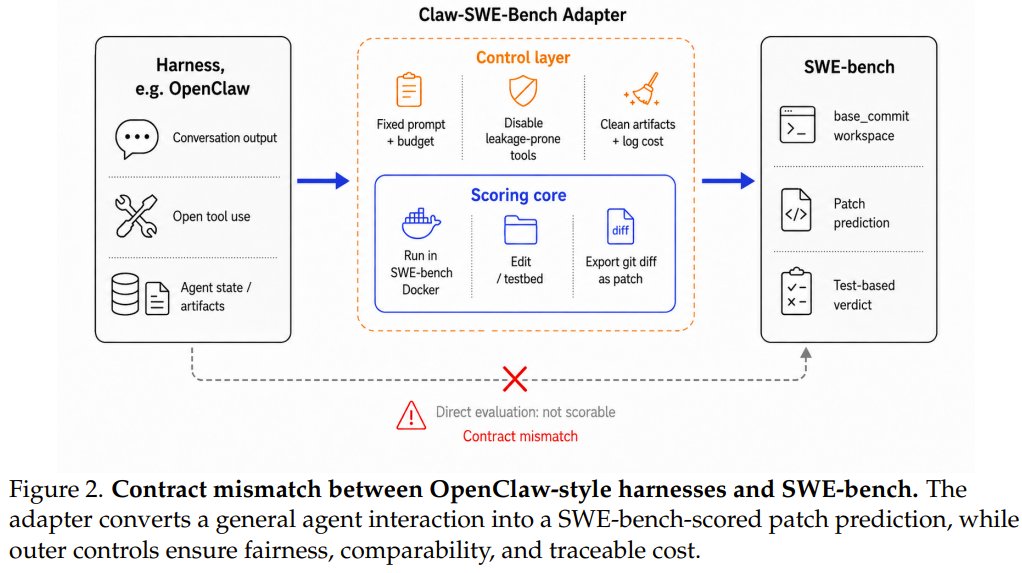
CLAW-SWE-BENCH benchmark compares coding agents on GitHub issues
By
–
Can your coding agent handle real-world GitHub issues fairly? Researchers from TokenRhythm, Infinigence AI, and eight universities introduce CLAW-SWE-BENCH—a standardized benchmark that lets you compare different coding agents (called "claws") under the same prompt, budget, and
-
Gemma 4 hits 200 million downloads
By
–
Wow, Gemma 4 just hit 200M downloads! https://t.co/x5m5KJTGGy
— 机器之心 JIQIZHIXIN (@jiqizhixin) 26 juin 2026Wow, Gemma 4 just hit 200M downloads!
-
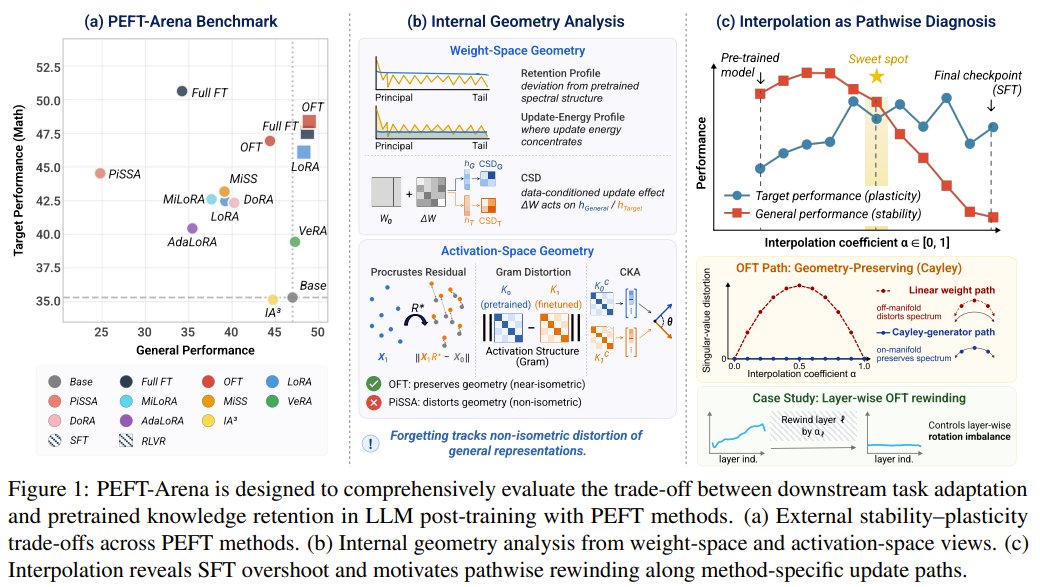
PEFT-Arena: Orthogonal Finetuning Achieves Best Retention
By
–
Can fine-tuning make a language model forget too much? A team from CUHK, Westlake University, and MPI presents PEFT-Arena – a benchmark that tracks both task performance and retention of pretrained knowledge. Their analysis finds orthogonal finetuning achieves the best
-

HumanEgo: robot learns skills from human egocentric video
By
–
Your robot could learn a new skill just by watching a few minutes of a human wearing smart glasses! University of Maryland presents HumanEgo: a framework that turns 30 minutes of human egocentric video into a zero-shot robot policy. Instead of needing robot data, it extracts
-
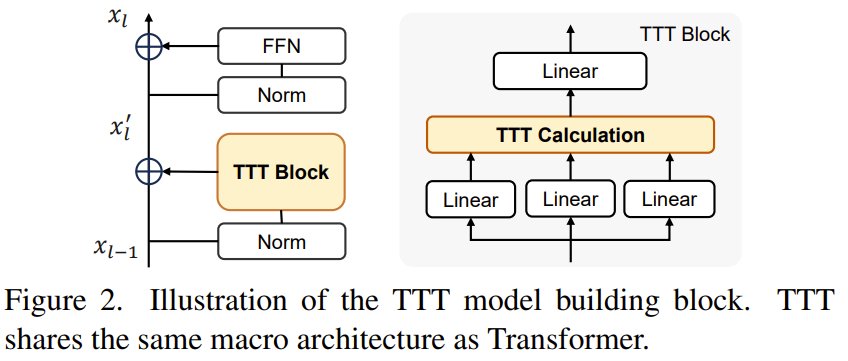
ViT³: Test-Time Training Replaces Attention with Online Learning
By
–
Why settle for attention when you can learn at test time? Tsinghua University & Alibaba Group present ViT³: a pure Test-Time Training (TTT) architecture that replaces attention with an online learning model built from key-value pairs. This inner model trains on the fly,