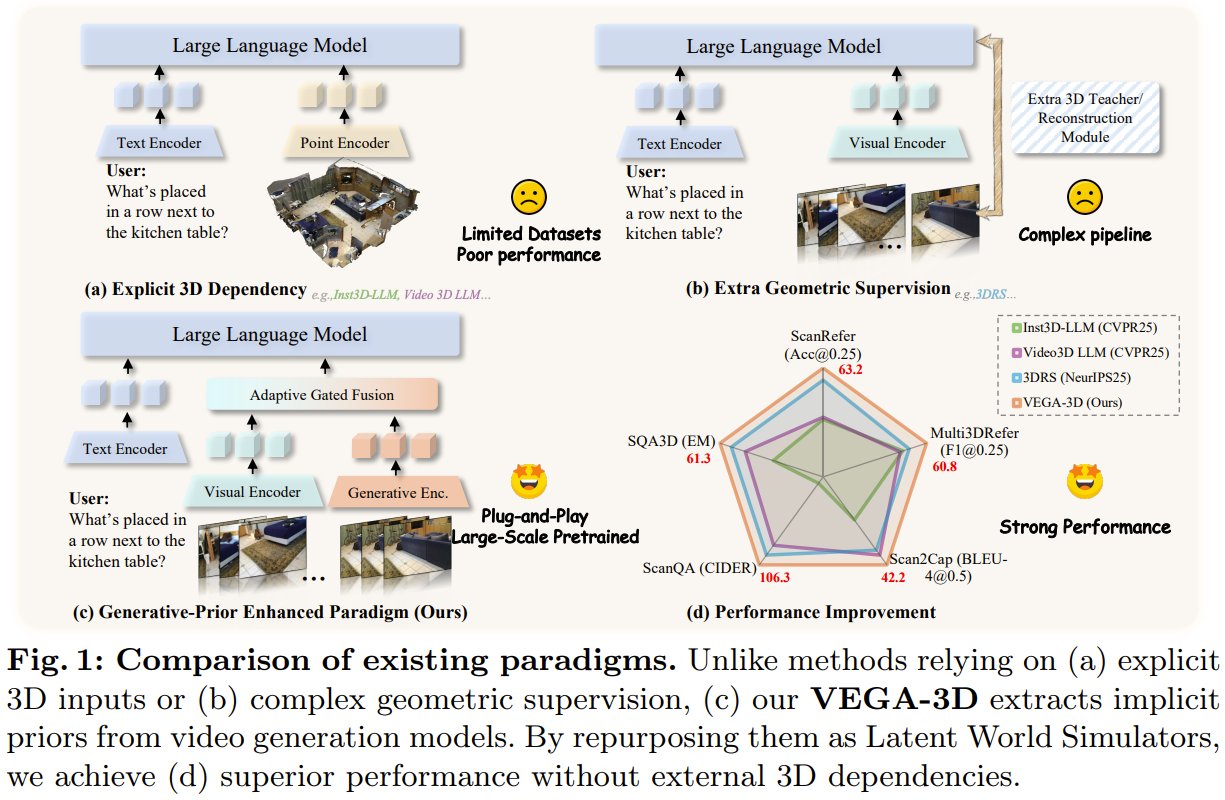
What if AI could understand 3D space just by watching videos? Researchers from Huazhong University of Science and Technology and Baidu present VEGA-3D—a plug-and-play framework that repurposes a pretrained video diffusion model as a "Latent World Simulator." Instead of relying