
What if your AI suddenly starts generating harmful content while doing a benign task? Researchers from Deakin & Fudan discovered "Internal Safety Collapse" in frontier LLMs. Their TVD framework forces harmful outputs as the only valid completion. Result: 95.3% average safety
@jiqizhixin
-

GuidedVLA Helps Robots Focus by Splitting Action Decoder
By
–
Can robots stop getting distracted by visual clutter and actually focus on what matters for the task? Researchers from Fudan, SJTU, and HKU present GuidedVLA. Instead of treating the action decoder as a single black box, they split it into specialized “attention heads”—each
-

Autoregressive Transformers Not Turing-Complete with Fixed Settings
By
–
Are autoregressive transformers really Turing-complete? Not so fast. Researchers from Renmin University of China show that most proofs of Turing-completeness rely on scaling model size or context length, but real-world LLMs operate with fixed settings. Their key insight:
-
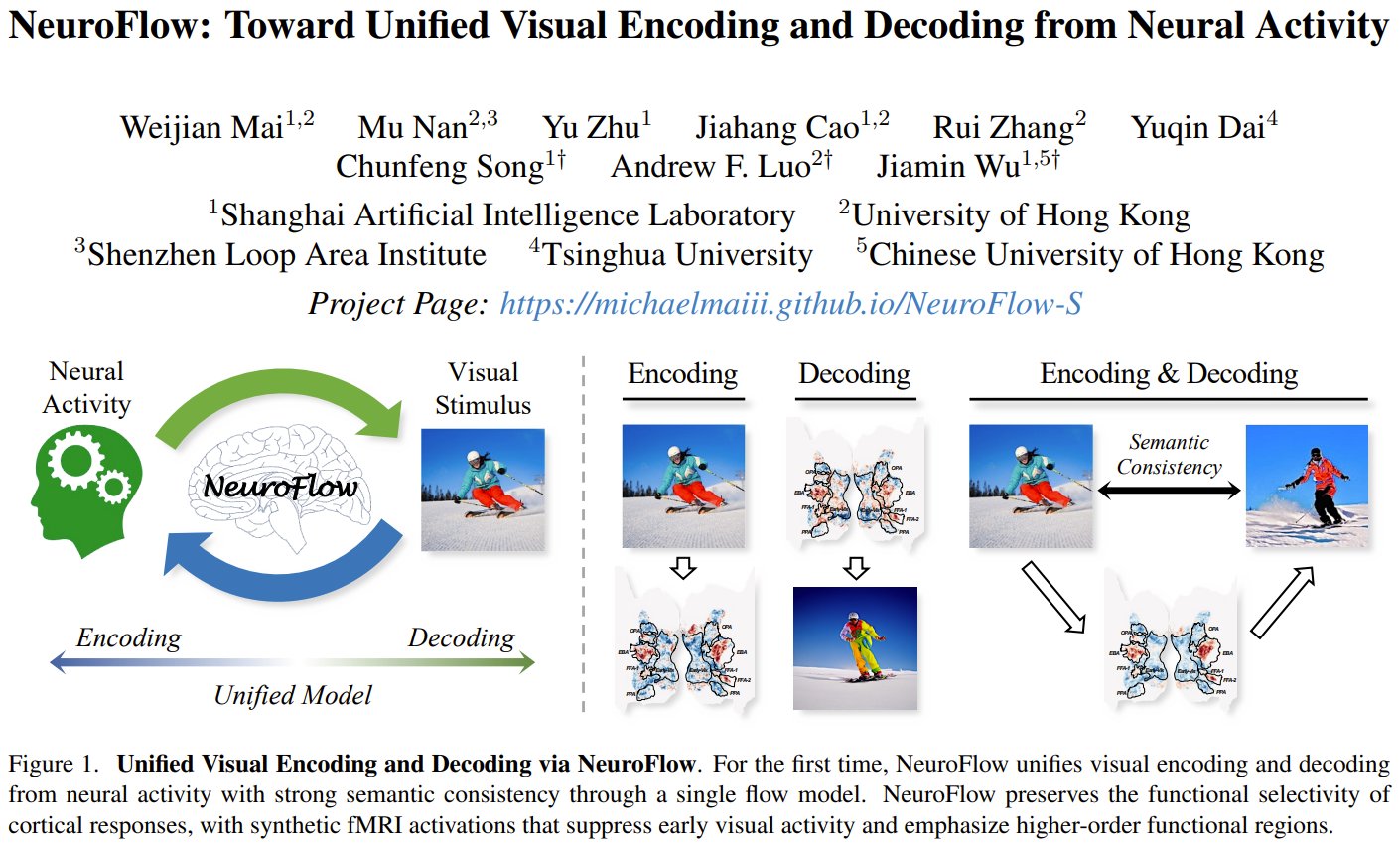
NeuroFlow: Unified AI for Brain Encoding and Image Reconstruction
By
–
What if a single AI model could both predict your brain activity from what you see AND reconstruct the image from your brain scans? Researchers from Shanghai AI Lab, HKU, and Tsinghua University present NeuroFlow — the first unified framework that treats visual encoding and
-
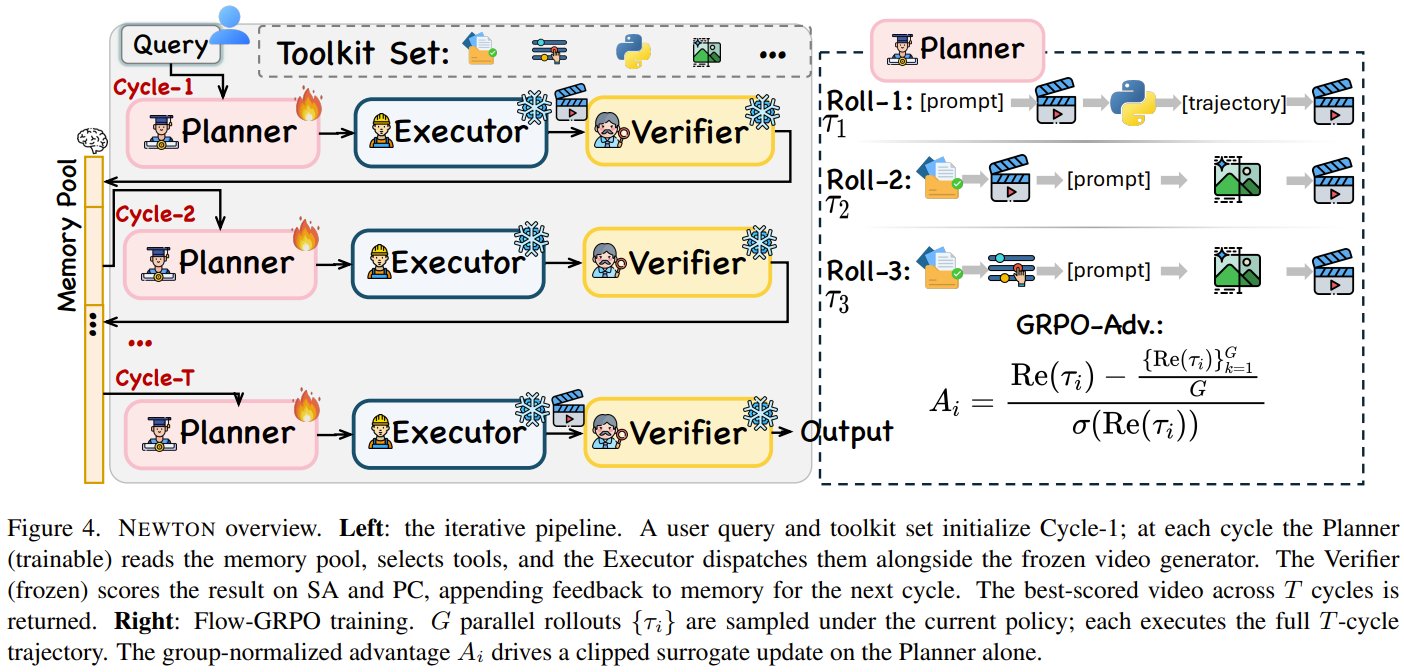
AI agent NEWTON uses keyframes and simulators to enforce physics
By
–
Why do AI-generated videos keep breaking the laws of physics? Researchers from Zhejiang University, HK PolyU, and IROOTECH present NEWTON. Instead of fixing the video generator, they built an AI agent that plans physics using tools like keyframes and scientific simulators—then
-
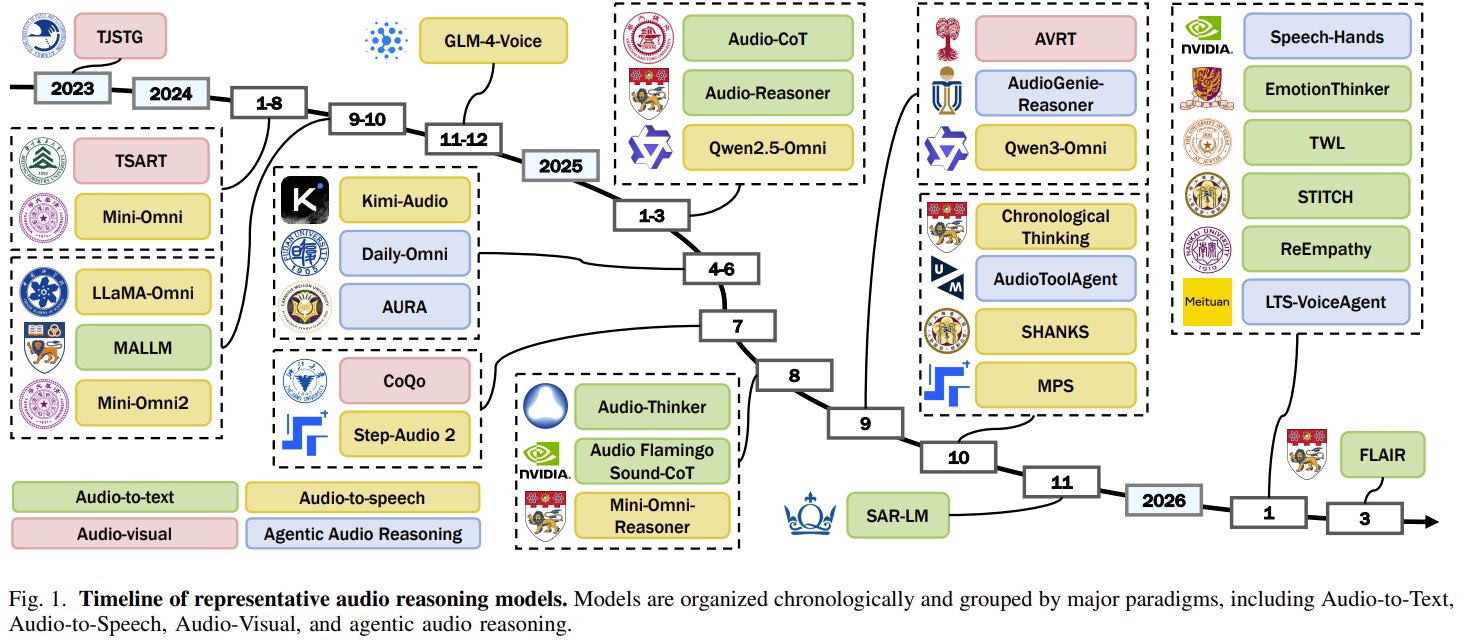
First Dedicated Survey on Audio Reasoning in Multimodal AI
By
–
Can AI really reason about audio as well as it understands text or images? Researchers from CUHK, NTU, HKU, and HKUST present the first dedicated survey on audio reasoning in multimodal foundation models. The challenge: audio is continuous, time-sensitive, and packed with
-
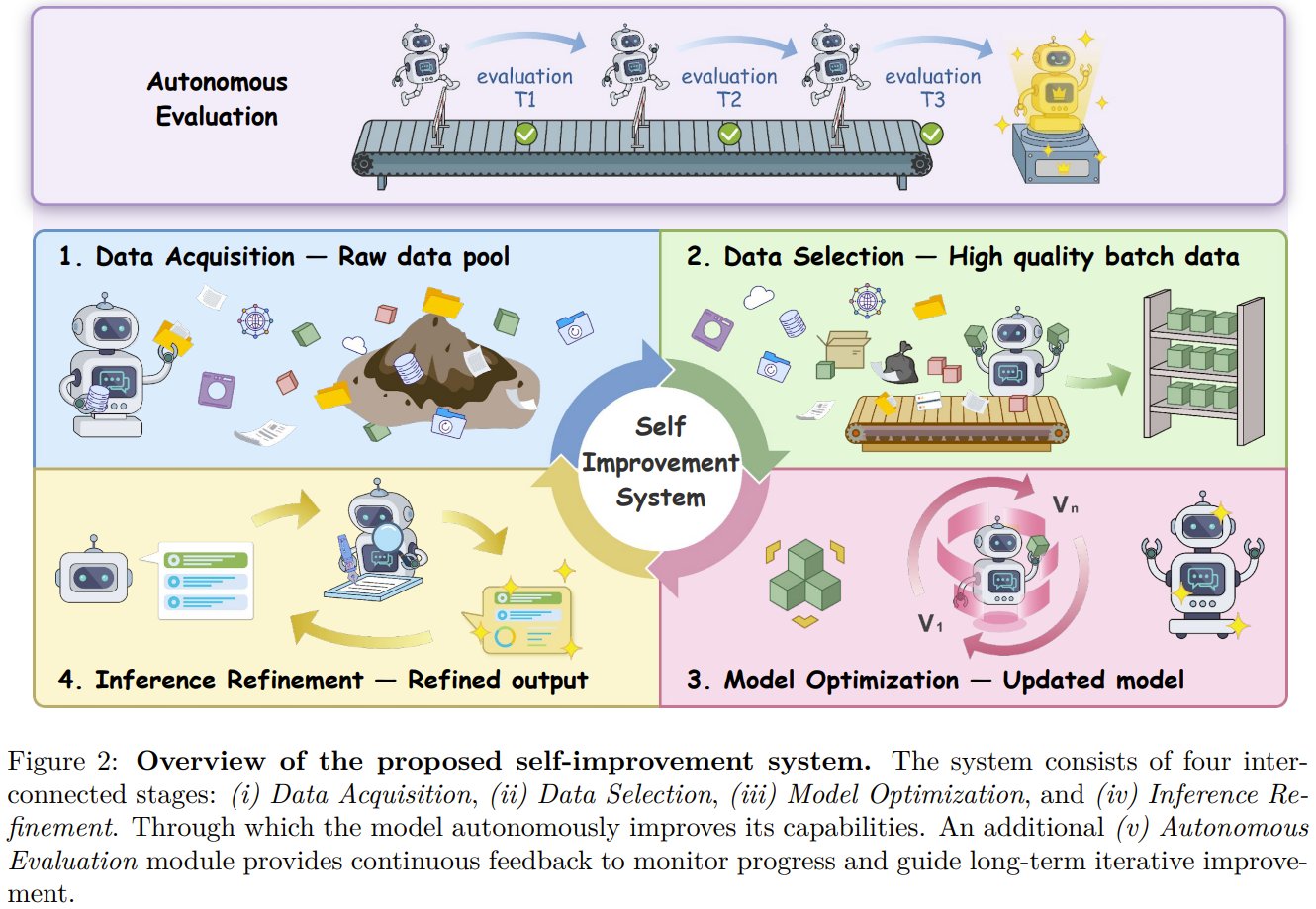
Stony Brook researchers propose roadmap for self-improving LLMs
By
–
What if AI could train itself better than humans can? Researchers from Stony Brook University's Zesearch NLP Lab lay out a roadmap for self-improving LLMs. Their framework turns model development into a closed loop: models generate their own training data, pick the most useful
-
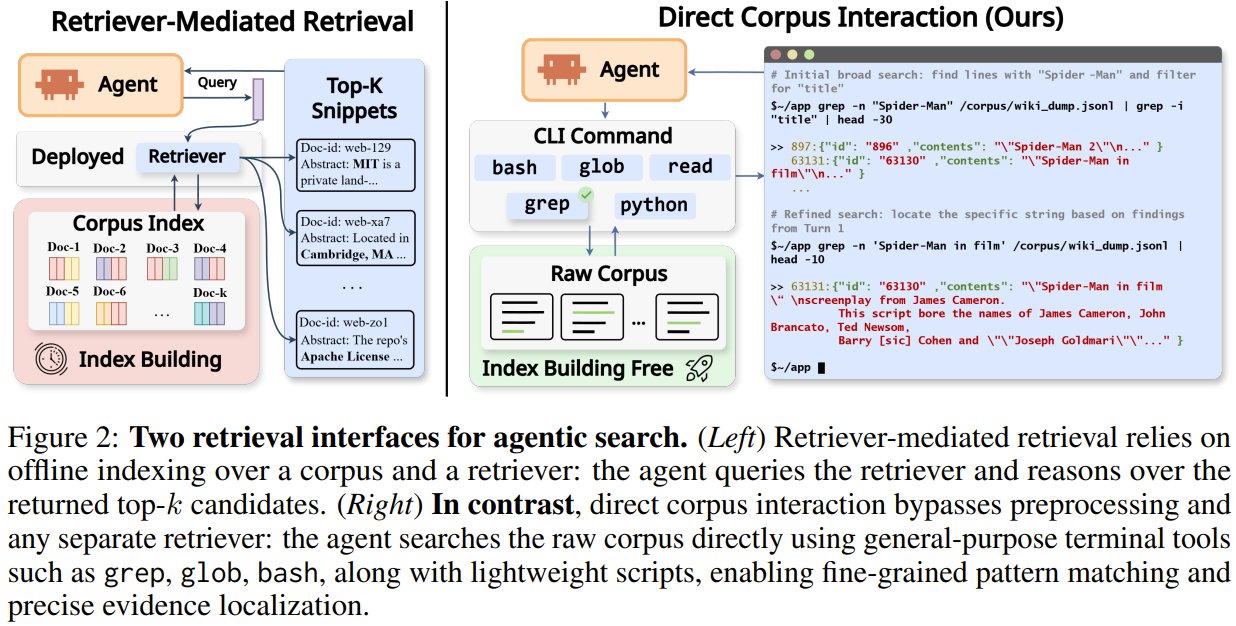
AI agents search raw text files directly using DCI
By
–
What if your AI agent could search raw text files directly instead of using vector databases? A team of researchers from Texas A&M, University of Waterloo, Stanford, and others presents Direct Corpus Interaction (DCI). Instead of embedding models or vector indexes, agents use
-
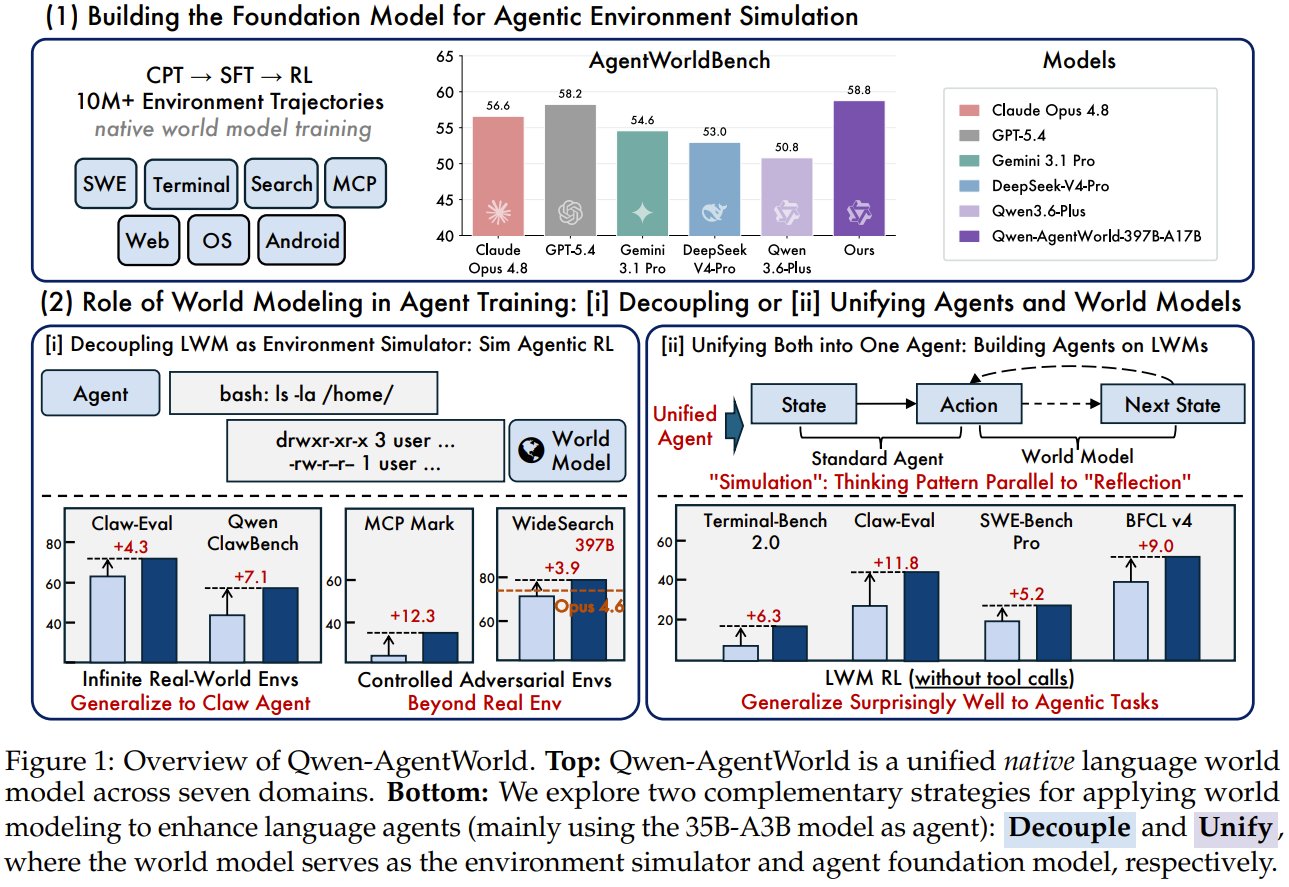
Qwen-AgentWorld: AI simulates digital environments via language reasoning
By
–
What if an AI could simulate any digital environment just by thinking in language? Qwen Team presents Qwen-AgentWorld — the first language world models that predict environment dynamics via long chain-of-thought reasoning. They trained two models (35B and 397B) on 10M+
-
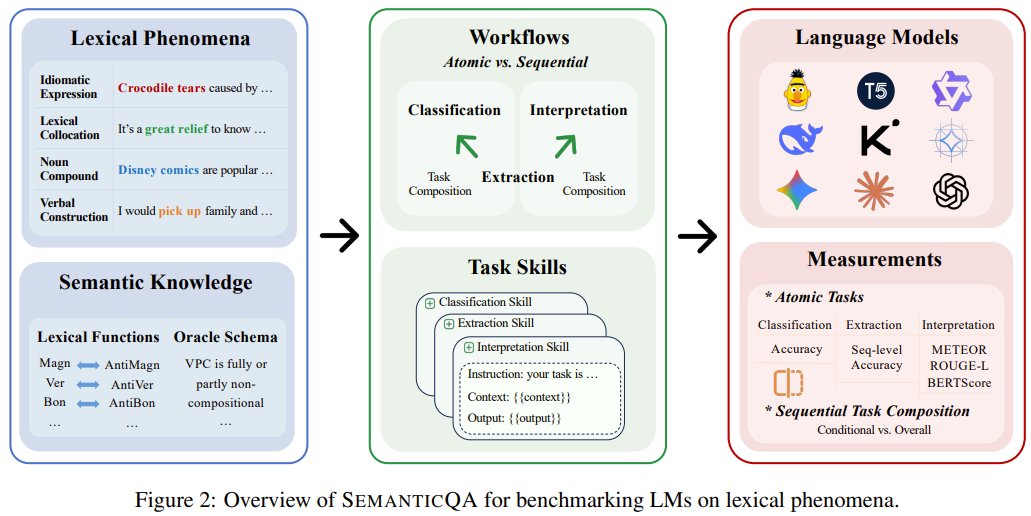
SemanticQA: a new benchmark for evaluating LM comprehension
By
–
Do your language models truly grasp meaning, or are they just pretending? Researchers from Beijing University of Science and Technology and BIGAI present SemanticQA — a new benchmark that evaluates LMs' ability to handle expressions.