
Can your AI assistant actually build an interactive game or science tool from scratch? Researchers from Ant Group, Shanghai Jiao Tong University, and Carnegie Mellon University introduce MiniAppBench — the first benchmark to test if LLMs can generate dynamic, interactive HTML
@jiqizhixin
-
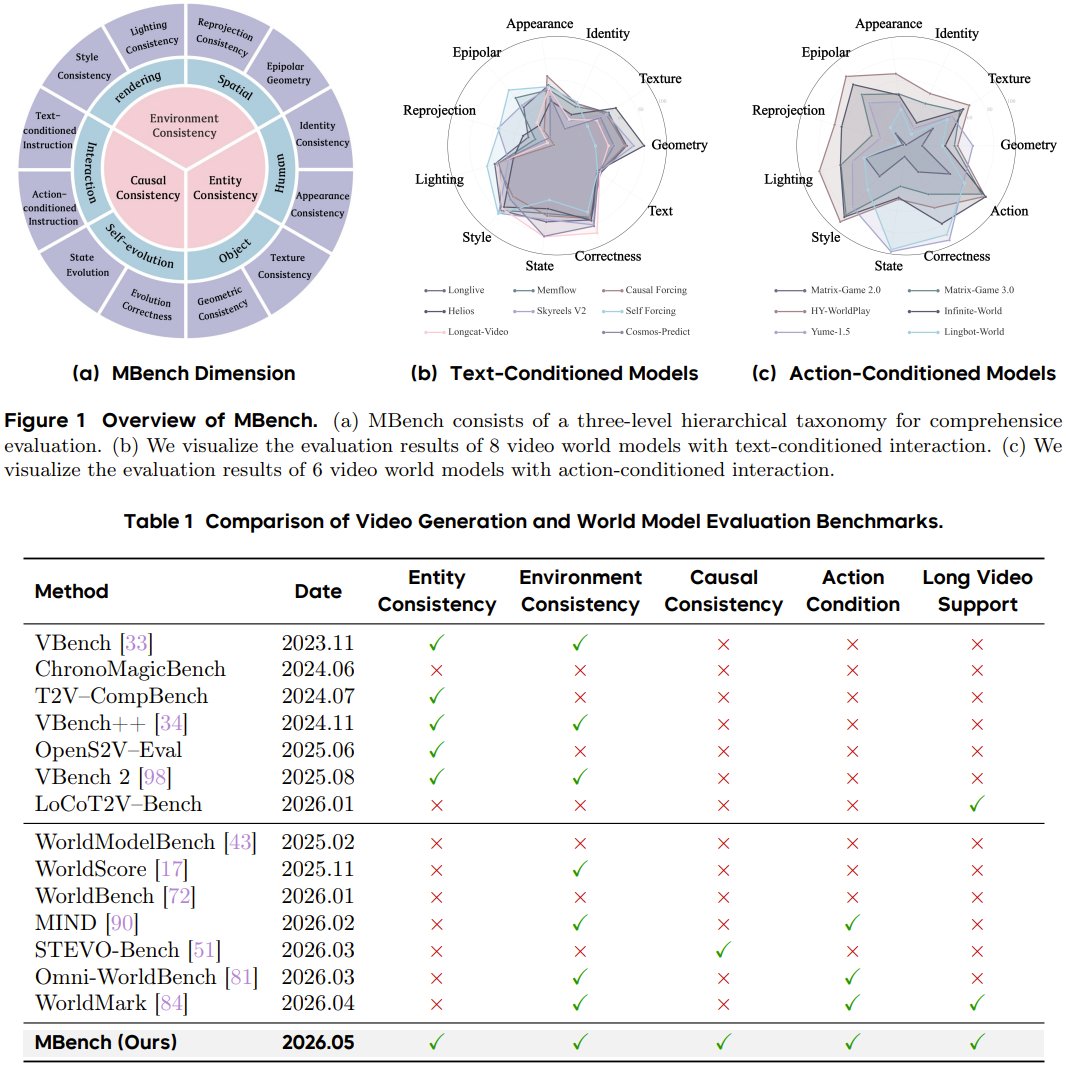
MBench tests memory in video world models
By
–
Can video world models truly remember what they see over time? Researchers from Tsinghua University, Tencent, and Peking University present MBench, a new benchmark that tests memory in video AI. Instead of just checking if videos look good, MBench measures whether models keep
-

Towards Autonomous Biology with Compiler-Verified Protocols for AI Execution
By
–
Towards Autonomous Biology: Compiler-Verified Protocols as a Foundation for Real-World AI Execution Paper: https://
biorxiv.org/content/10.648
98/2026.05.05.720956v1
… Our report: https://
mp.weixin.qq.com/s/MhS1fG2I9HIb
fXzW0H19bg
… -

Bota Biosciences’ BPL-COGEN Enables Error-Free Biological Experiments
By
–
Biology's EDA moment has arrived! Yes, now AI can truly run biological experiments without human error! Bota Biosciences presents Biology Protocol Language (BPL) and BPL-COGEN: a compiler-verified protocol language and AI pipeline that turns ambiguous natural language lab
-

Code as Agent Harness: Unified Framework for Reasoning, Action, Verification
By
–
Cool, Code as Agent Harness! Researchers from UIUC, Meta and Stanford present "Code as Agent Harness": a unified framework where code serves as an operational substrate for agent reasoning, action, and execution-based verification — and not only as
-

PRISM: New AI Sequence Model Breaks Speed-Expressivity Trade-off
By
–
Can AI sequence models be both expressive and blazingly fast? Researchers from Tencent, Beihang University, and Peking University present PRISM—a new sequence model that breaks the speed-expressivity trade-off. Instead of running slow, step-by-step iterations (like
-

VLM³ proves vision-language models are native 3D learners
By
–
What if standard vision-language models already understand 3D—without complex architecture changes or special losses? Meta and Princeton University present VLM³, showing that VLMs are native 3D learners. Their recipe: unify camera focal lengths, use text-based pixel references,
-
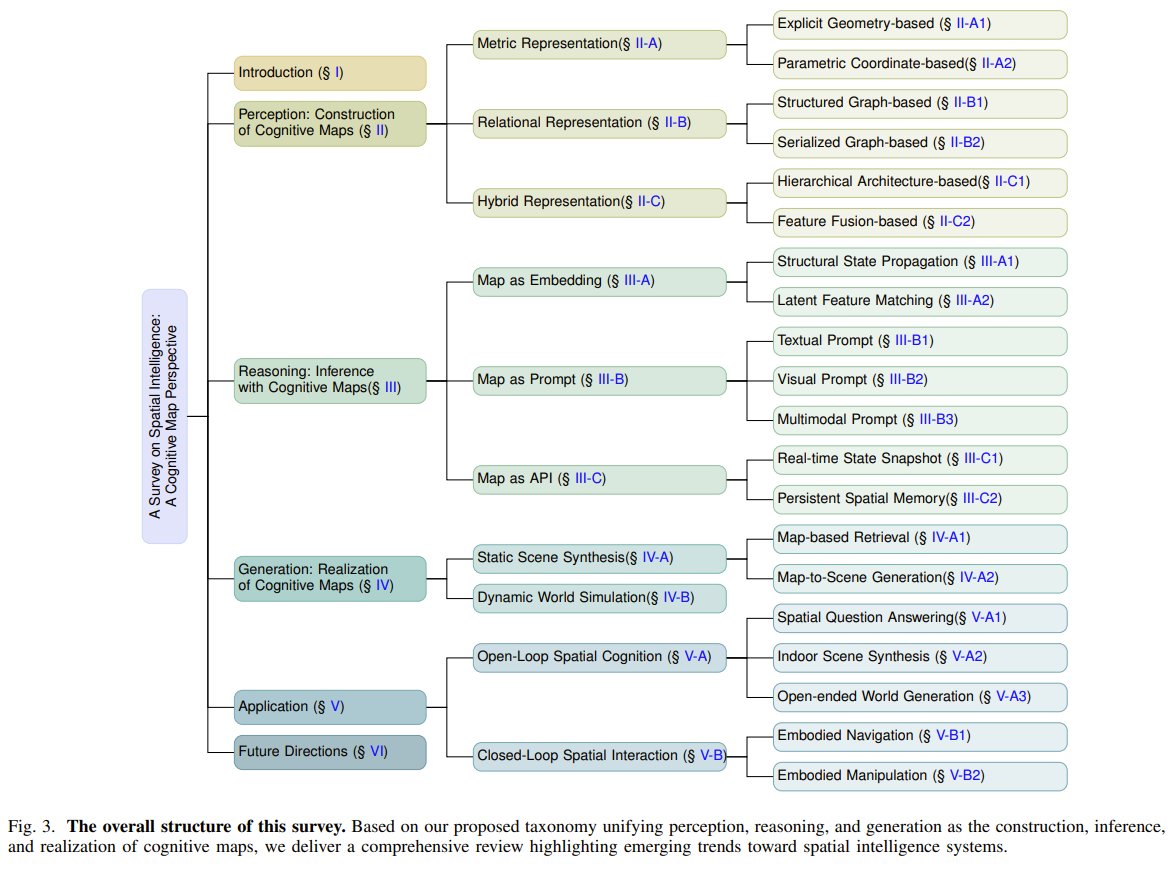
New survey rethinks AI spatial intelligence via cognitive maps
By
–
How do AI agents understand space like humans? Researchers from Chinese Academy of Sciences, Beihang, and NTU present a new survey that rethinks spatial intelligence through cognitive maps. They define cognitive maps as internal, persistent models of the world that are both
-

Prompt Reinjection fixes forgetting detailed descriptions
By
–
Why do AI image generators keep forgetting your detailed descriptions? A team from Fudan University, Alibaba, and Baidu introduces Prompt Reinjection. They found that multimodal diffusion transformers gradually lose prompt info in deeper layers. Their training-free fix:
-

NVIDIA PiD decodes AI latents to 4K in under a second
By
–
Can you decode AI latents to 4K images in under a second? NVIDIA researchers introduce PiD, a pixel diffusion decoder that unifies decoding and upscaling into one fast step. It converts 512×512 latents to 2048×2048 pixels in under 1 sec on a consumer RTX 5090 — 6x faster than