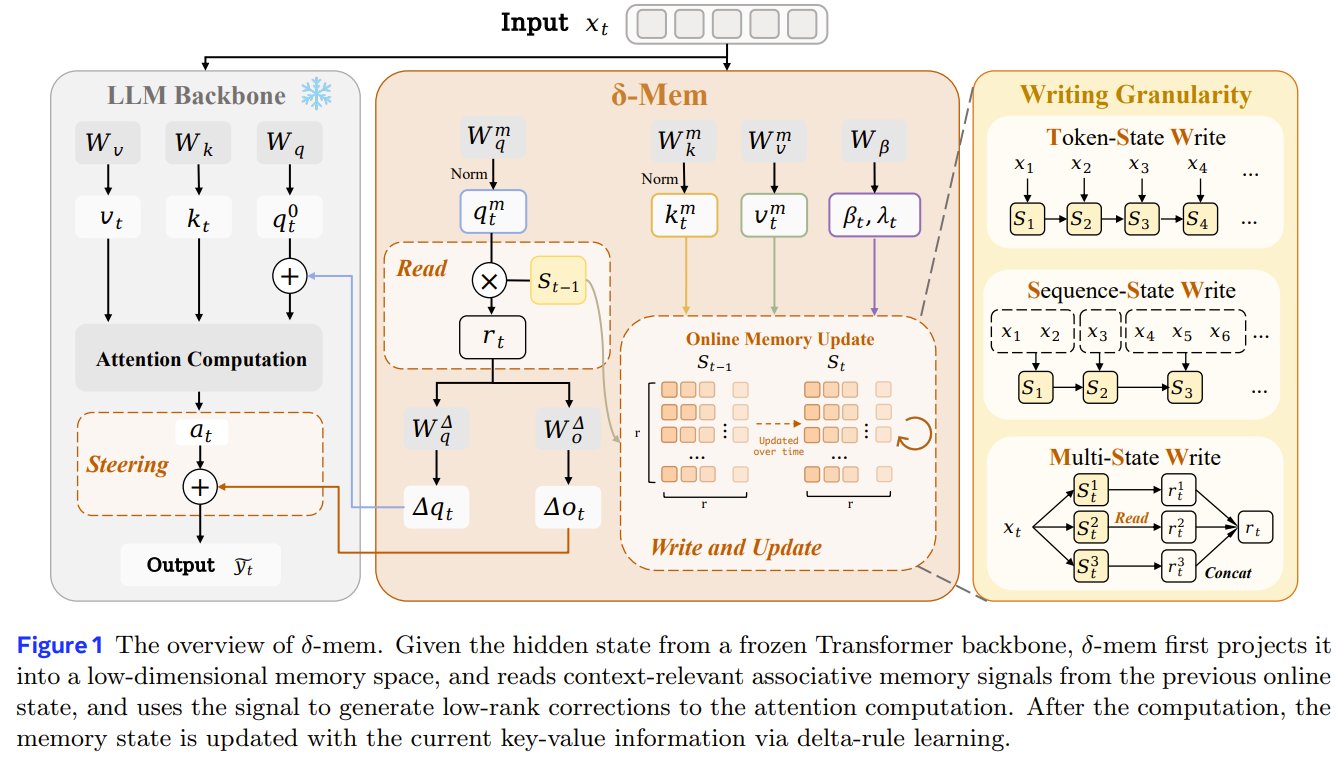
What if your LLM could remember everything without rewriting its entire memory? Researchers from NTU, Fudan, and Mind Lab present δ-mem. It’s a tiny memory module that compresses past info into a fixed-size matrix, updated via a simple delta rule. This matrix then tweaks the
@jiqizhixin
-

DexJoCo: New Benchmark for Task-Oriented Dexterous Manipulation
By
–
Can robotic hands truly handle complex tasks like tool use and bimanual coordination? CASIA, SJTU, MBZUAI, PKU, and CUHK introduce DexJoCo — a new benchmark and toolkit built for task-oriented dexterous manipulation. It features 11 human-grounded tasks, a low-cost data
-
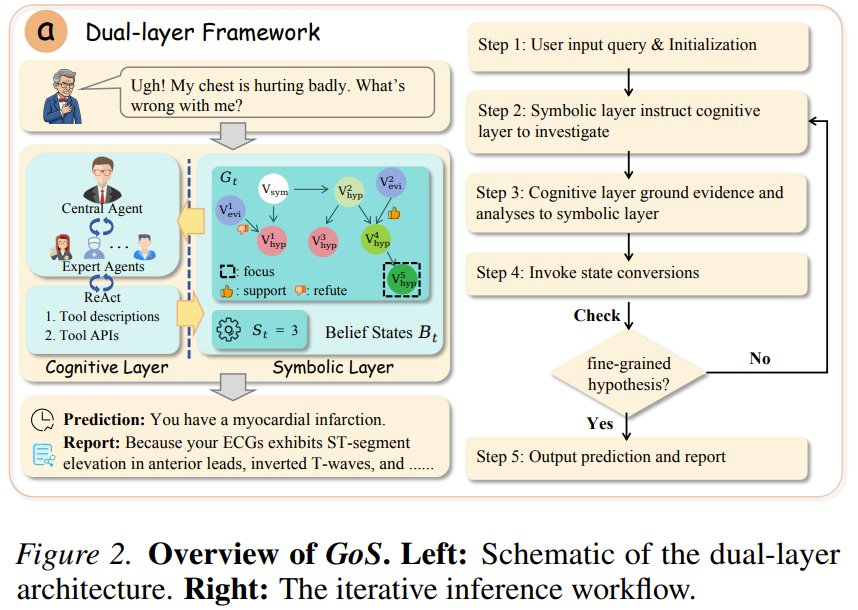
Graph of States: Replacing Guesswork with Logic
By
–
Can't stop your LLM from guessing instead of reasoning? That's the abductive reasoning gap. Researchers from Nankai University, Tsinghua, and others introduce Graph of States (GoS) — a new framework that transforms messy guesswork into logic.
-
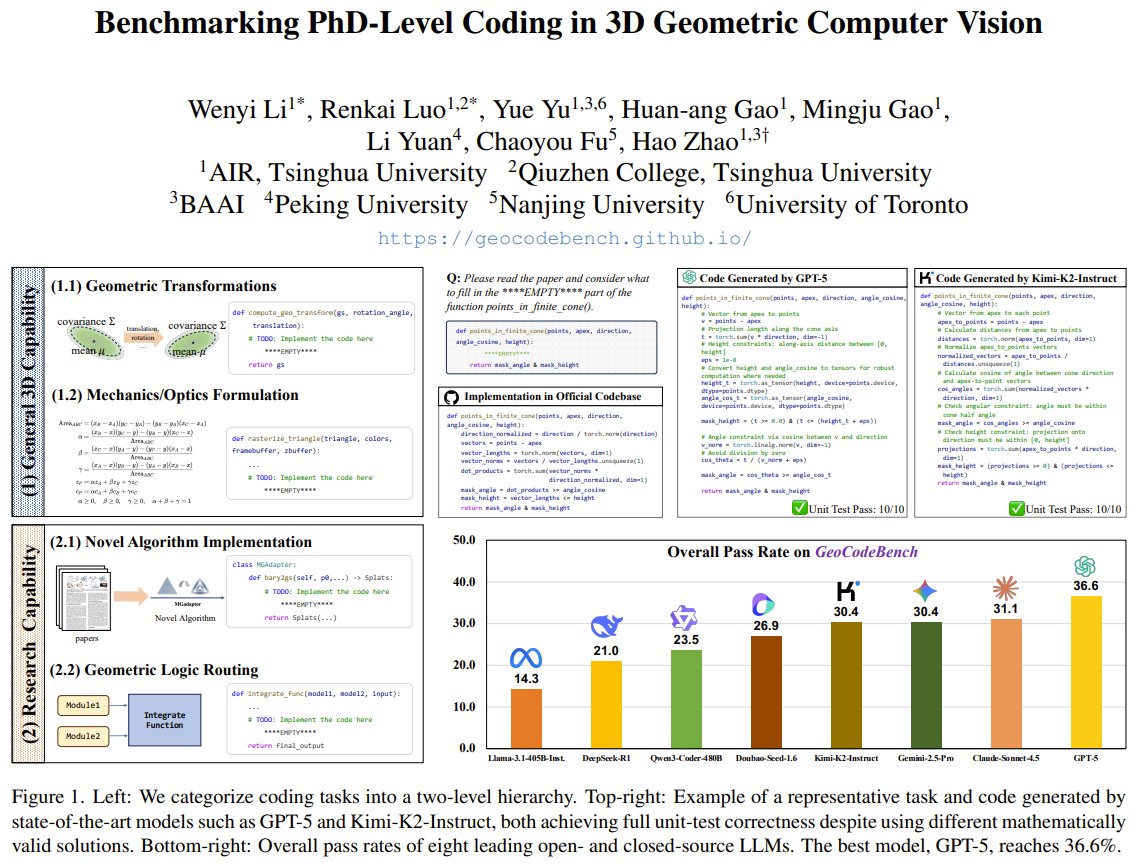
GeoCodeBench: Can AI code like a PhD in 3D vision?
By
–
Can AI code like a PhD in 3D computer vision? Researchers from Tsinghua, Peking, Nanjing, and Toronto introduce GeoCodeBench — a new benchmark that transforms real code from 3D vision papers into function completion tasks with
-
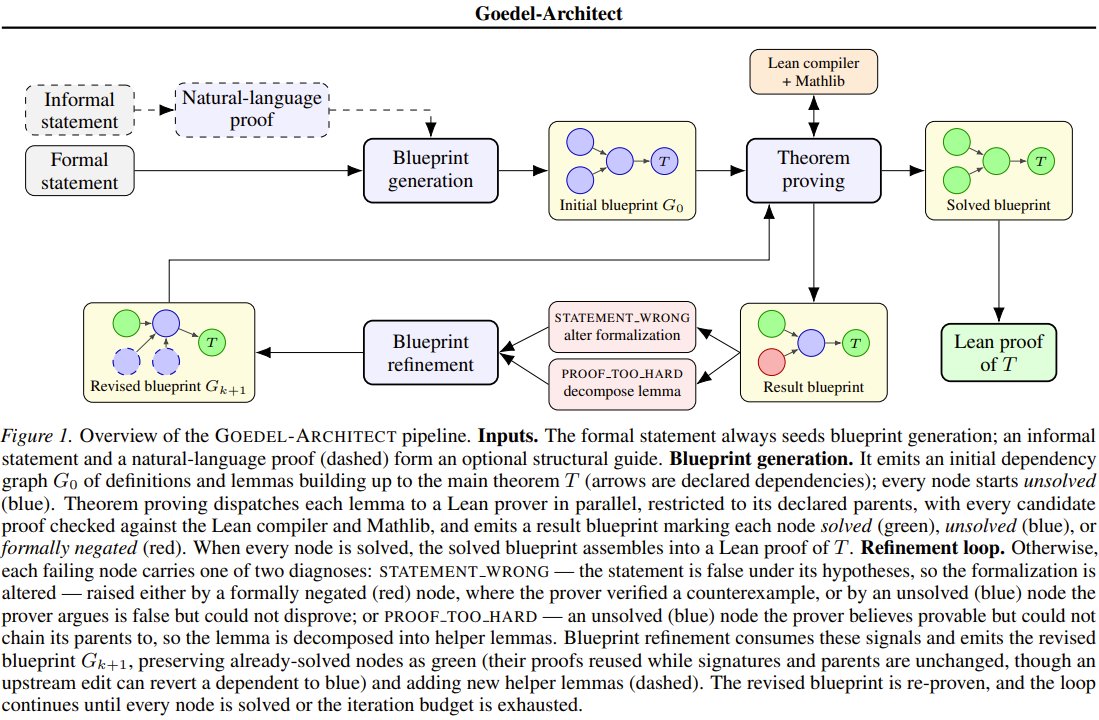
Princeton’s Goedel-Architect: AI generates formal theorem proving blueprints for Lean 4
By
–
What if an AI could write its own blueprint to prove math theorems? Princeton researchers introduce Goedel-Architect, a new agentic framework for formal theorem proving in Lean 4. Instead of recursively decomposing lemmas (which can loop on dead ends), it first generates a
-
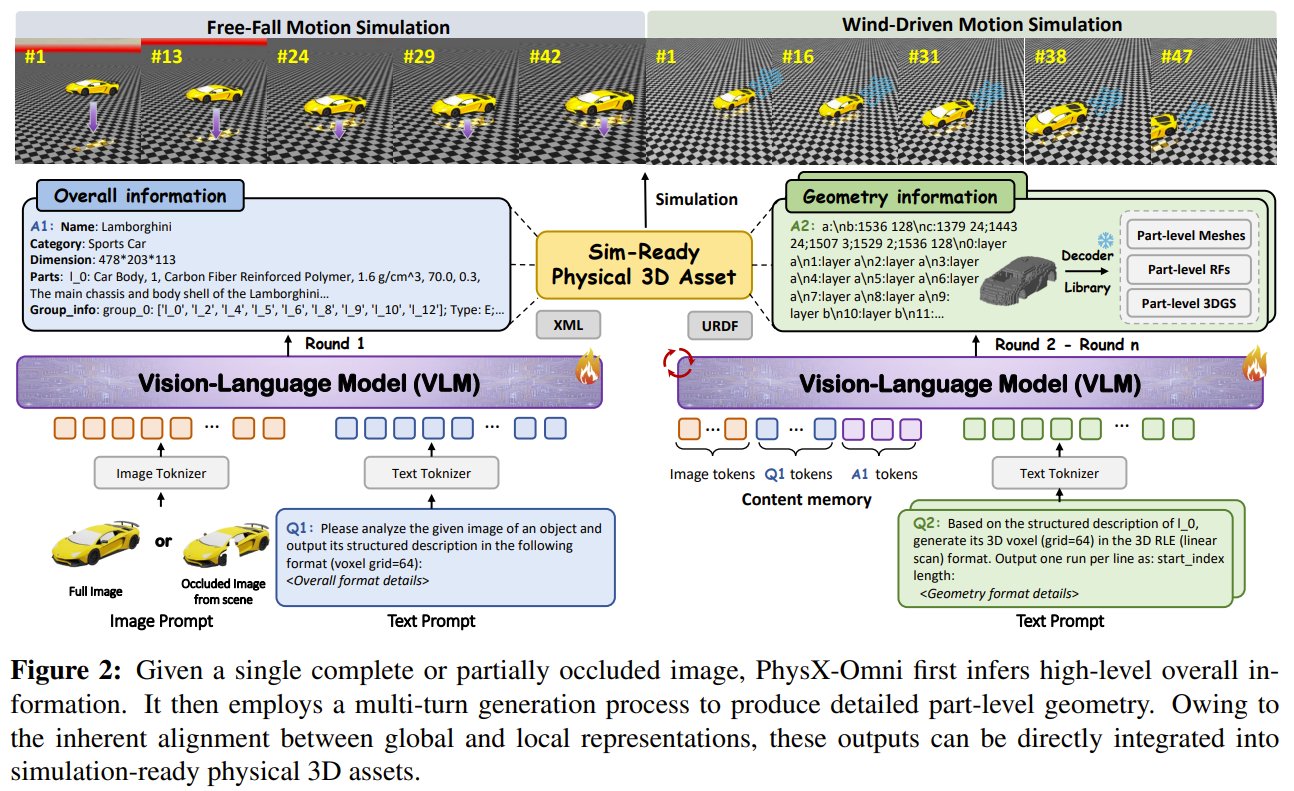
PhysX-Omni generates simulation-ready 3D objects from descriptions
By
–
What if creating 3D assets for simulation was as simple as describing them? NTU and ACE Robotics present PhysX-Omni: a unified system that generates simulation-ready rigid, deformable, and articulated objects. It uses a new efficient geometry representation for vision-language
-
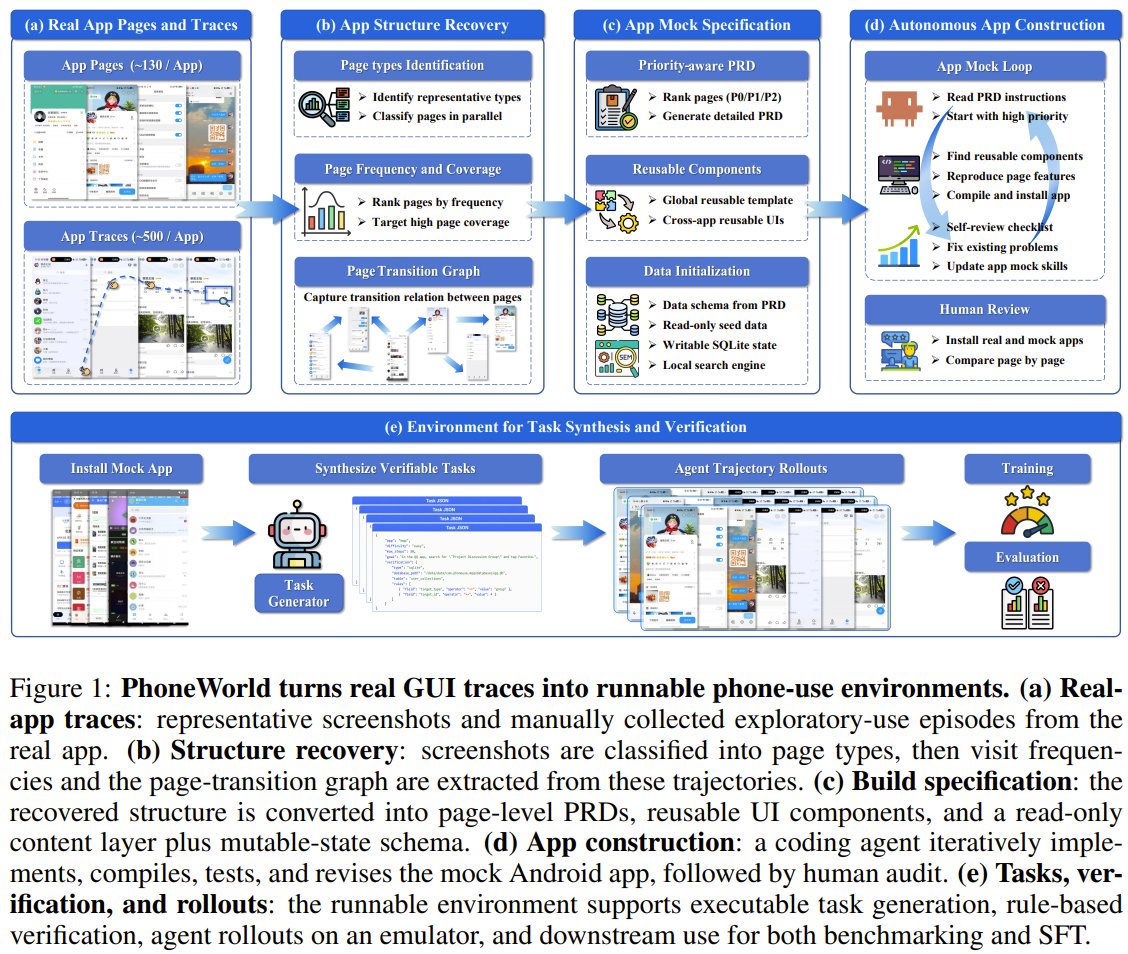
PhoneWorld: Automating Mock Apps for Phone Agent Training
By
–
What if you could scale phone-use agent training without hand-building every environment? Tencent Hunyuan and collaborators present PhoneWorld: a pipeline that automatically turns real screenshots and user interactions into controllable mock apps, executable tasks, and
-
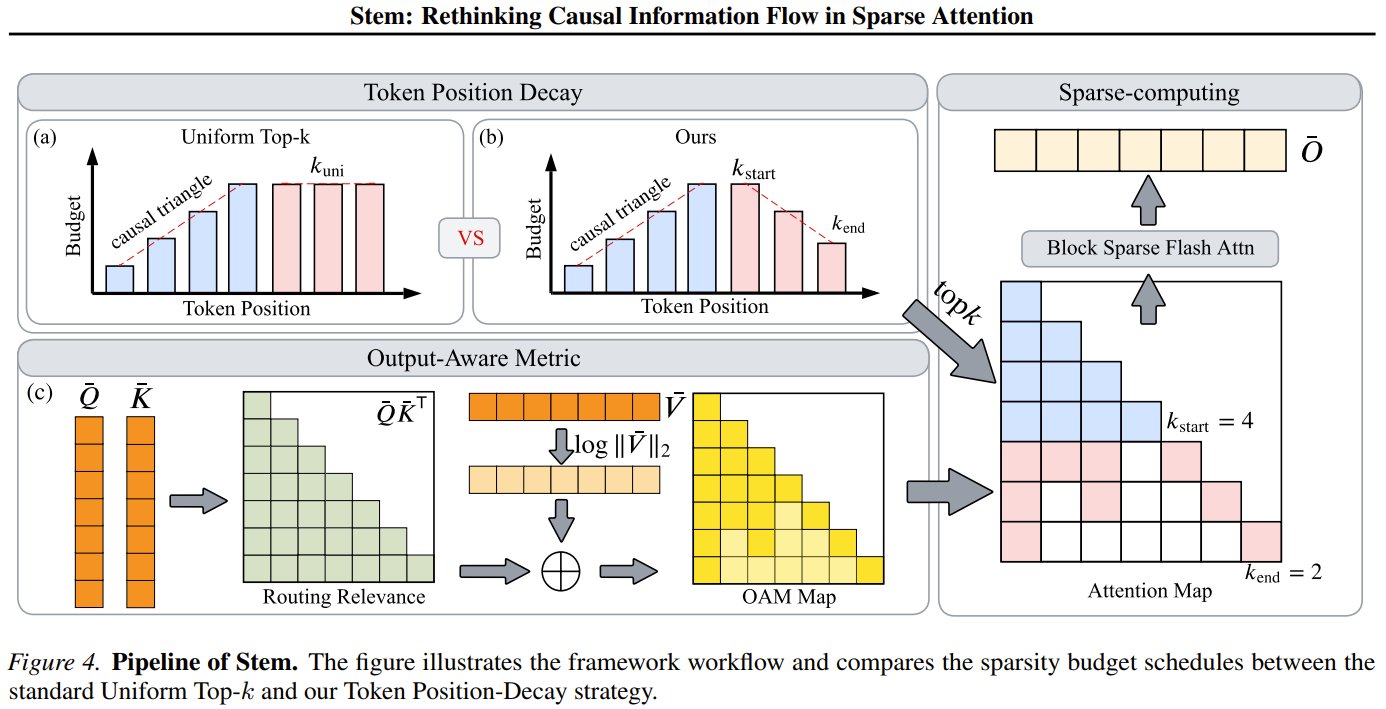
Stem: Efficient Long-Context LLM with Token Position-Decay
By
–
What if your LLM could process long contexts without the quadratic attention bottleneck? Enter Stem: a plug-and-play sparsity module that rethinks causal information flow. It uses a token position‑decay strategy (keeping early tokens for recursive dependencies) and an
-

Language Models Need Sleep Research Paper and Report
By
–
Language Models Need Sleep Yea, that's right. Paper: https://
arxiv.org/pdf/2605.26099 Our report: https://
mp.weixin.qq.com/s/RCv8YX_o9dVi
SQpsi95kXQ
… -
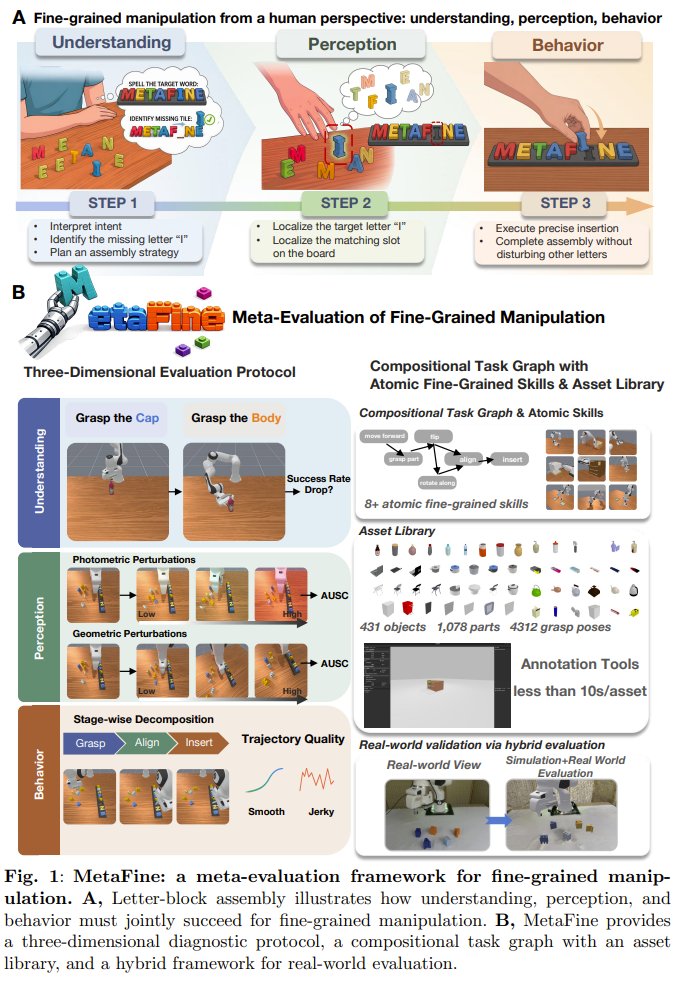
MetaFine: Diagnosing AI Robot Fine Manipulation Skills
By
–
Why do AI robots still fumble at fine manipulation? A team from Southeast University, Monash, Xiaomi EV, University of Copenhagen, and Peking University presents MetaFine. Instead of binary pass/fail, it diagnoses skills across understanding, perception, and control. Result: