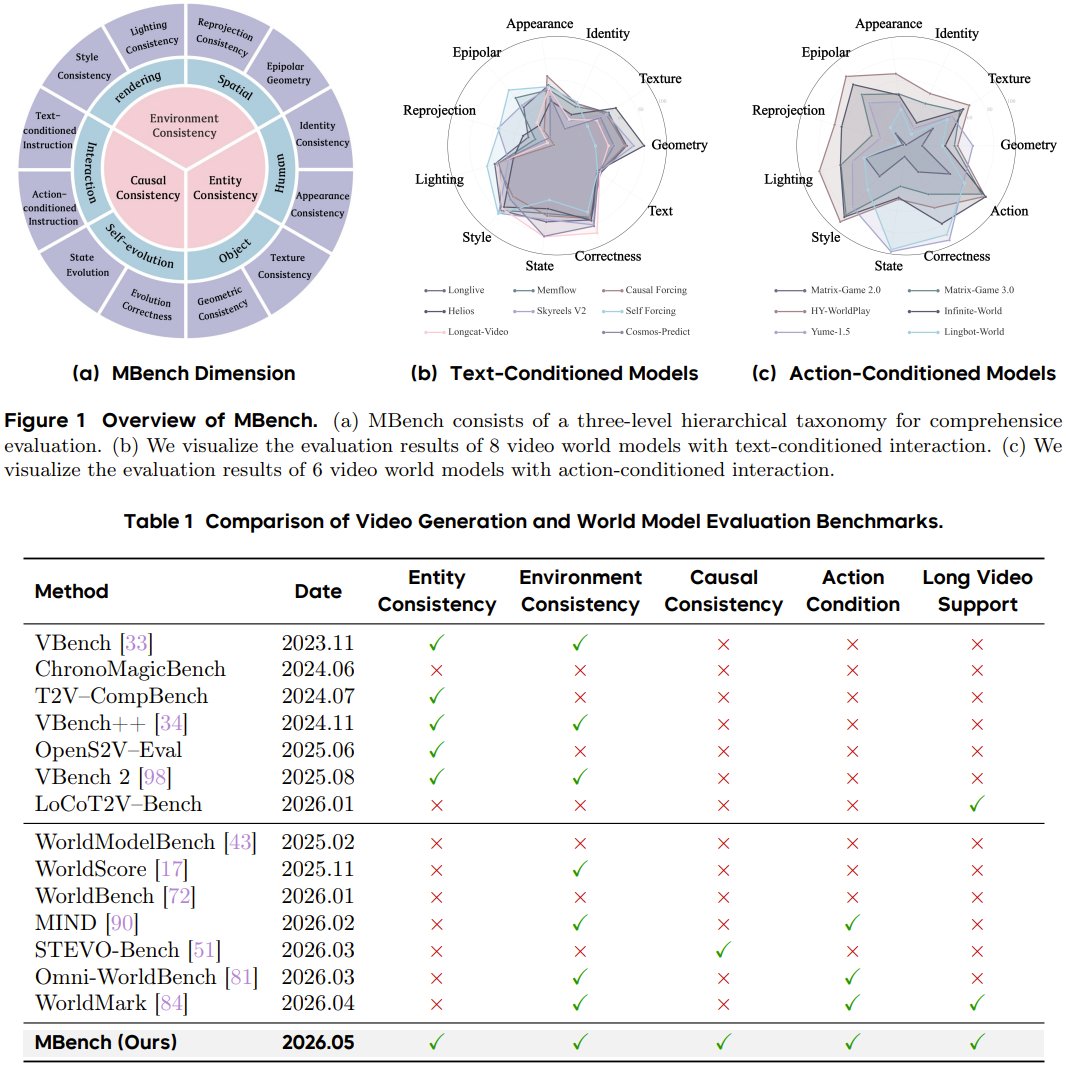
Can video world models truly remember what they see over time? Researchers from Tsinghua University, Tencent, and Peking University present MBench, a new benchmark that tests memory in video AI. Instead of just checking if videos look good, MBench measures whether models keep
MULTIMODAL AI
-
Street View Grounding Now Available for Google’s Offline Video Models
By
–
street view grounding now available for google’s offline video models. can’t wait till you can do “spatial RAG” to load in the right panoramas to reference – suddenly large scale real world locations become movie sets! https://t.co/AR3gLfj0p6
— Bilawal Sidhu (@bilawalsidhu) 23 juin 2026street view grounding now available for google’s offline video models. can’t wait till you can do “spatial RAG” to load in the right panoramas to reference – suddenly large scale real world locations become movie sets!
-
Scaling compute on context to study Moby Dick and Fed livestreams
By
–
Joe you might not want to hear this but as we speak I'm scaling compute on your context. the model is studying Moby Dick, it's developing new theories of orality, it's watching Fed livestreams.
-
Krea 2 Technical Report: Deep Dive on Data, Architecture, Training
By
–
our technical report is out.
— Krea (@krea_ai) 23 juin 2026
deep dive on the data, architecture, and training techniques used to create Krea 2. https://t.co/mNLs2srSIw https://t.co/Ms1Sd277y7our technical report is out. deep dive on the data, architecture, and training techniques used to create Krea 2. https://
krea.ai/blog/krea-2-te
chnical-report
… -
Enable Gemini to summarize, write, translate, analyze
By
–
1. Gemini, already integrated. Press and hold the home button or swipe up from a corner. A real AI opens, not the old assistant. Ask it to summarize a page you're reading, write an email, translate a sign, or analyze a photo. It was
-

ArtiFixer: Generative 3D Scene Reconstruction from Text or Few Views
By
–
ArtiFixer doesn't just clean up 3D meshes—it is a robust generative engine. Even if you entirely drop the initial 3D rendering conditions, the model can rely on text prompts or just a few reference views to reconstruct the high-level structure of the scene and synthesize
-

ArtiFixer uses DMD to make bidirectional video models 70x faster
By
–
Bidirectional video models provide great coherence but are computationally heavy. ArtiFixer solves this via Self-Forcing-style Distribution Matching Distillation (DMD). By distilling the bidirectional model into a causal auto-regressive one, ArtiFixer achieves up to a 70x
-

Opacity Mixing: Balancing Consistency and Hallucination in Video
By
–
How do you keep the generated video consistent with existing views without losing the ability to hallucinate new content? The answer is Opacity Mixing. Instead of starting from pure noise, ArtiFixer:
> Downscales the rendering's opacity map.
> Mixes Gaussian noise specifically -
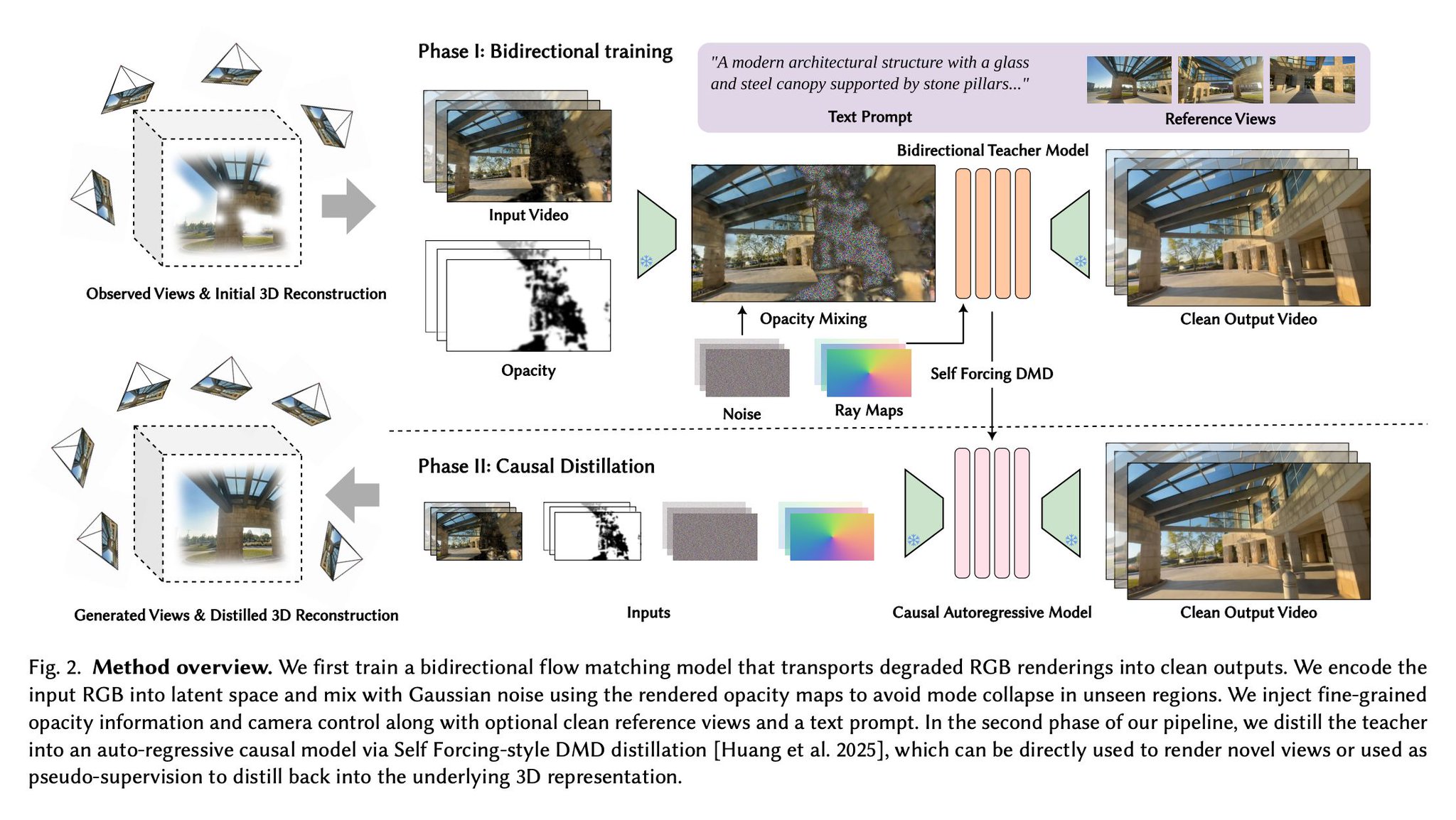
ArtiFixer combines 3D reconstruction and video generation in two phases
By
–
Instead of treating 3D reconstruction and video generation as standalone alternatives, ArtiFixer combines their strengths. > Phase I: Trains a powerful bidirectional generative video model to transport degraded renderings into clean frames.
> Phase II: Distills the teacher model -
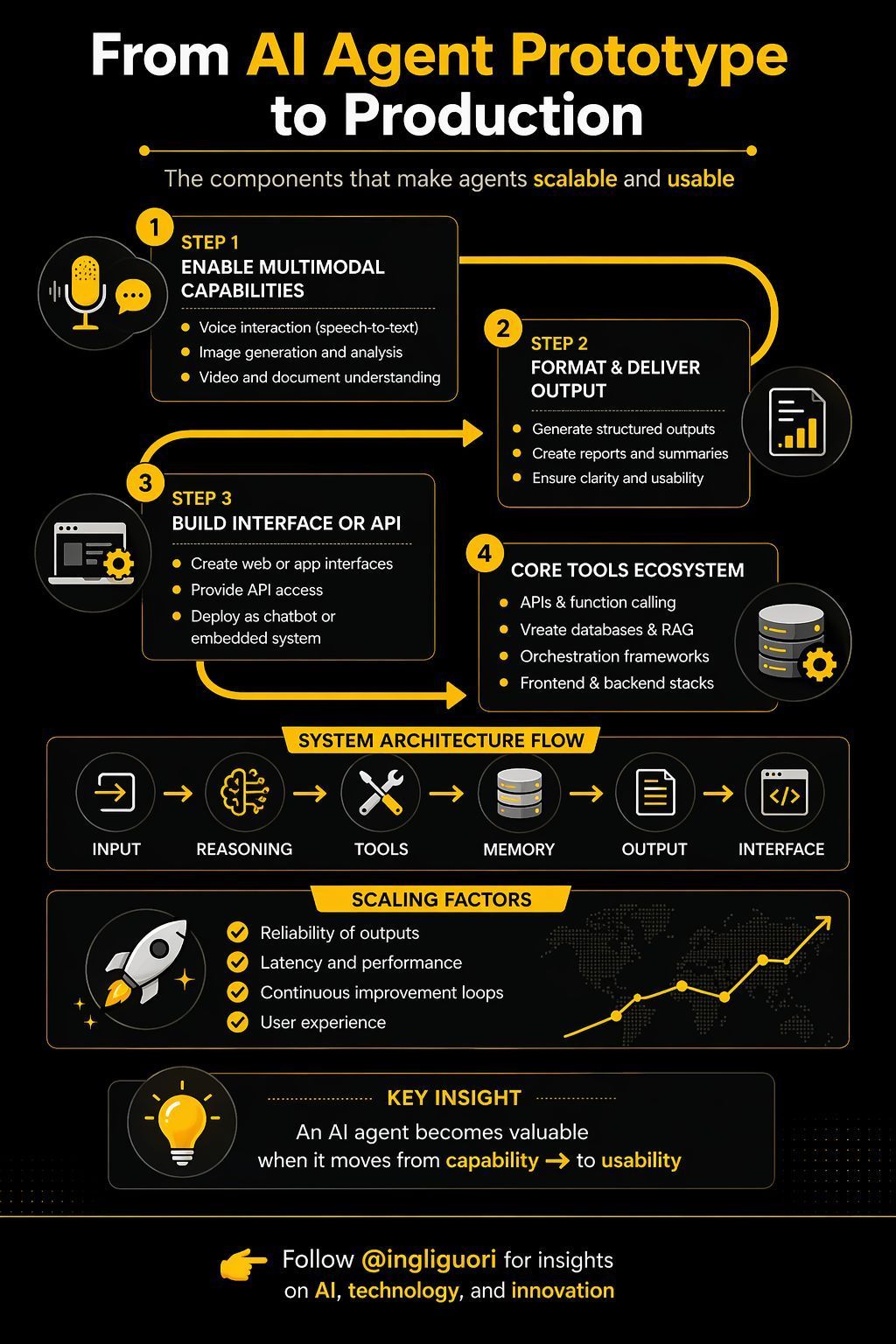
AI agents fail at prototype stage, real value is usability
By
–
AI agents fail when they stop at the prototype stage • Multimodal input
• Structured output
• APIs & interfaces
• Tools + memory + RAG Real value comes from usability, not capability alone. Via Giuliano Liguori (
@ingliguori
) #AI #AIAgents #Tech