

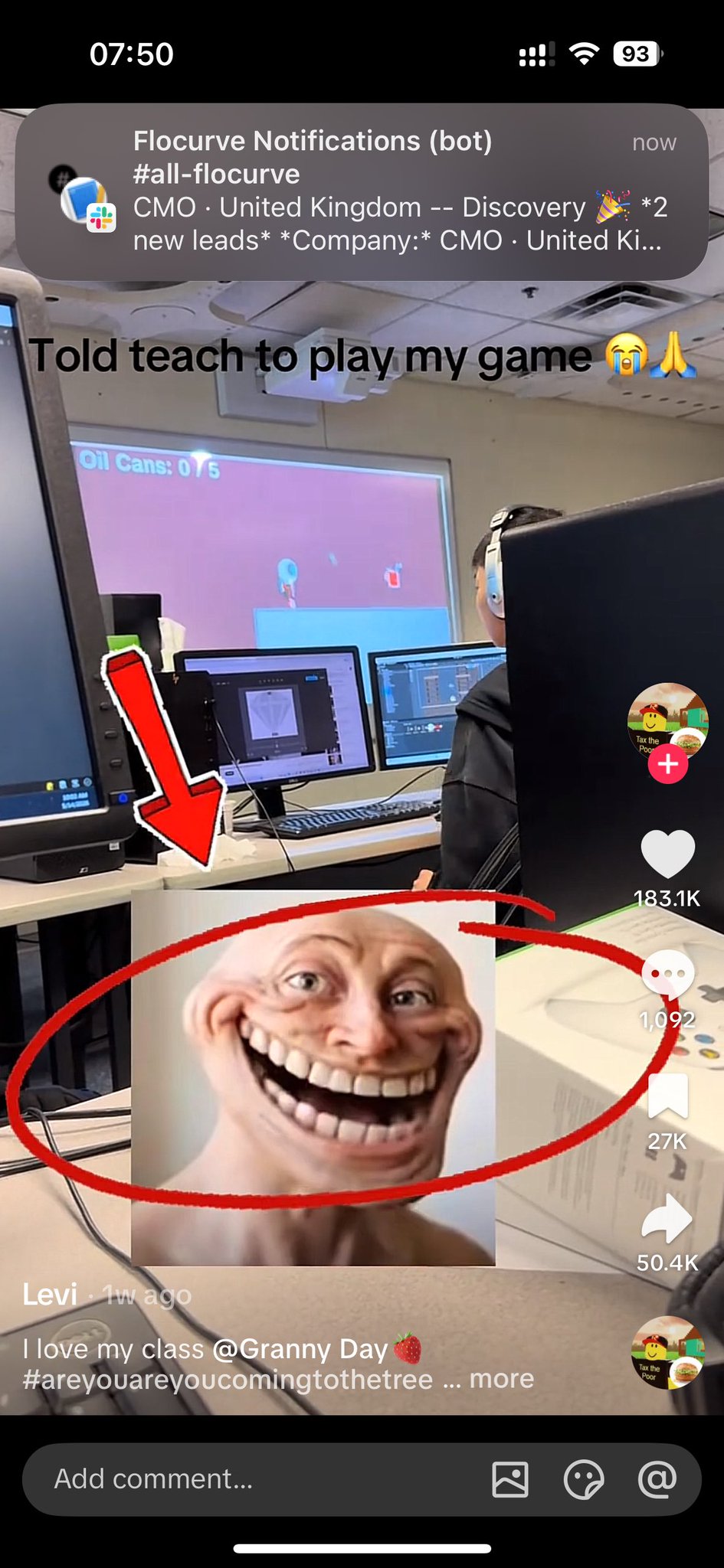
I made the realistic trollface meme with Google Veo 3 and Nanobanan Pro in late November for fun. In the last week it picked up over 500.000.000 views combined on TikTok amongst the late Gen-z generation. “told teach to check email”
By
–
I made the realistic trollface meme with Google Veo 3 and Nanobanan Pro in late November for fun. In the last week it picked up over 500.000.000 views combined on TikTok amongst the late Gen-z generation. “told teach to check email”
By
–
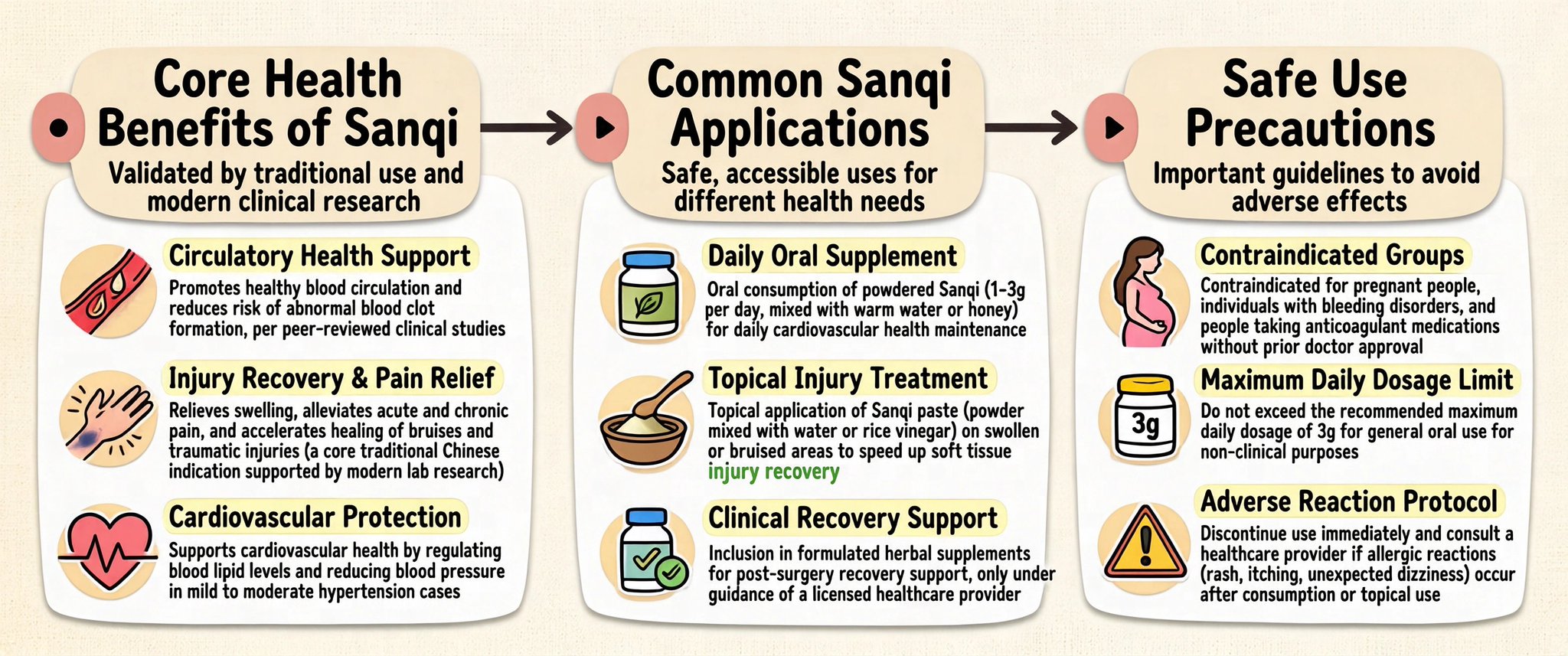
Infographics are where weak models get exposed. Tiny labels break.
Layouts collapse.
Text turns into alien noodles.
The message gets lost. SenseNova U1 is built for dense visual communication: posters, PPTs, knowledge maps, comics, diagrams, explainers.
By
–
Pretty image models die when structure shows up. Posters. Charts. Recipe cards. Postcards.
Even arXiv-style pages. SenseNova-U1-8B-MoT-Infographic was built for that. > +6.8 on BizGenEval hard
> +18.2 on IGenBench Q-ACC
> 100+ showcases Less “make it pretty.”
More “make it
By
–
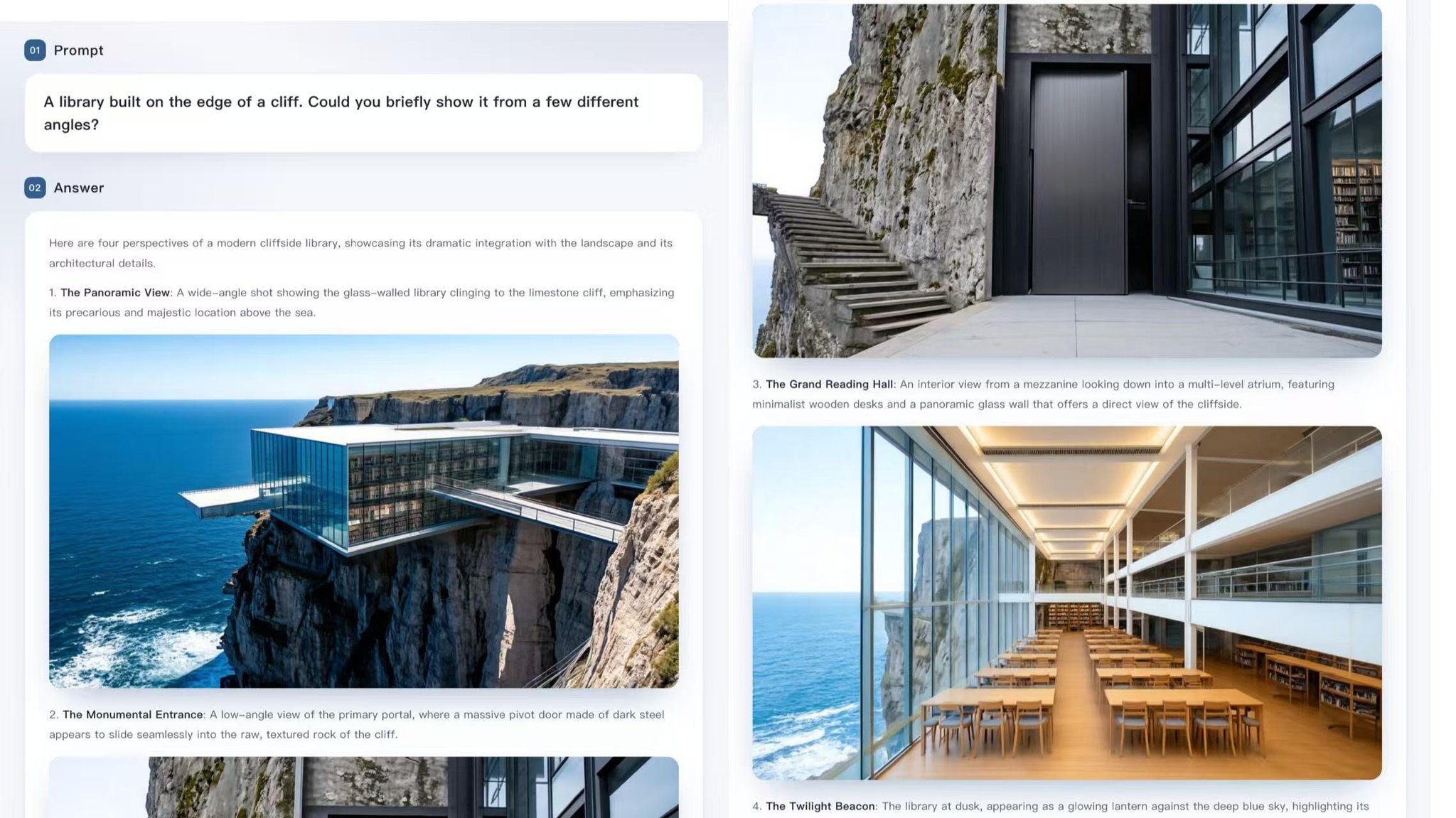
Here’s the feature that deserves more attention: SenseNova U1 can generate interleaved text + image outputs in one response. Not just an image.
Not just an explanation.
A full structured flow that combines both. Think step-by-step tutorials, cooking guides, how-tos, lesson

By
–
This is the part most people will miss: SenseNova U1 doesn’t just “look at images” or “generate images.” It can create interleaved image + text outputs in one flow. Guides. Tutorials. Visual explainers. Workflows. Comics. Recipes. Not a chatbot with pictures taped on.

By
–
The archive is awake. Introducing the renewed http://
MONTREAL.AI YouTube channel — public intelligence for the AGI‑First → ASI‑First era. Home of the AGI Debate archive and the official video record for http://
MONTREAL.AI & http://
QUEBEC.AI.
By
–
This also marks 10 years of Cubist Mirror, my first real-time AI installation.
— Gene Kogan (@genekogan) 21 mai 2026
At 360 pixels x 1 fps, it's no stream diffusion, but 6 months before then, I could only make 1 frame every 15 minutes.https://t.co/DrxlOJZGhd
This also marks 10 years of Cubist Mirror, my first real-time AI installation. At 360 pixels x 1 fps, it's no stream diffusion, but 6 months before then, I could only make 1 frame every 15 minutes.
By
–
Prompt 2: "The Pain Point Miner" "Based on the [NICHE] projects you just found, I need
you to do deep research on the complaints and unmet
needs people are expressing around these tools and
this space in general. Search Reddit threads, X posts, Product Hunt comment
sections,
By
–
Prompt 1: "The Build Trend Scanner" "I'm interested in [YOUR NICHE, e.g. productivity tools,
developer tools, AI wrappers, personal finance]. Do deep research on what solo developers and indie
builders have shipped in this space in the last 90 days. Search Product Hunt

By
–
The next interface to biology may not be a dashboard.
It may be a conversation. I just read a new preprint by Yanbo Zhang and Michael Levin that feels like it belongs in the “this may open an entirely new category” folder. The paper is called: “Language Game: Talking to