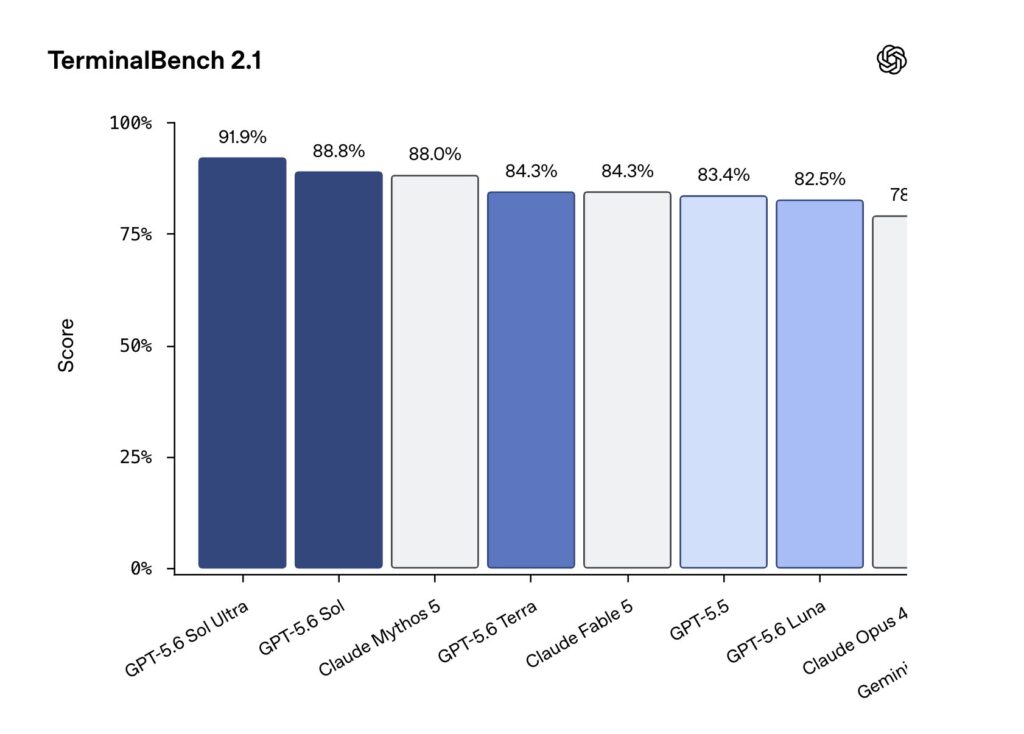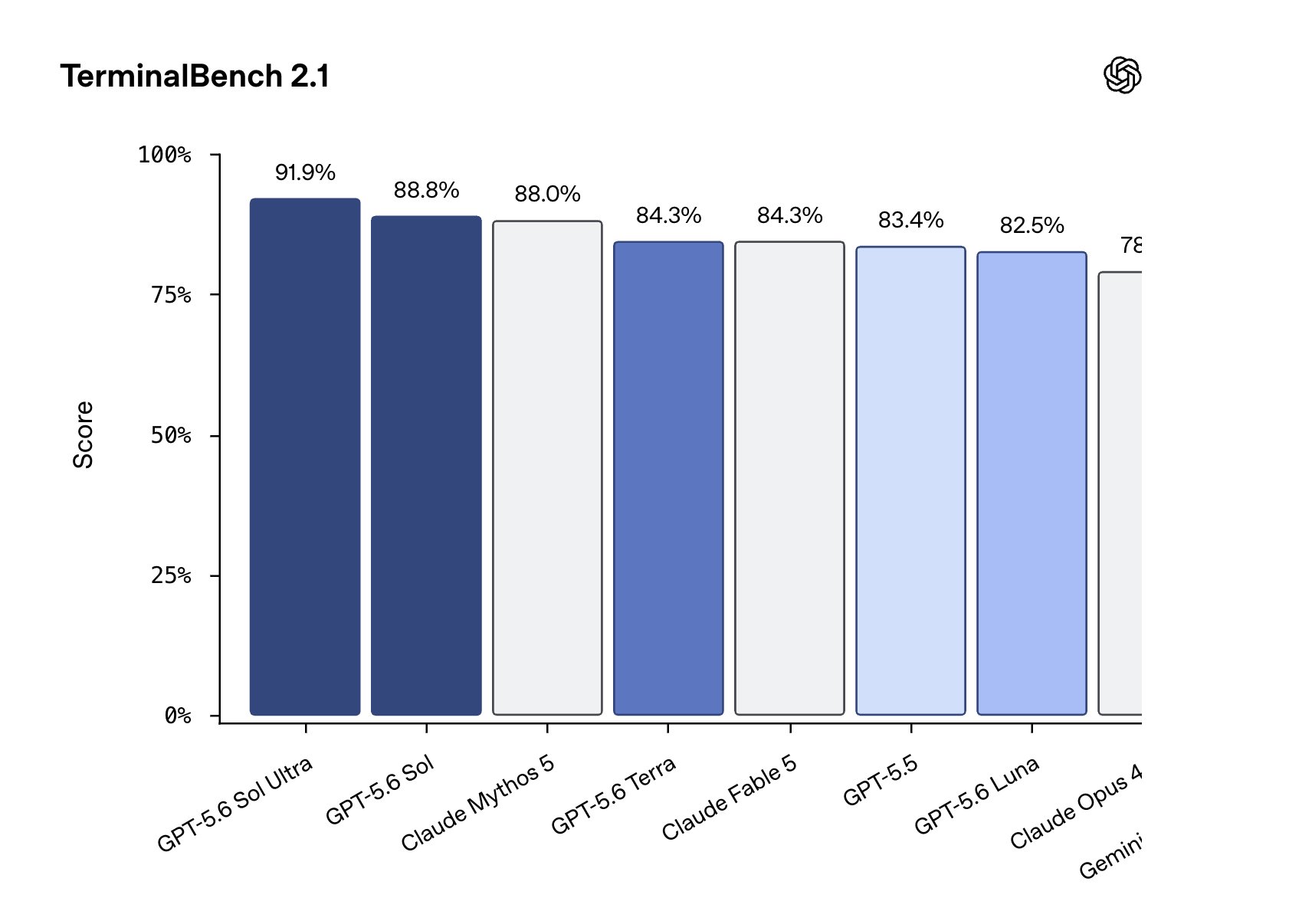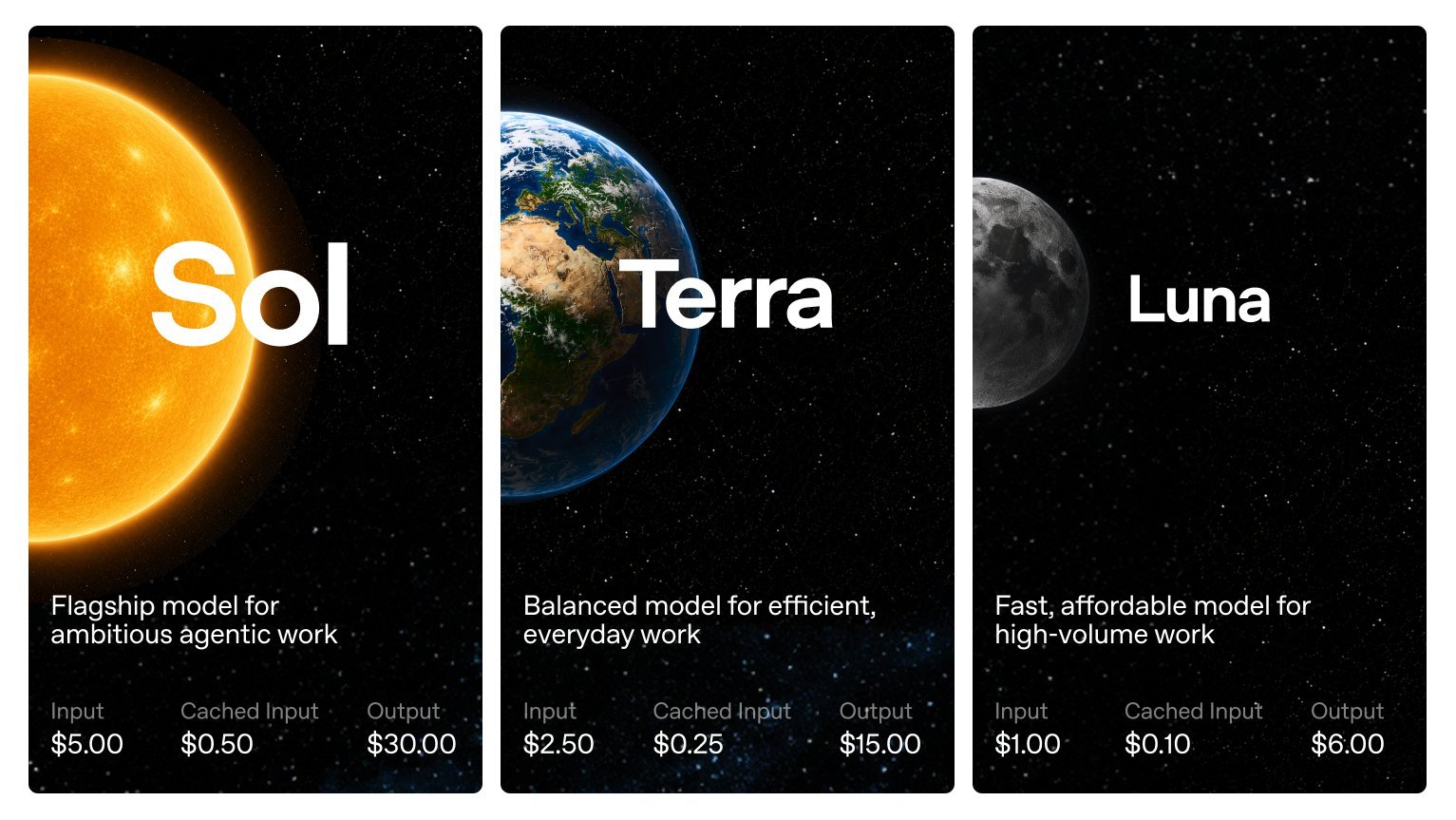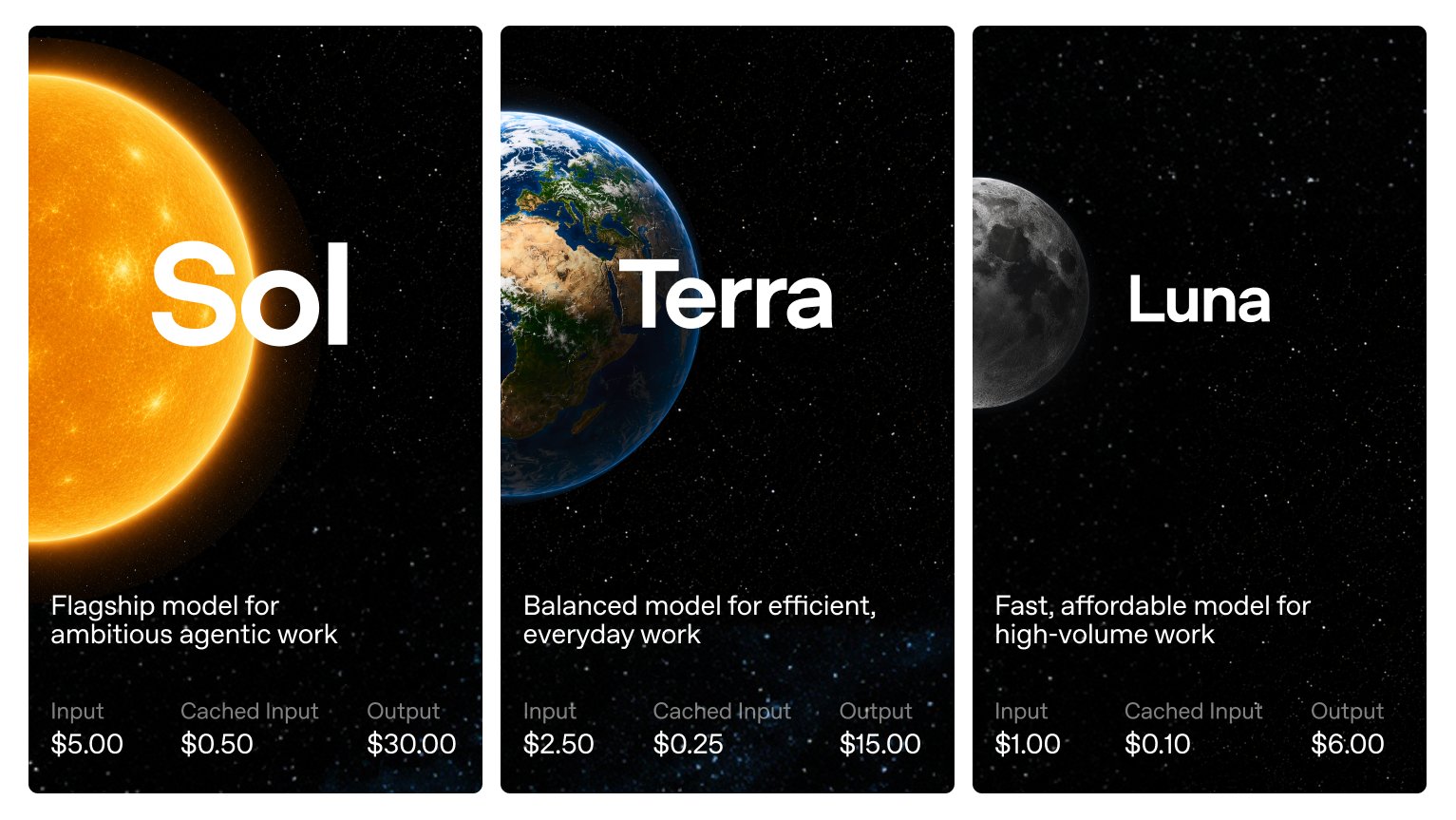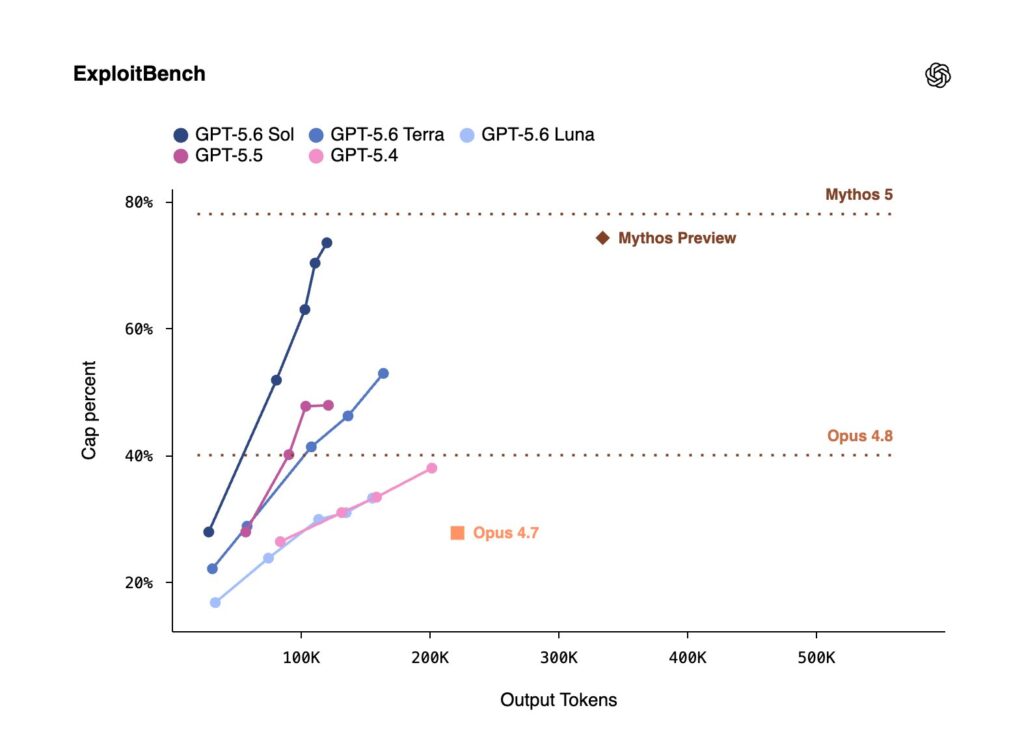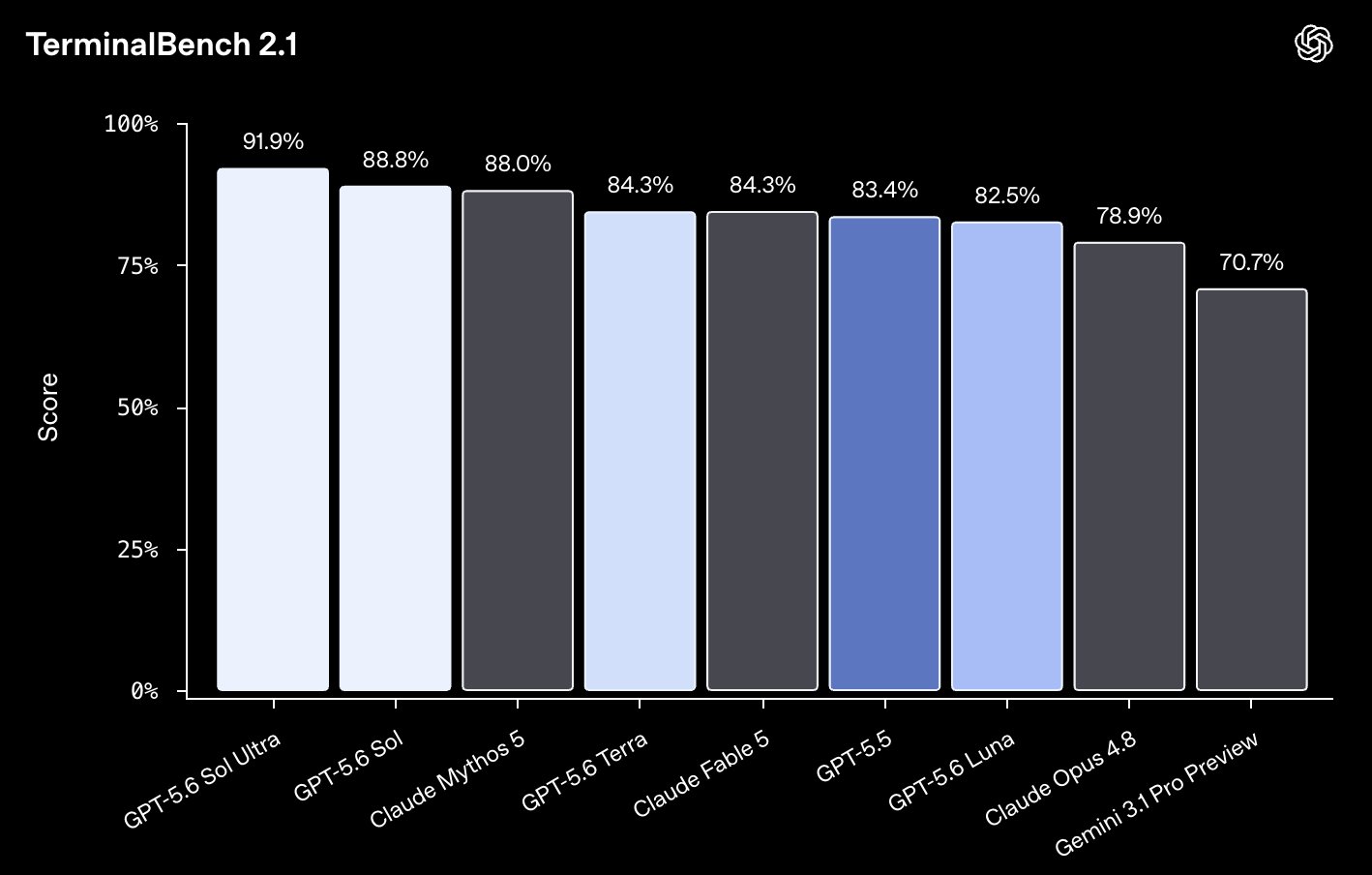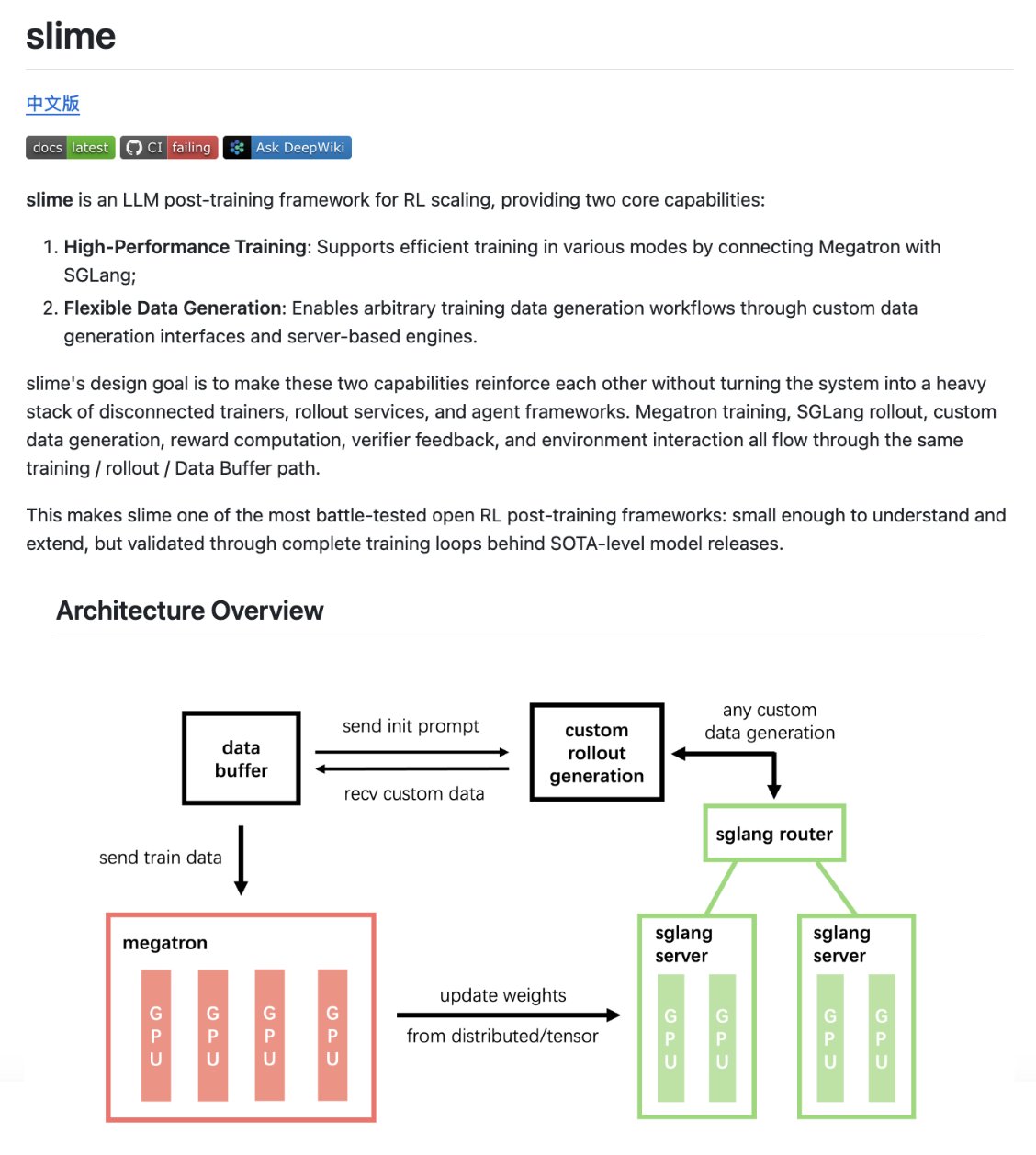
The RL framework behind GLM-5.2 is fully open source. The full post-training of GLM-5.2 ran on it in about two days. The same stack sits behind the entire GLM series, from 4.5 to 5.1. It is called slime, and it is built around one idea. Keep a single RL kernel, and push all the