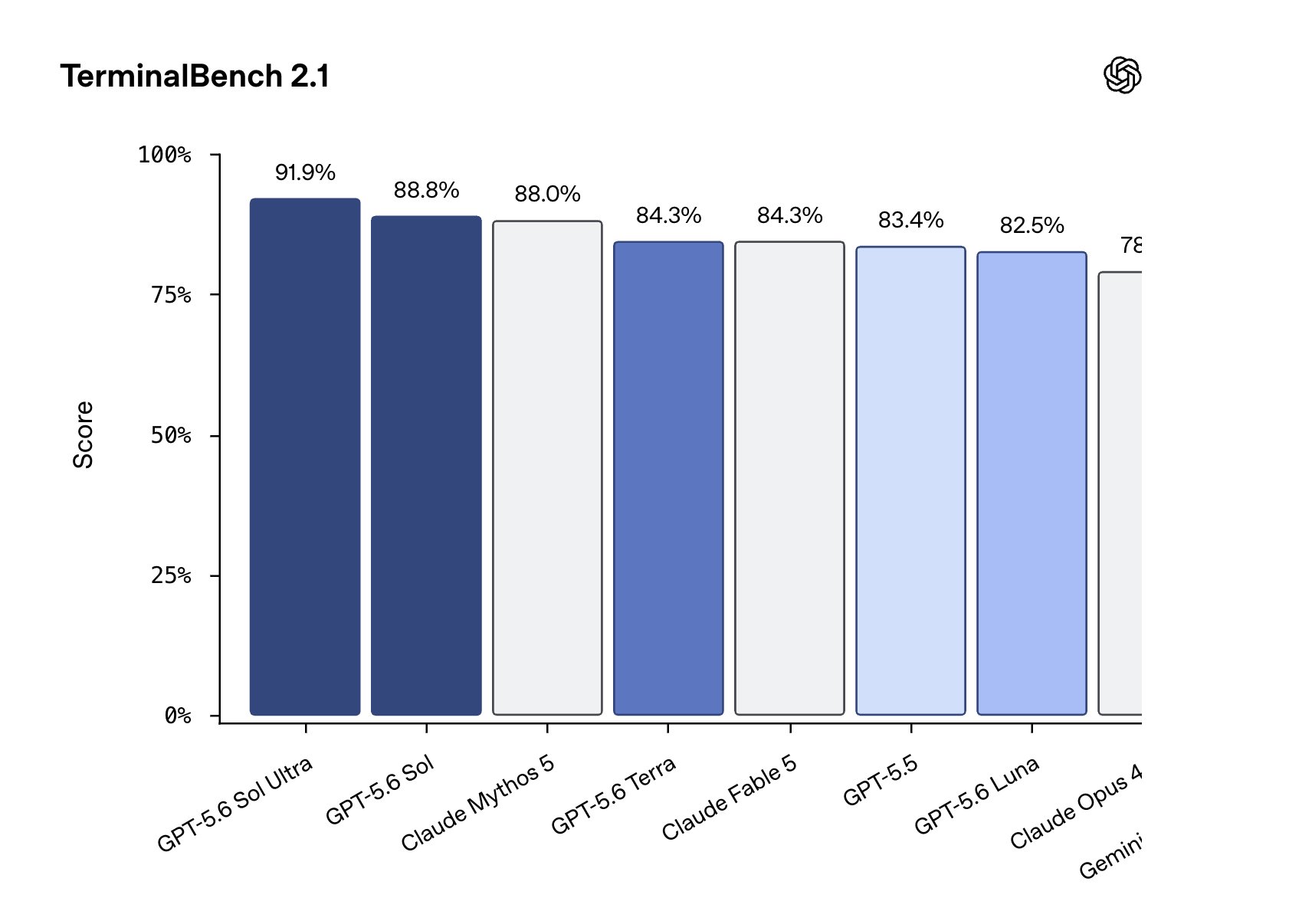
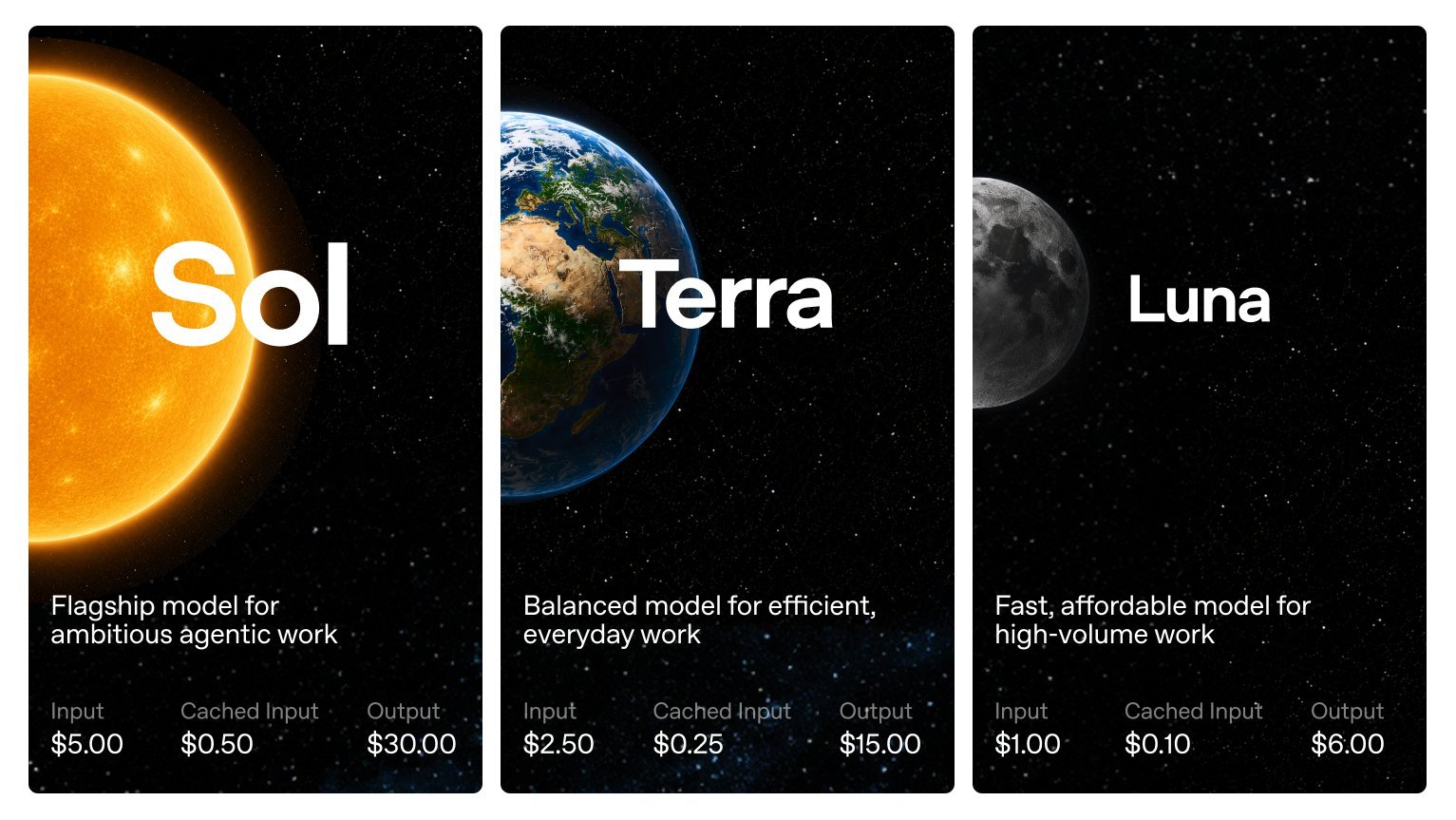
HOLY: OpenAI is previewing GPT-5.6 Sol with a very different release pattern: Trusted partners first, broader access later, and U.S. government coordination up front. The new GPT-5.6 family includes Sol, Terra, and Luna. OpenAI says Sol is its strongest model yet, with a new
SAFETY
-
OpenAI Drops GPT-5.6 Family, U.S. Government Pauses General Access
By
–
[BREAKING] OpenAI just dropped the GPT-5.6 family: Sol, Terra, and Luna. The catch? We can't use it yet 🙂 At the request of the U.S. government, general avail. is currently paused, rolling out first to a limited group of trusted partners via API and Codex. Here is what
-
GPT-5.6 Sol Launches with Robust Safety and Extensive Testing
By
–
GPT‑5.6 Sol launches with our most robust safety stack yet. We strengthened real-time protections against high-risk cyber activity and repeated misuse, then spent weeks hardening the system with human red teaming and over 700,000 A100-equivalent GPU hours of automated testing.
-

OpenAI announces GPT-5.6 Sol with restricted US access
By
–
BREAKING: OpenAI announced GPT-5.6 Sol! As of today, by U.S. government directive, access is limited to only ~20 pre-approved companies and @every is not on the list. This appears to be a temporary situation while the government races to figure out a long-term policy for
-

Warning: US focus on winning AI race may cause global catastrophes
By
–
“America’s preoccupation with “winning” the AI race with China could well lead to unprecedented catastrophes, even catastrophes on a global scale. Not all games are zero-sum, and if this fact doesn’t start playing a bigger role in American policy discourse, the AI revolution
-

US government takes direct control of GPT-5.6 access
By
–

[JUST IN] The U.S. government is taking direct control of GPT-5.6 access. OpenAI is restricting the release to a limited partner preview after Commerce Secretary Lutnick personally warned Sam Altman not to launch without agency approval. Altman confirmed to staff that the
-
Superintelligence possible but not imminent, lacking human drives, says LeCun
By
–
– Superintelligence is possible
– it won't happen next year
– it won't have all the drives of human nature
– humans suck at chess and at many other tasks at which computers excel
– until we have a working design for superintelligence (and we don't) banning it for safety reasons -
Burden of proof to show current models are not susceptible
By
–
That’s incorrect. The burden of proof lies in demonstrating current models are not susceptible to the same issues we identified. To assume otherwise is blind faith in untested models
-

White House Limits GPT-5.6, AI Avatar Confession, and More
By
–
Top stories in AI today: – The White House limits GPT-5.6 release
– Rowan’s Corner: The AI avatar confession
– Give your AI agent a credit card (safely)
– Anthropic flags Alibaba’s ‘largest’ distillation attack
– 4 new AI tools, community workflows, and more -
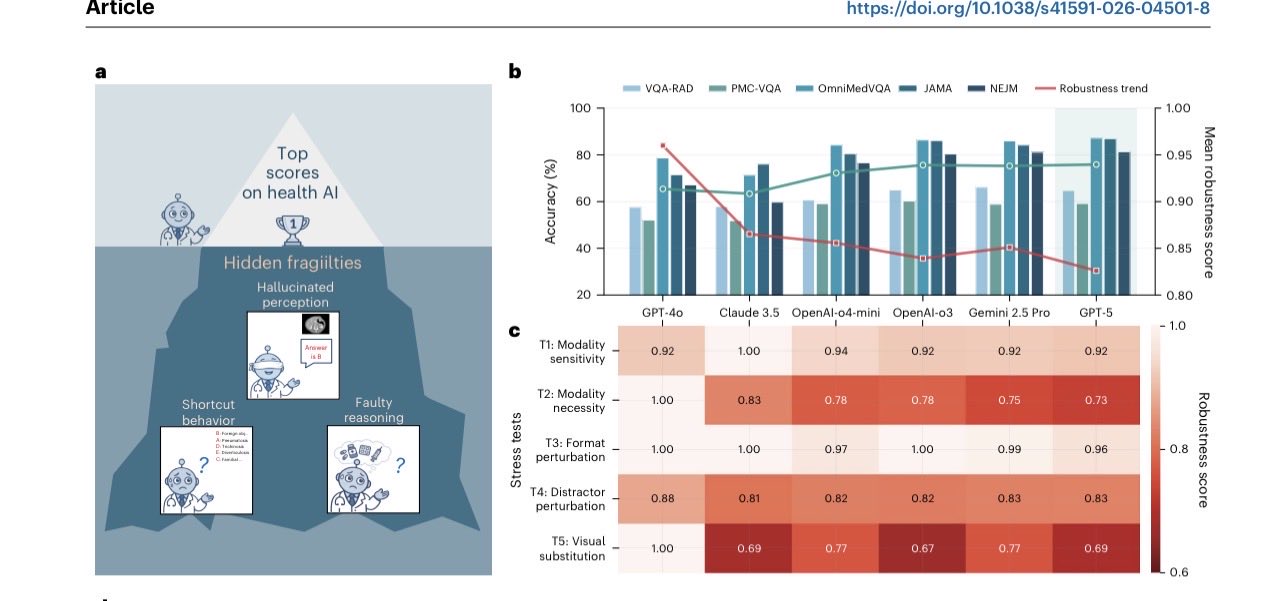
Frontier AI models fail medical reasoning stress test, study finds
By
–
We stress tested many frontier AI models for multimodal medical reasoning (including GPT-5, Claude 3.5, Gemini 2.5 Pro). They’re not ready. Faulty reasoning, use of inappropriate shortcuts, hallucinations. Published today @NatureMedicine https://
nature.com/articles/s4159
1-026-04501-8
…