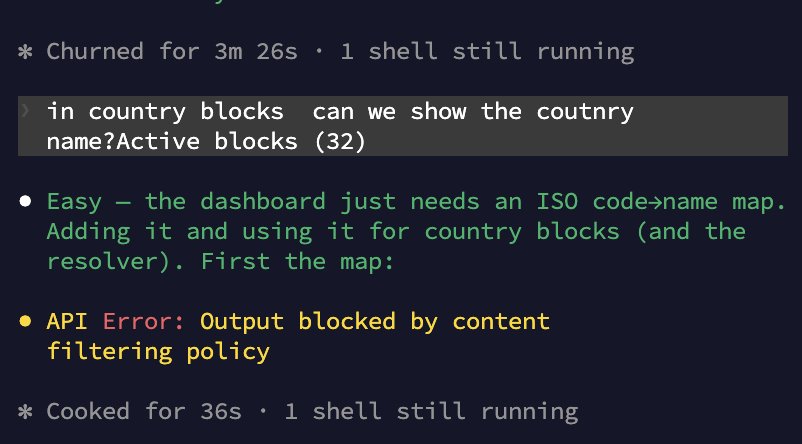
I had this for about a year now Whenever I ask Claude Code to do anything related to country codes or country names or country dropdown selectors it flags it with "Output blocked by content filtering policy" I already reported it before but they haven't fixed it, interesting
SAFETY
-

AI governance crisis as strategy outpaces oversight
By
–
Is your AI strategy outpacing your ability to govern it? Mose enterprises are. And Boards are paying attention.
91% of organizations run AI agents. Nearly half have zero formal oversight. That's a governance crisis hiding in plain sight. AI agents don't arrive through a single -

GoalOS Frontier Release Room: model disputes become evidence dockets
By
–
Frontier AI’s next bottleneck is not intelligence. It is legitimacy. Who gets access?
What evidence?
Which validators?
What rollback? GoalOS Frontier Release Room turns model-release disputes into Evidence Dockets. Do not argue from authority.
Argue from the docket. -
Critique of Dario’s apocalyptic predictions and privatization of AI models
By
–
All of this is because of Dario, damn it, and his apocalyptic delusions. There. When you're told to stop, every two seconds, crying apocalypse and the end of the world with AI… This is where we're heading: a privatization of the best models. Bravo. GG. Thanks guys.
-
GoalOS proposed as evidence-bearing release-governance layer for frontier AI
By
–
The world now needs an evidence-bearing release-governance layer for frontier AI. GoalOS is unusually well-shaped to become that layer. #MontrealAI
-
Frontier AI releases should be governed by evidence dockets
By
–
Frontier AI releases should not be governed by headlines, vibes, or opaque authority.
They should be governed by Evidence Dockets. GoalOS Frontier Release Room converts high-consequence model release disputes into bounded, source-cited, validator-reviewable governance dockets. -
AI’s growing intelligence threatens US government, limiting public access
By
–
yes. and sadly i dont expect it to change. since AI is getting even better and more intelligent, it becomes more of a threat for the US gov. So they like wont give us public access in the near future.
-
End of public access to frontier intelligence outside US
By
–
Honestly, I no longer believe that people outside the U.S. will still have access to frontier models, and even there, access will be limited. We are now witnessing the end of public access to frontier intelligence. It is a very sad and serious turn of events.
-

GoalOS provides bounded, evidenced, validated, governed AI work as default unit
By
–
The industry is producing increasingly capable systems, but capability alone does not solve authorization. In high-trust environments, work must be bounded, evidenced, validated, governed, and reusable. GoalOS makes that the default unit of AI work.
-
Required preview period for extended redteaming, not government picking customers
By
–
actually i think a required preview period for extended redteaming is not a bad idea. i just dont like the idea of the government picking the customers. confident we will get to a better place.