next step: post-training your own models based on open-source!
@clementdelangue
-

AI concentration risk demands rebel alliance against power and wealth
By
–
The biggest risk in AI is concentration: of power, capabilities and economic wealth. Who can doubt it with trillion dollar companies and government now already controlling a massive part of it? So we need more rebels and more rebel alliance like this one from @usv and friends.
-
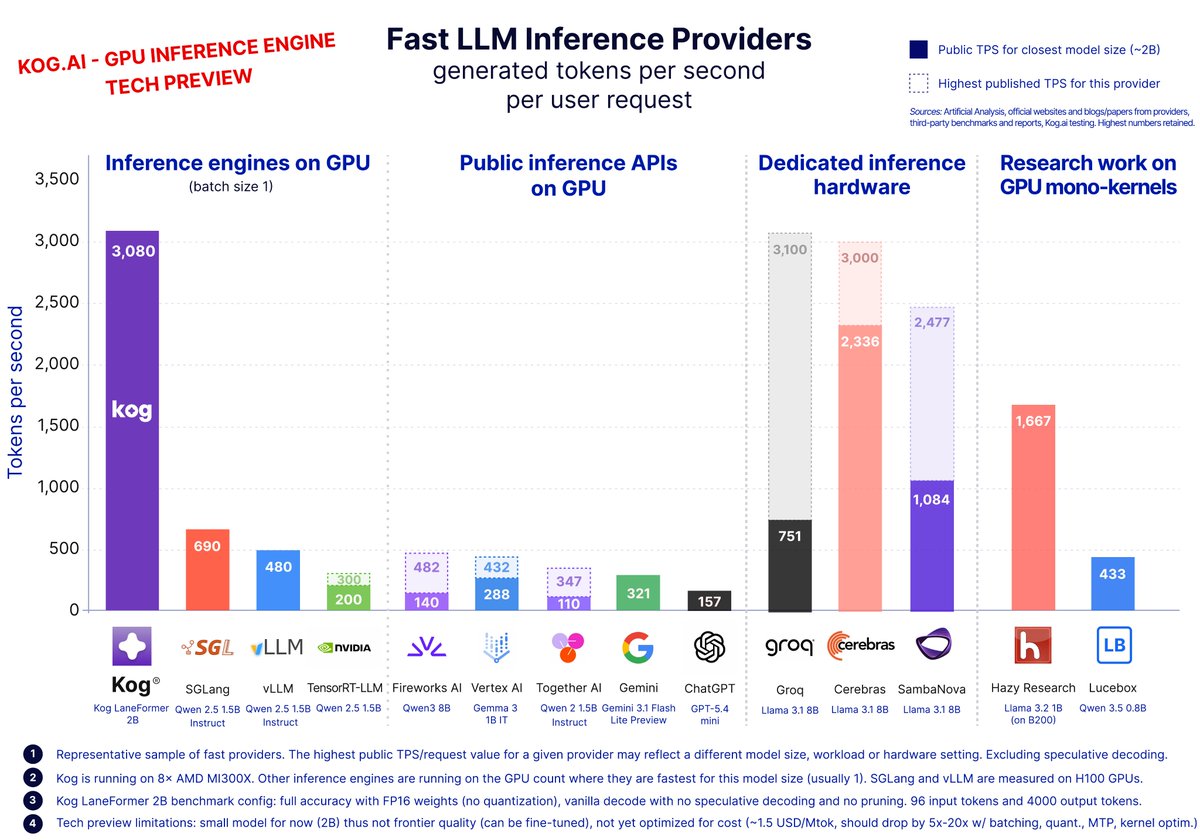
Kog publishes an ultra-fast 2B model on Hugging Face
By
–
Kog has open-sourced on @huggingface the 2B model they used to demonstrate a model running at over 3,000 tokens per second. Very cool work! https://huggingface.co/blog/kogai/kog-laneformer-2b-the-latency-first-model …
-
Hugging Face to surpass 3M public models and 1M datasets
By
–
We are about to surpass 3M public models & 1M public datasets on @huggingface in a few days. Open-source AI is on fire!
-
AI Domination: Open-source then General, and What’s Next?
By
–
– 2016-2024: dominates open-source AI
– 2024-2027: dominates general AI and benefits massively from it – 2024-2026: dominates open-source AI
– 2026-2030: ?? It is not the domination of open-source AI OR the domination of general AI, it is the domination of AI -
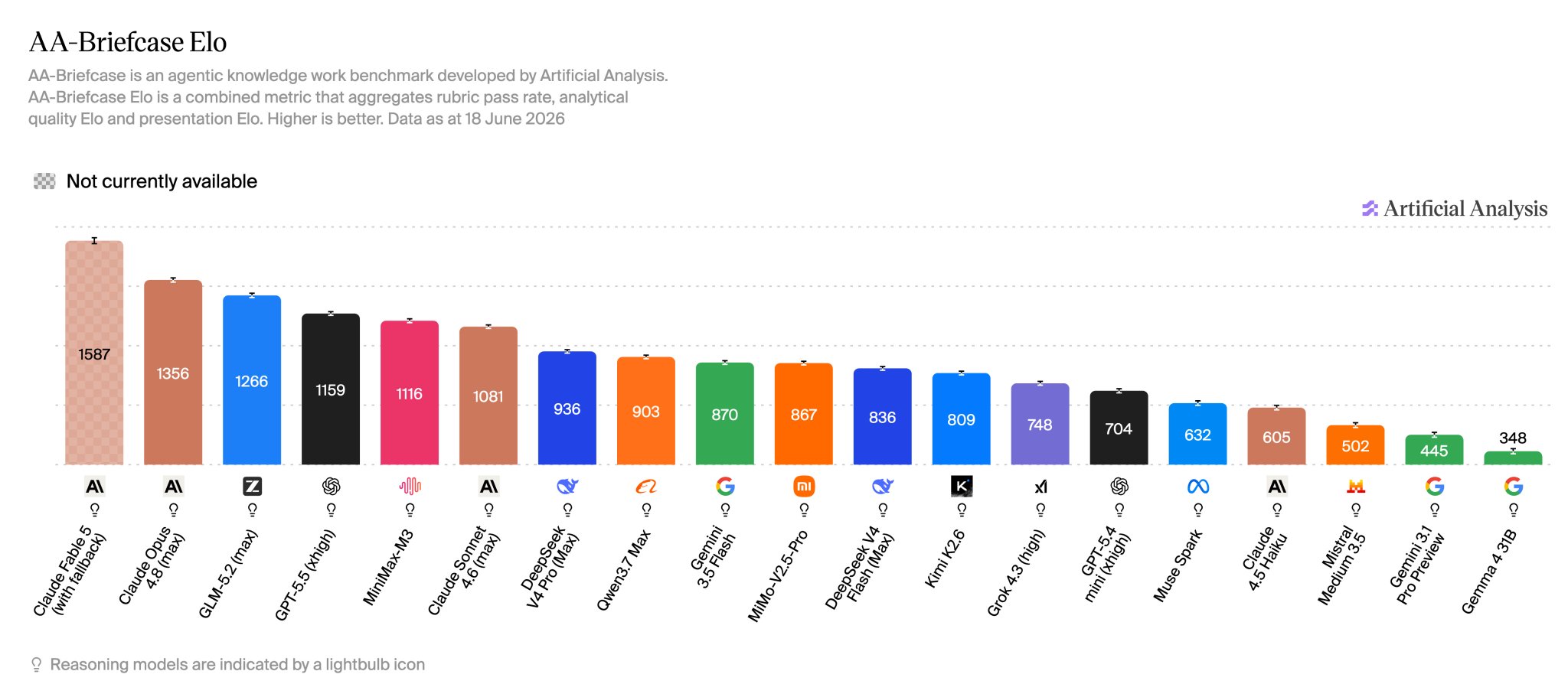
800x cost difference per task between AI models
By
–
The cost per task varies by a factor of ~800x depending on the models tested: Claude Fable 5 dominates the benchmark but costs over $31 per task on average, compared to ~$0.04 for DeepSeek V4 Flash (max). The best options in terms of price/performance ratio are the models
-
Ineffective a posteriori API guardrails for cutting-edge models
By
–
Let's face the truth: a posteriori API guardrails are not the appropriate safety tool for cutting-edge models. They do not eliminate dangerous capabilities. They simply hide them behind a fragile interface that can be easily
-
Open weights become the default configuration
By
–
"Open weights are now our default configuration"
https://huggingface.co/collections/poolside/laguna-m1
… -
Discussion in DC on open-source AI, transparency, and concentration
By
–
I decided to go to DC next week to discuss directly with policymakers. Not sure about the impact it will have, but with everything going on, it seems like a good time to speak more about open-source AI, transparency, the concentration of
-

ABC-130k dataset on Hugging Face, massive and cool
By
–
Very cool and massive dataset on @huggingface of course: https://huggingface.co/datasets/XDOF/ABC-130k … !