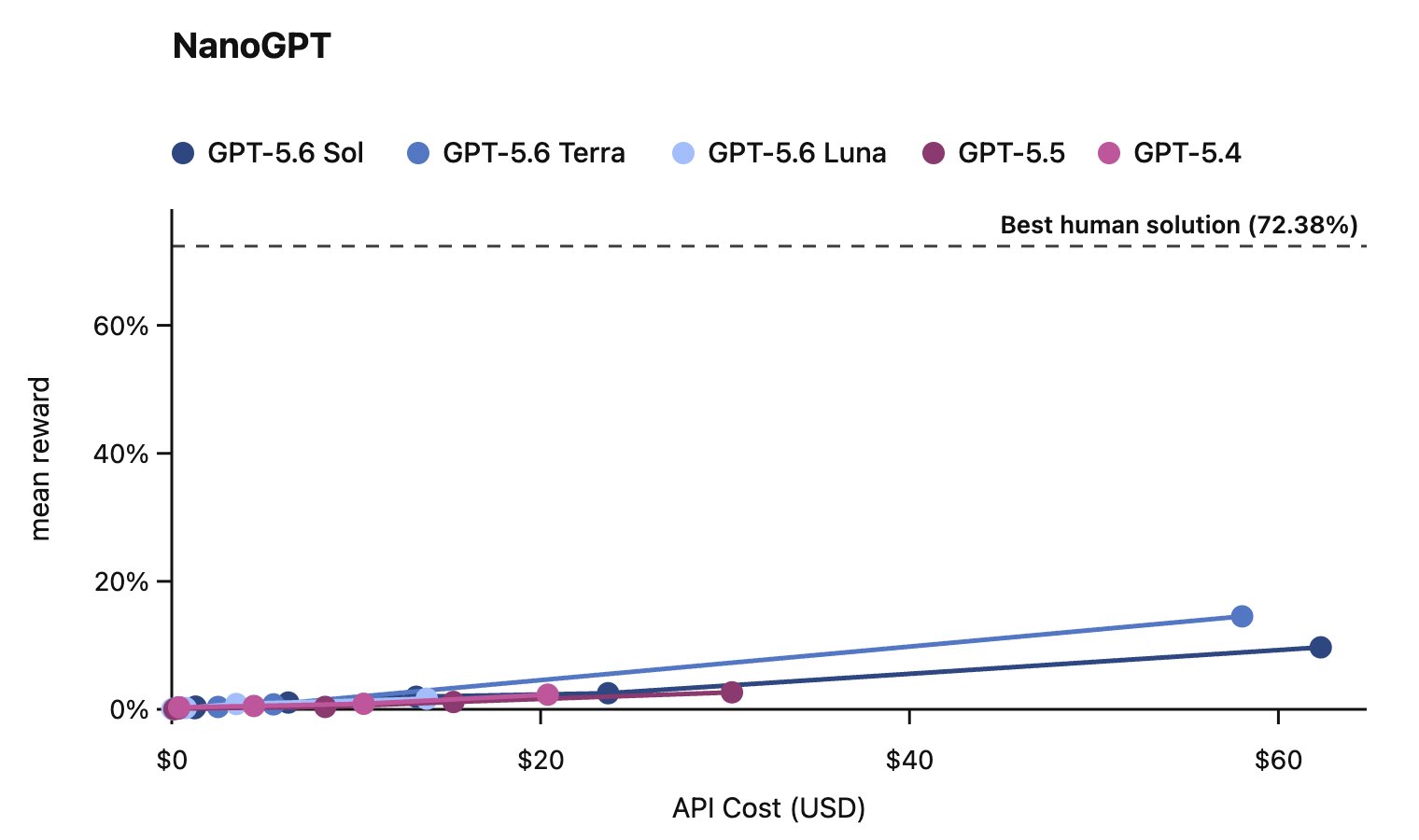
That's my general experience with the models right now, they are just not good researchers – they come up with bad ideas, calibrating them poorly, getting too bogged down in the details and not stepping back to see what they've learned. Humans are way better at this.
RESEARCH
-
Cerebras to share more Gemma 4 31B information updates
By
–
We will update more Gemma 4 31B information as we go! https://
inference-docs.cerebras.ai/models/gemma-4
-31b
… -
Academia more scandalized by AI-assisted papers than false
By
–
This implies that academia would be more scandalized by papers being AI-assisted than them being merely false. … That is, regrettably, very plausible to me.
-
AGI closeness: models to innovate independently, says OpenAI chief
By
–
How close is AGI?@OpenAI Chief Research Officer @markchen90 discusses what the future of model capabilities looks like: "We're getting closer and closer to a world where the models can come up with more of the innovation on their own." https://t.co/SmIypV0ZS0 pic.twitter.com/UPnRtdRrF2
— Latent.Space (@latentspacepod) 26 juin 2026How close is AGI? @OpenAI Chief Research Officer @markchen90 discusses what the future of model capabilities looks like: "We're getting closer and closer to a world where the models can come up with more of the innovation on their own."
-
GoalOS proposed as evidence-bearing release-governance layer for frontier AI
By
–
The world now needs an evidence-bearing release-governance layer for frontier AI. GoalOS is unusually well-shaped to become that layer. #MontrealAI
-
No more frontier models will be released
By
–
Im not saying we aren’t getting any more models. I’m saying: we won’t get frontier any more.
-
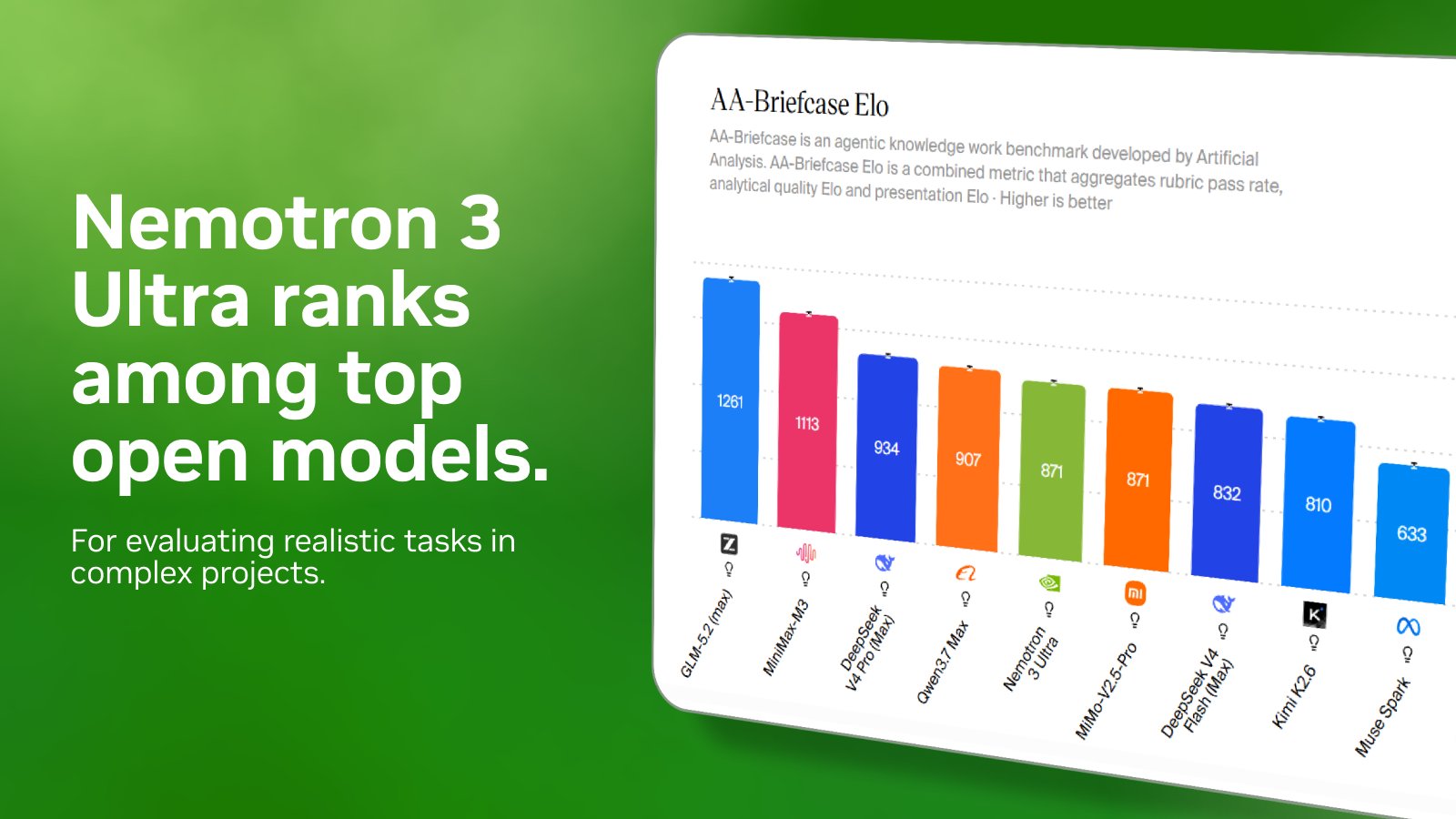
AA-Briefcase leaderboard for realistic tasks; Nemotron 3 Ultra top
By
–
.
@ArtificialAnlys just dropped a brand new leaderboard called AA-Briefcase for evaluating realistic tasks in complex projects. Nemotron 3 Ultra ranks among the top open models, with strong performance across a wide range of long-running agentic tasks, even when encountering them -
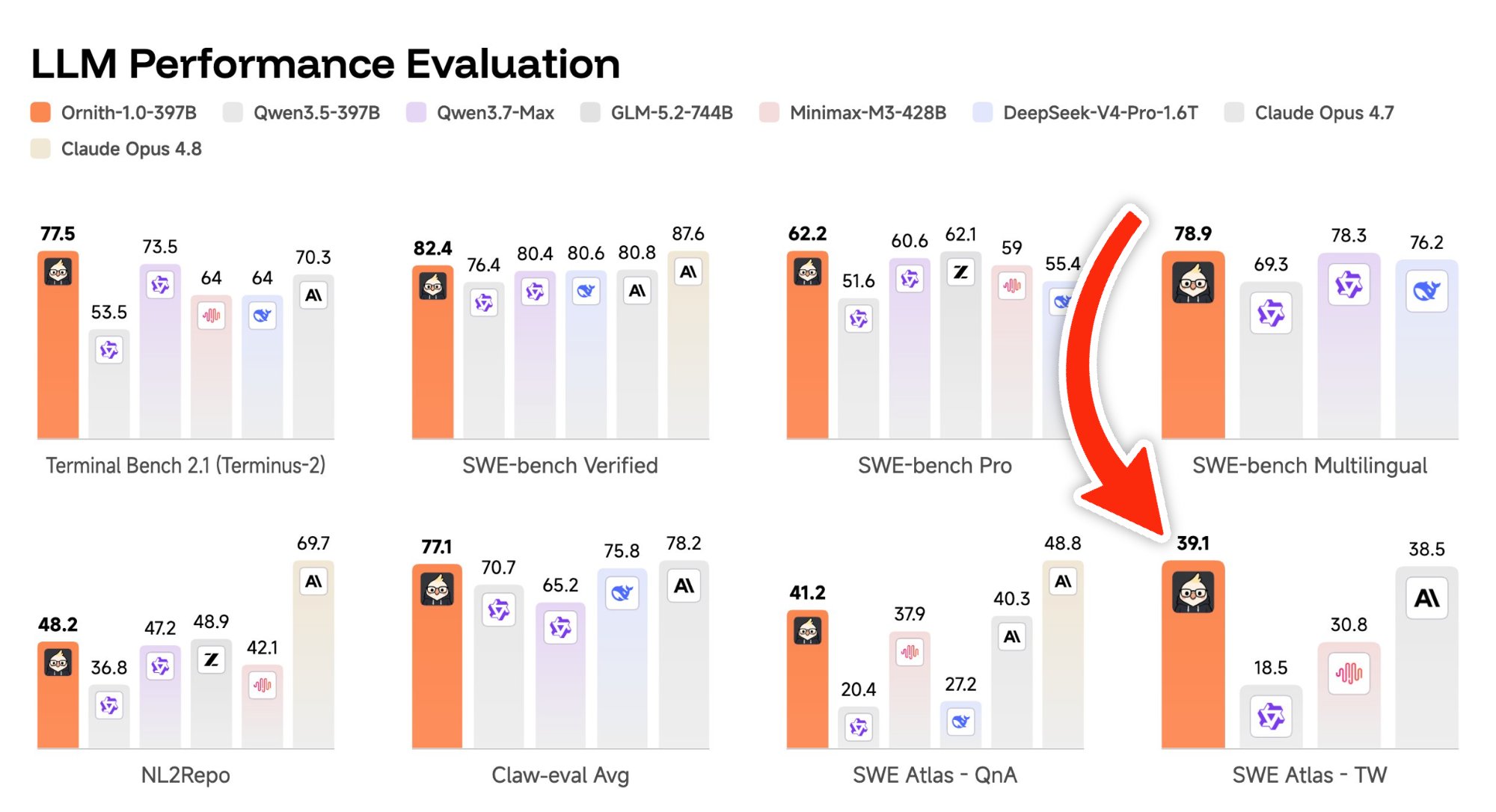
@ornith_ model matches or beats Claude Opus 4.8
By
–
HOLY SH*T this @ornith_ model is matching or even beating Claude Opus 4.8 I definitely need to move this up my priority list for a deep dive
-
Model @ornith_ matches or beats Claude Opus 4.8 performance
By
–
HOLY SH*T this @ornith_ model is matching or even beating Claude Opus 4.8 I definitely need to move this up my priority list for a deep dive