huggingface.co/LiquidAI/LFM2… [Translated from EN to English]
→ View original post on X — @maximelabonne, 2026-02-24 17:48 UTC
By
–
huggingface.co/LiquidAI/LFM2… [Translated from EN to English]
→ View original post on X — @maximelabonne, 2026-02-24 17:48 UTC
By
–
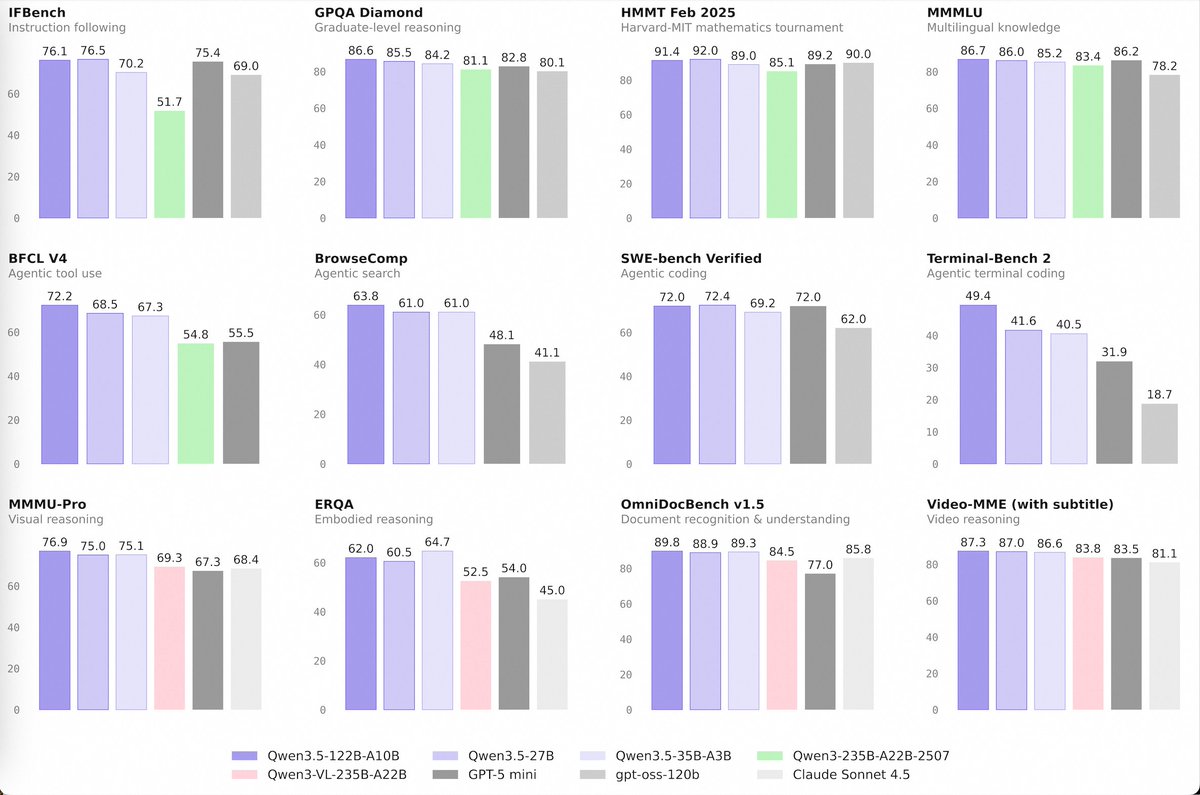
Releasing a 24B-A2B model on the same day as Qwen3.5-35B-A3B is NOT great timing 🥲 Qwen (@Alibaba_Qwen) 🚀 Introducing the Qwen 3.5 Medium Model Series Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B ✨ More intelligence, less compute. • Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts. • Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios. • Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring: – 1M context length by default – Official built-in tools 🔗 Hugging Face: huggingface.co/collections/Q… 🔗 ModelScope: modelscope.cn/collections/Qw… 🔗 Qwen3.5-Flash API: modelstudio.console.alibabac… Try in Qwen Chat 👇 Flash: chat.qwen.ai/?models=qwen3.5… 27B: chat.qwen.ai/?models=qwen3.5… 35B-A3B: chat.qwen.ai/?models=qwen3.5… 122B-A10B: chat.qwen.ai/?models=qwen3.5… Would love to hear what you build with it. — https://nitter.net/Alibaba_Qwen/status/2026339351530188939#m
→ View original post on X — @maximelabonne, 2026-02-24 17:01 UTC
By
–
Meet LFM2-24B-A2B, @liquidai's largest model. 24B MoE, 2B active. Blazing fast even on CPU. Available now in LM Studio 👾💧 lmstudio.ai/models/lfm2-24b-…
→ View original post on X — @maximelabonne, 2026-02-24 15:44 UTC
By
–
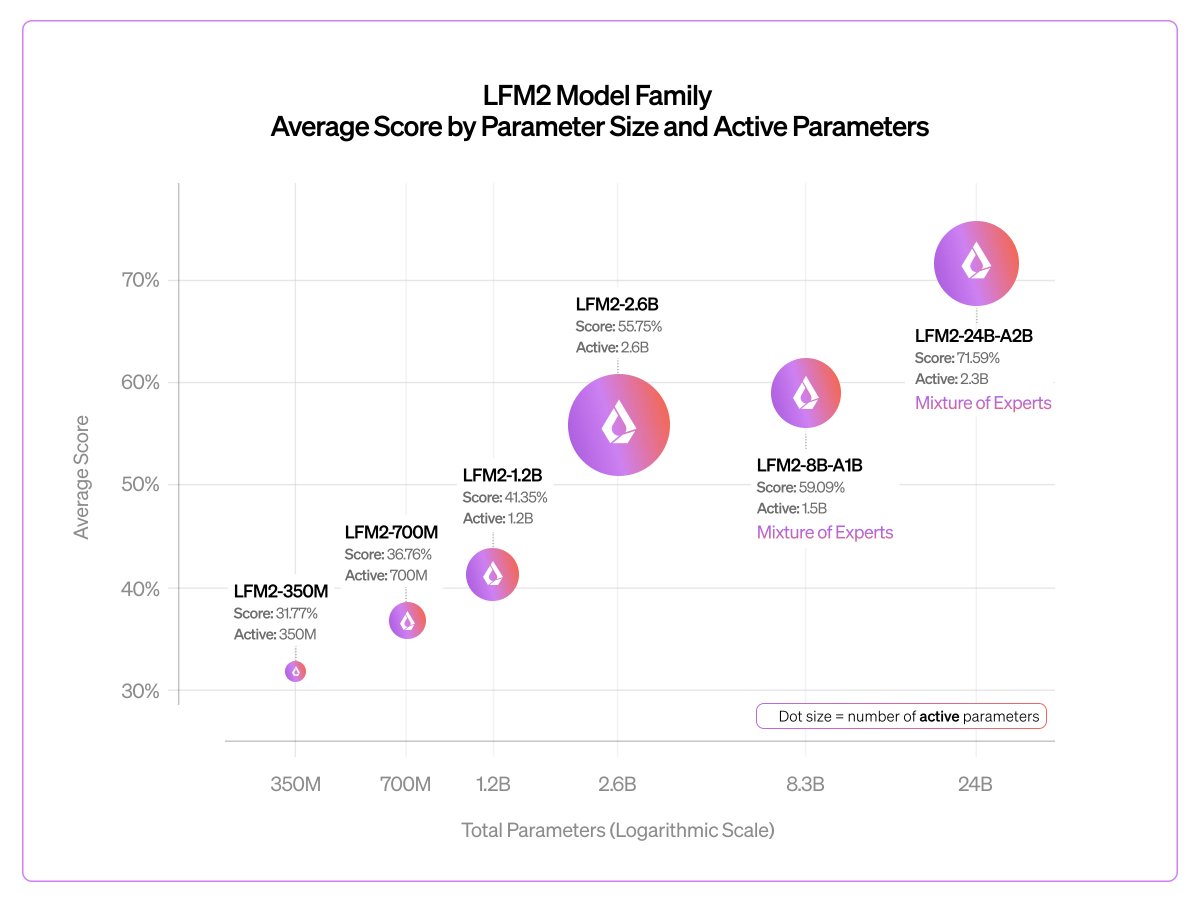
ollama run lfm2:24b-a2b .@liquidai's latest on-device model is here! It's the largest LFM2 model yet, and is designed to run fast on device, and fits on devices with 32GB of unified memory. Liquid AI (@liquidai) Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘 > 24B total parameters > 2.3B active per token > Built on our hybrid, hardware-aware LFM2 architecture It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate each run. The result: best-in-class efficiency, fast edge inference, and predictable log-linear scaling all in a 32GB, 2B-active MoE footprint. 🧵 — https://nitter.net/liquidai/status/2026301771539202269#m
→ View original post on X — @maximelabonne, 2026-02-24 14:36 UTC
By
–
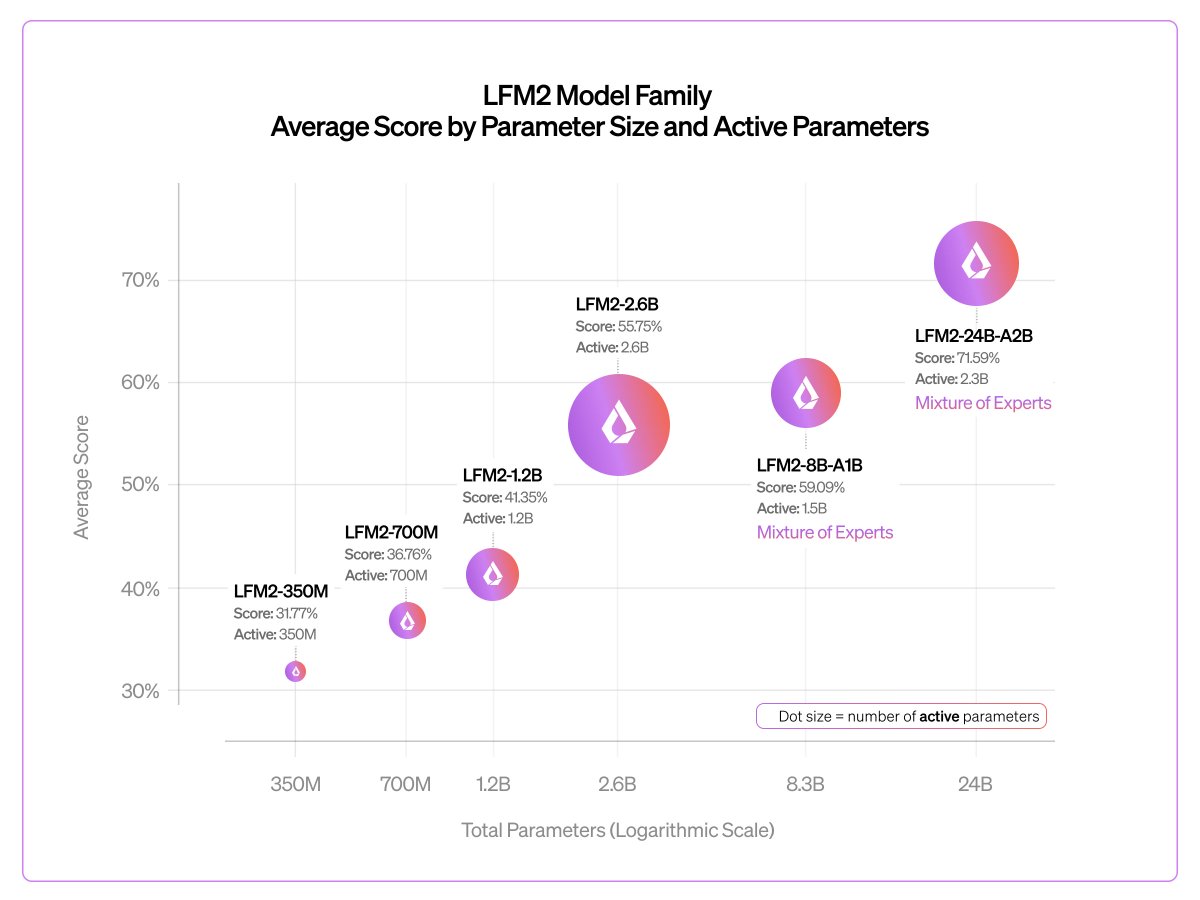
Early checkpoint of our biggest LFM2 model to date 🎉 It shows good scaling and extremely fast inference vs. gpt-oss-20b and Qwen3-30B-A3B We'll release an LFM2.5 version with more pre-training and RL in a few months Liquid AI (@liquidai) Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘 > 24B total parameters > 2.3B active per token > Built on our hybrid, hardware-aware LFM2 architecture It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate each run. The result: best-in-class efficiency, fast edge inference, and predictable log-linear scaling all in a 32GB, 2B-active MoE footprint. 🧵 — https://nitter.net/liquidai/status/2026301771539202269#m
→ View original post on X — @maximelabonne, 2026-02-24 14:31 UTC

By
–

Great application of skills: post-train models directly from Claude Code or Codex. No code, no GPU required. We fine-tuned LFM2.5-1.2B-Instruct with just a prompt 👀 Ben Burtenshaw (@ben_burtenshaw) You can finetune AI models with Unsloth + Hugging Face, and right now it’s free! We're giving away GPU credits on HF Jobs + Unsloth. Train a 1.2B model like @liquidai LFM2.5-1.2B with one command. Ship it to your phone, laptop, or API. No infra. No setup. Just prompt your coding agent and go. — https://nitter.net/ben_burtenshaw/status/2024552060558229858#m
→ View original post on X — @maximelabonne, 2026-02-19 18:47 UTC

By
–
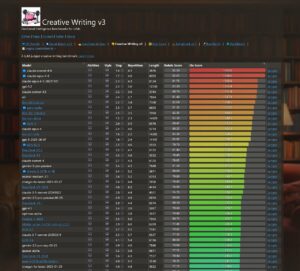

Sonnet-4.6 takes top place on all my evals: EQ-Bench, Creative writing, Longform writing & Judgemark. Opus 4.6 within margin of error. GLM-5 and Qwen3.5-397B nipping at their heels.
→ View original post on X — @maximelabonne, 2026-02-18 21:33 UTC
By
–
It's surprising that it still manages to output such a consistent ranking. Are they simply evaluating on a fraction of the dataset, effectively?
By
–
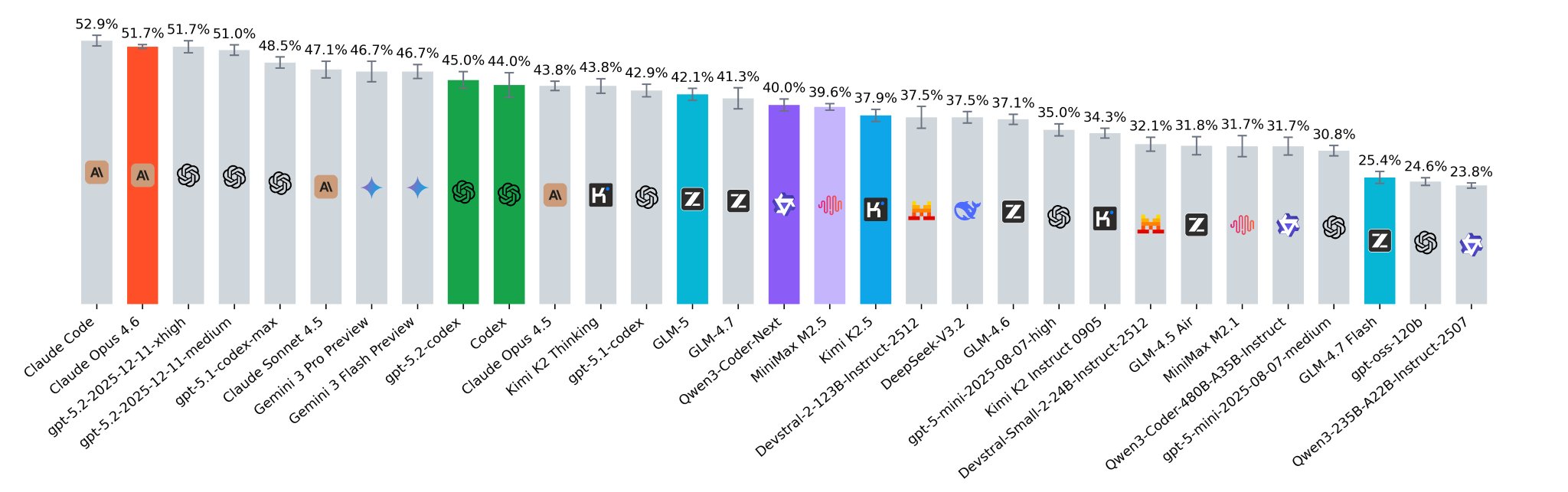
The eval is probably not perfect, so please just consider it as an additional signal https://
swe-rebench.com/?insight=jan_2
026
…
By
–
Oof, SWE-rebench is brutal for recent Chinese releases M2.5 reported 80.2% on SWE-bench verified against 80.8% for Opus 4.6, but it seriously underperforms here Qwen3-Coder-Next looks good with 40% and only 80B A3B parameters