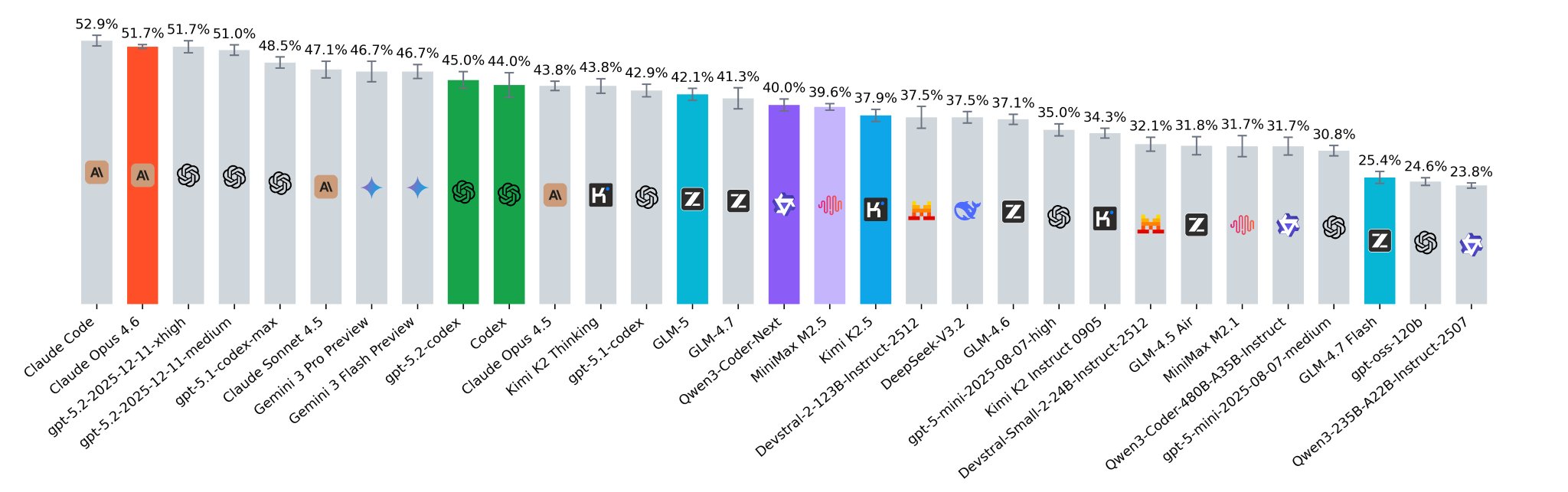
Oof, SWE-rebench is brutal for recent Chinese releases M2.5 reported 80.2% on SWE-bench verified against 80.8% for Opus 4.6, but it seriously underperforms here Qwen3-Coder-Next looks good with 40% and only 80B A3B parameters
Chinese LLMs Performance on SWE-bench: M2.5 Underperforms Opus
By
–