
Fun surprise: DeepSeek used my open-perfectblend dataset to train their new DSpark drafter Time to promote it again! It's an open-source reproduction of "The Perfect Blend" paper. If you ever need >1M diverse prompts in math, chat, and code, it does the job.
@maximelabonne
-
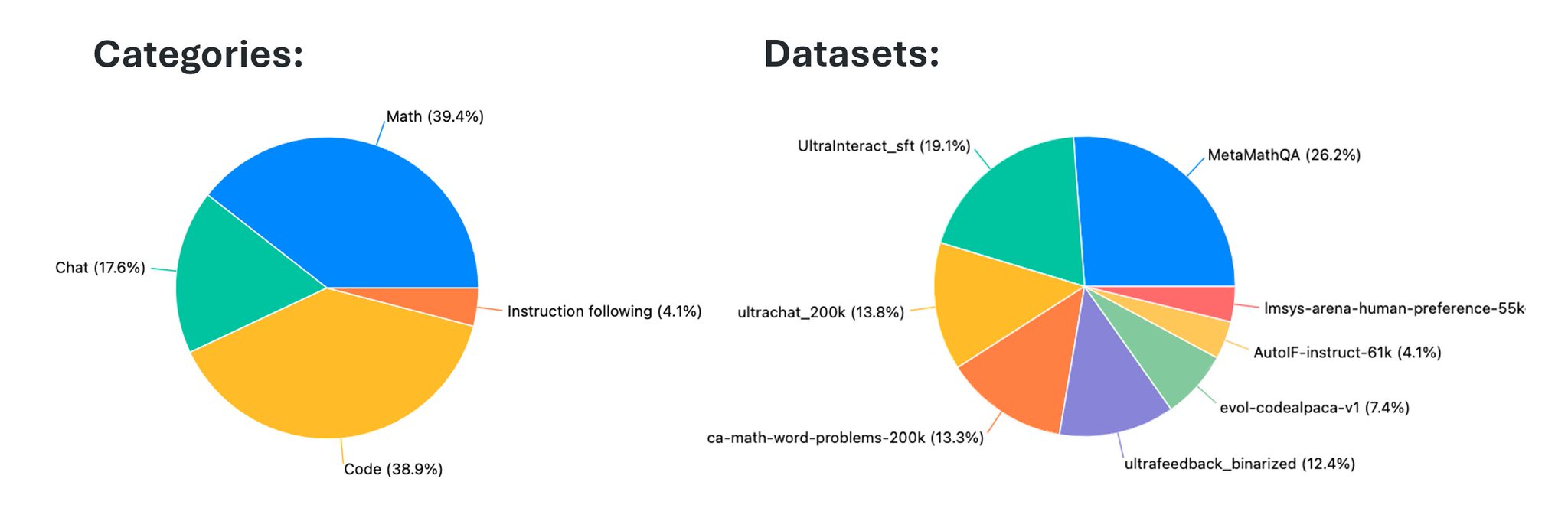
Reuse of Chat, Math, Code categories in open-perfectblend dataset
By
–
Wow, they really reused the three main categories Chat / Math / Code as well https://
huggingface.co/datasets/mlabo
nne/open-perfectblend
… -
Fine-tuning and structured decoding for data extraction
By
–
Yes, for data extraction, I recommend fine-tuning it for your use case (TRL or Unsloth) + using structured decoding (
@dottxtai
) during inference. We'll release something on this topic very soon! -
New tiny LFM2.5-230M model for ultra-low latency robotics and e-commerce
By
–
Here's our new, tiniest model: LFM2.5-230M! 🥳
— Maxime Labonne (@maximelabonne) 25 juin 2026
We went even smaller to power ultra-low latency use cases like e-commerce and robotics.
Here's a demo of LFM2.5-230M running on a Unitree G1, decomposing user prompts into a sequence of tool calls.
Available today on @huggingface! https://t.co/JiuSWnwZCs pic.twitter.com/5PuSamwZLRHere's our new, tiniest model: LFM2.5-230M! We went even smaller to power ultra-low latency use cases like e-commerce and robotics. Here's a demo of LFM2.5-230M running on a Unitree G1, decomposing user prompts into a sequence of tool calls. Available today on @huggingface
! -
ColBERT outperforms on CPU with low latency for embeddings
By
–
I'm talking about individual descriptions used for embeddings. It doesn't need to be particularly long for late interaction to perform better. The tradeoff really depends on the use case. In this case, even on a cheap CPU, the latency is so low that ColBERT just works better!
-
ColBERT more accurate than embedding model with long tool descriptions and prompts
By
–
Yes, it also works well with the embedding model, but ColBERT is a bit more accurate thanks to long tool descriptions + prompts.
-
LFM2.5-ColBERT-350M reliably selects top 5 tools from 151
By
–
LFM2.5-ColBERT-350M is a surprisingly reliable smart tool selector.
— Maxime Labonne (@maximelabonne) 18 juin 2026
We gave it 151 tools, and it consistently surfaces the 5 most relevant ones based on the user prompt.
This saves tokens and improves accuracy. Ideal for hmmmm agentic edge models? 👀 pic.twitter.com/IPyizctesULFM2.5-ColBERT-350M is a surprisingly reliable smart tool selector. We gave it 151 tools, and it consistently surfaces the 5 most relevant ones based on the user prompt. This saves tokens and improves accuracy. Ideal for hmmmm agentic edge models?
-
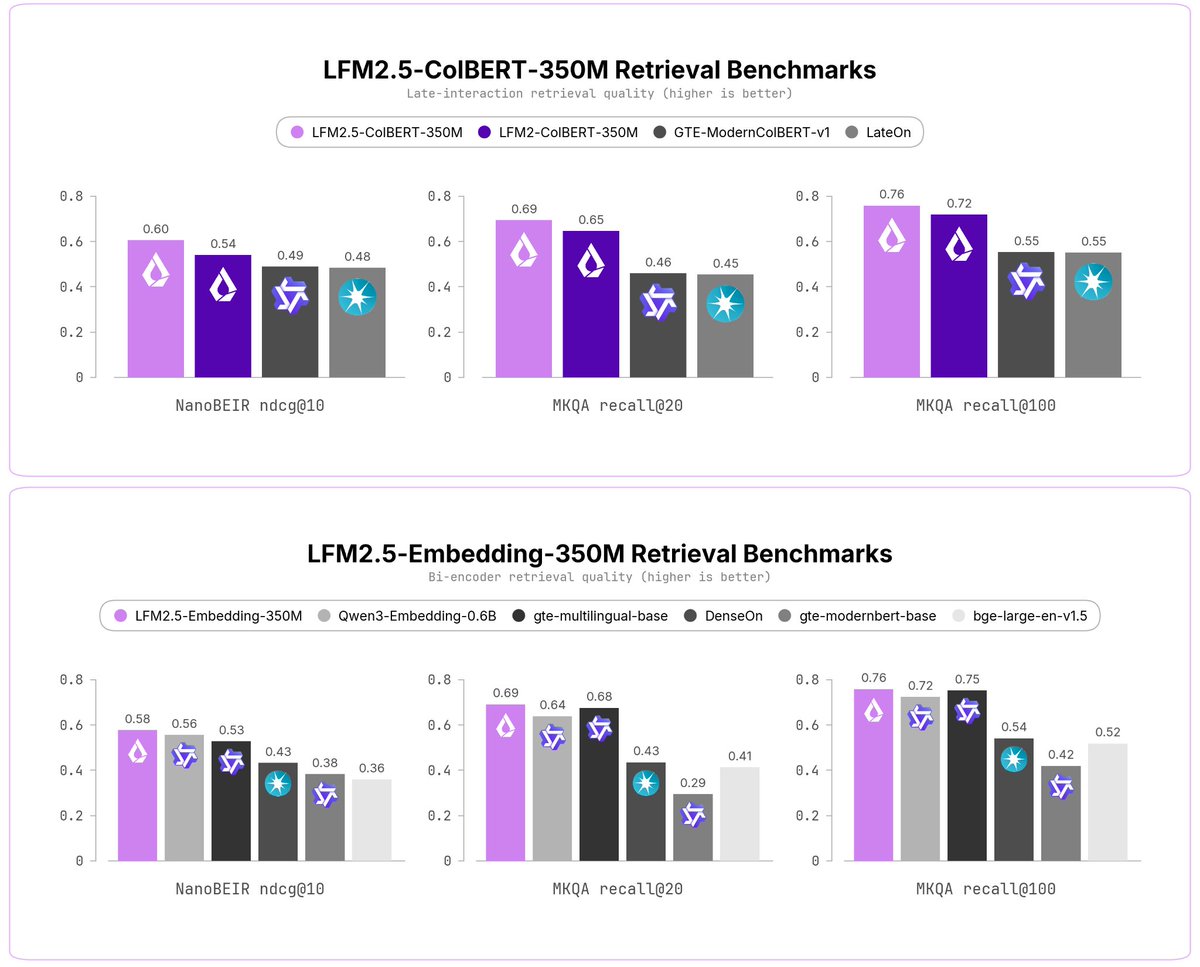
Causal decoder patched to bidirectional encoder excels in multilingual tasks
By
–
We patched LFM2.5-350M (pre-trained on 28T tokens) to transform a causal decoder into a bidirectional encoder. It worked extremely well: both Embedding and ColBERT models get best-in-class performance, especially for multi/cross-lingual tasks.
-
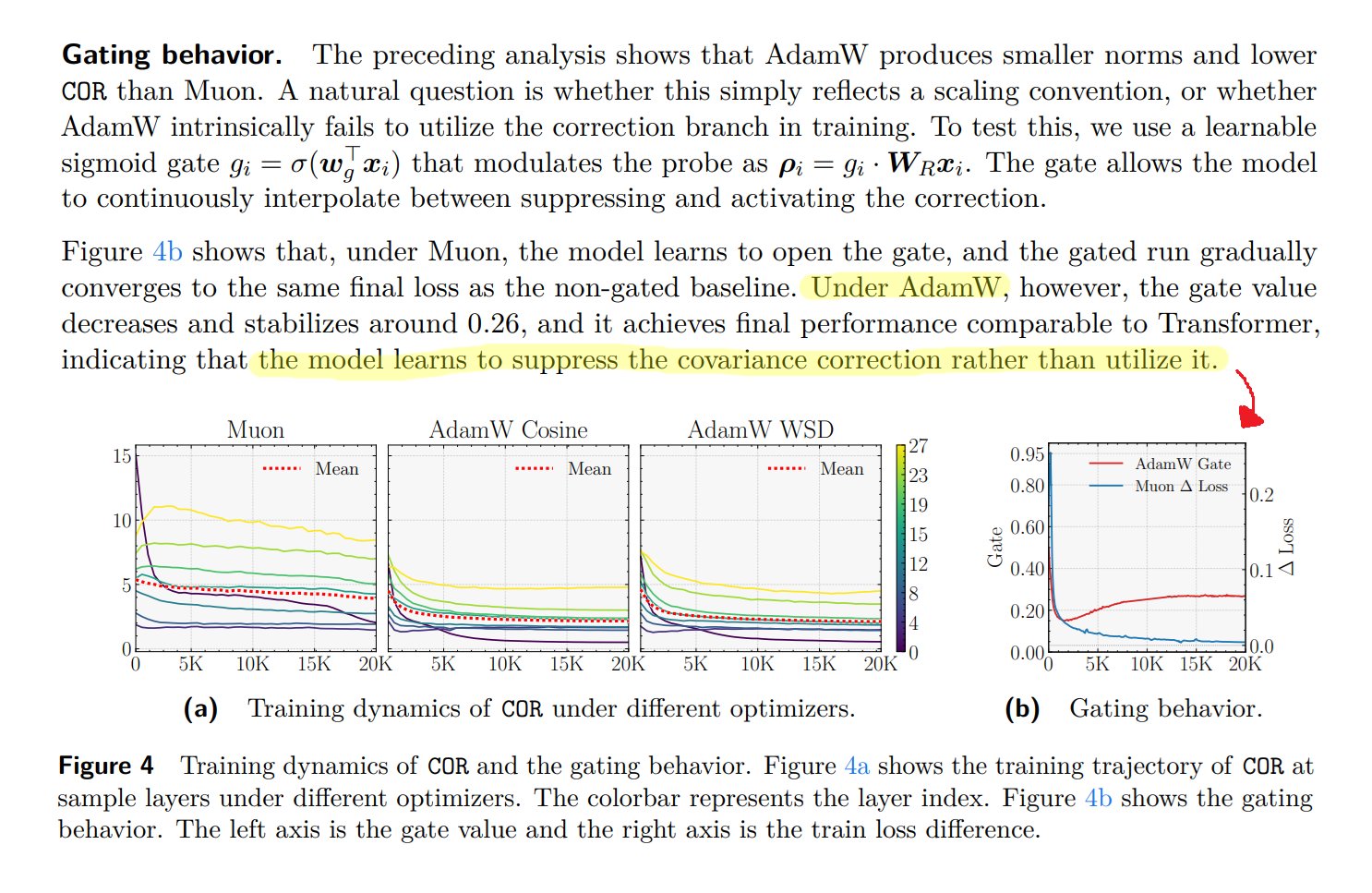
Parallax: Local Linear Attention matches FA 2/3 when using Muon
By
–
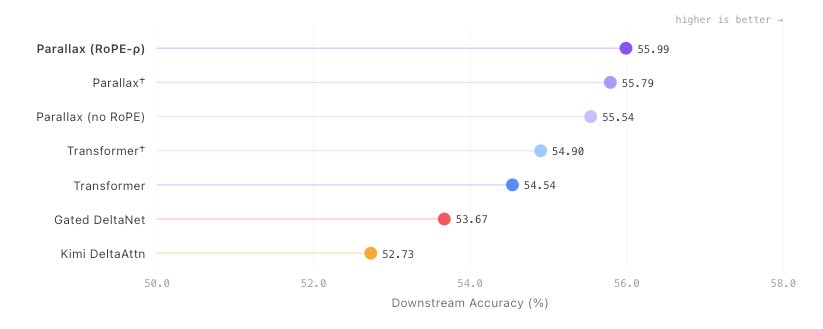
Parallax is a parametrized form of Local Linear Attention that drops the numerical solvers and matches FA 2/3 on decode. The most impressive part is that the architecture's benefit works with Muon but disappears under AdamW because the model learns to suppress it. It's