
Reject big models, embrace small memory footprint
@maximelabonne
-
AI Model Now Available on Hugging Face Platform
By
–
The model is available today on @huggingface with examples and a quick start tutorial!
-

AMD Ryzen AI MAX+ 395 Delivers Impressive Fast Processing Speed
By
–
You also get faster processing time for free. The AMD Ryzen AI MAX+ 395 was really, really fast.
-
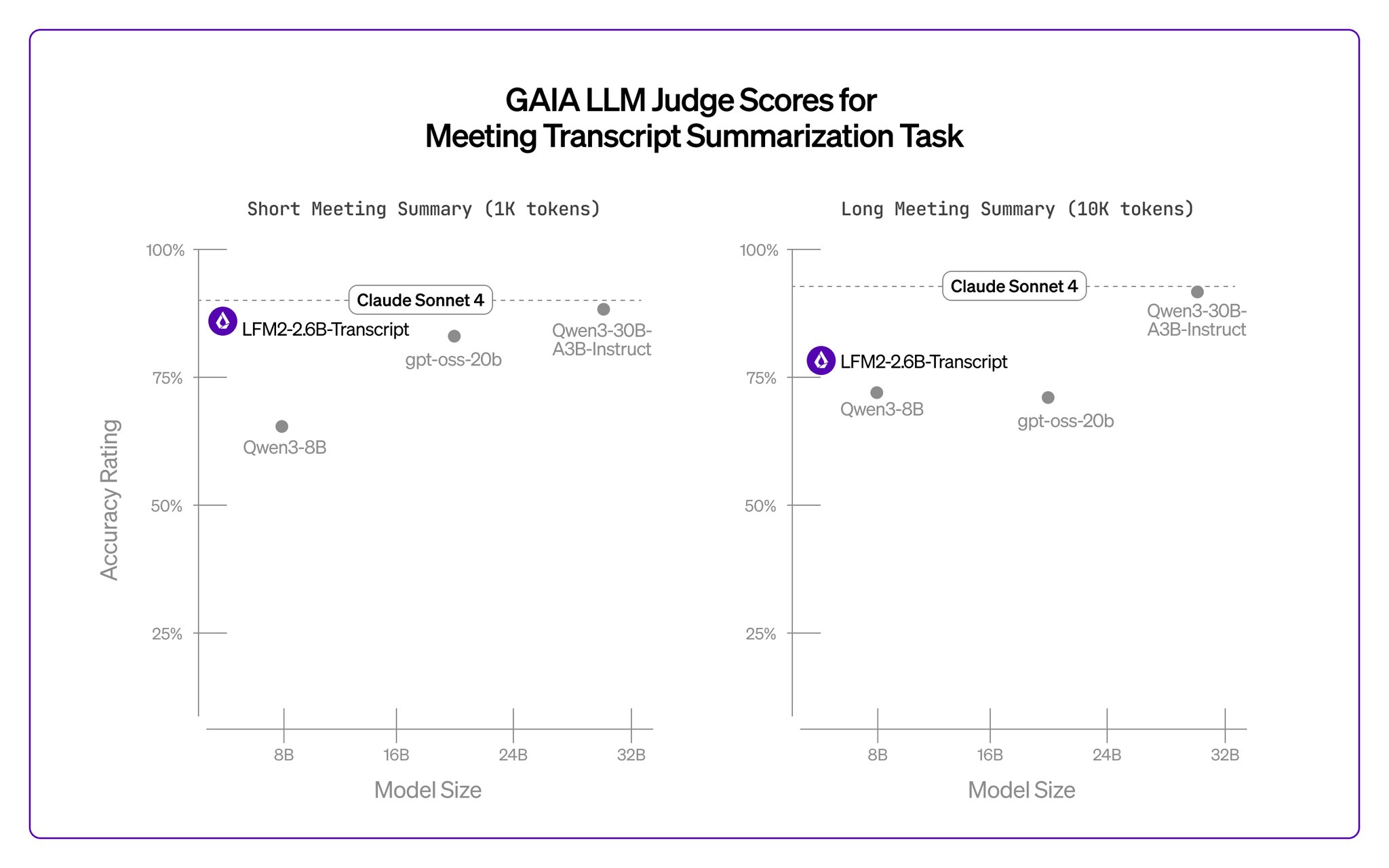
AMD Evaluates 2.6B Language Model Performance with GAIA Framework
By
–
Nice bit: the 2.6B works well, even with long meetings with 10k tokens It was a pleasure working with the AMD team, who evaluated all the models with their GAIA framework
-
LFM2-2.6B: On-Device Meeting Summarization with Cloud Quality
By
–
LFM2-2.6B-Transcript @AMD🤝@liquidai
— Maxime Labonne @ ICLR (@maximelabonne) 7 janvier 2026
> Private, on-device meeting summarization
> Cloud-level quality
> Faster processing, lower memory footprint
> Runs across CPU, GPU, and NPU on AMD Ryzen AI PC
Great showcase of what tiny models can achieve when fine-tuned pic.twitter.com/5kQXfE9j1fLFM2-2.6B-Transcript @AMD
@liquidai > Private, on-device meeting summarization
> Cloud-level quality
> Faster processing, lower memory footprint
> Runs across CPU, GPU, and NPU on AMD Ryzen AI PC Great showcase of what tiny models can achieve when fine-tuned -
AI Benchmarks Threaten Job Security and Professional Safety
By
–
You always think you're safe until your job becomes a benchmark.
-
Latent Fine-Tuning: Customizing Models at Inference Time
By
–
Beyond removing refusals, I hope these techniques can be used for "latent fine-tuning" to customize models at inference time.
-
Heretic 1.1: Open-Source LLM Abliteration Library Evolution
By
–
Abliterate LLMs with Heretic 1.1
— Maxime Labonne @ ICLR (@maximelabonne) 11 décembre 2025
It's cool to see this project evolving into a solid open-source library
The new viz feature shows how the abliteration process gradually groups the residual vectors into two nice clusters 👀 pic.twitter.com/PLYmRPuYB7Abliterate LLMs with Heretic 1.1 It's cool to see this project evolving into a solid open-source library The new viz feature shows how the abliteration process gradually groups the residual vectors into two nice clusters
-
Converting Qwen3 to Diffusion LLM: Block Diffusion Method
By
–
Open recipe to turn Qwen3 into a diffusion LLM 👀👀
— Maxime Labonne @ ICLR (@maximelabonne) 8 décembre 2025
> Swap the causal mask for bidirectional attention
> Source model matters a lot for performance
> Block diffusion (BD3LM) >> masked diffusion (MDLM)
> Light SFT with masking
Great work from @asapzzhou with his dLLM library! pic.twitter.com/ec2tSXAUA1Open recipe to turn Qwen3 into a diffusion LLM > Swap the causal mask for bidirectional attention
> Source model matters a lot for performance
> Block diffusion (BD3LM) >> masked diffusion (MDLM)
> Light SFT with masking Great work from @asapzzhou with his dLLM library!