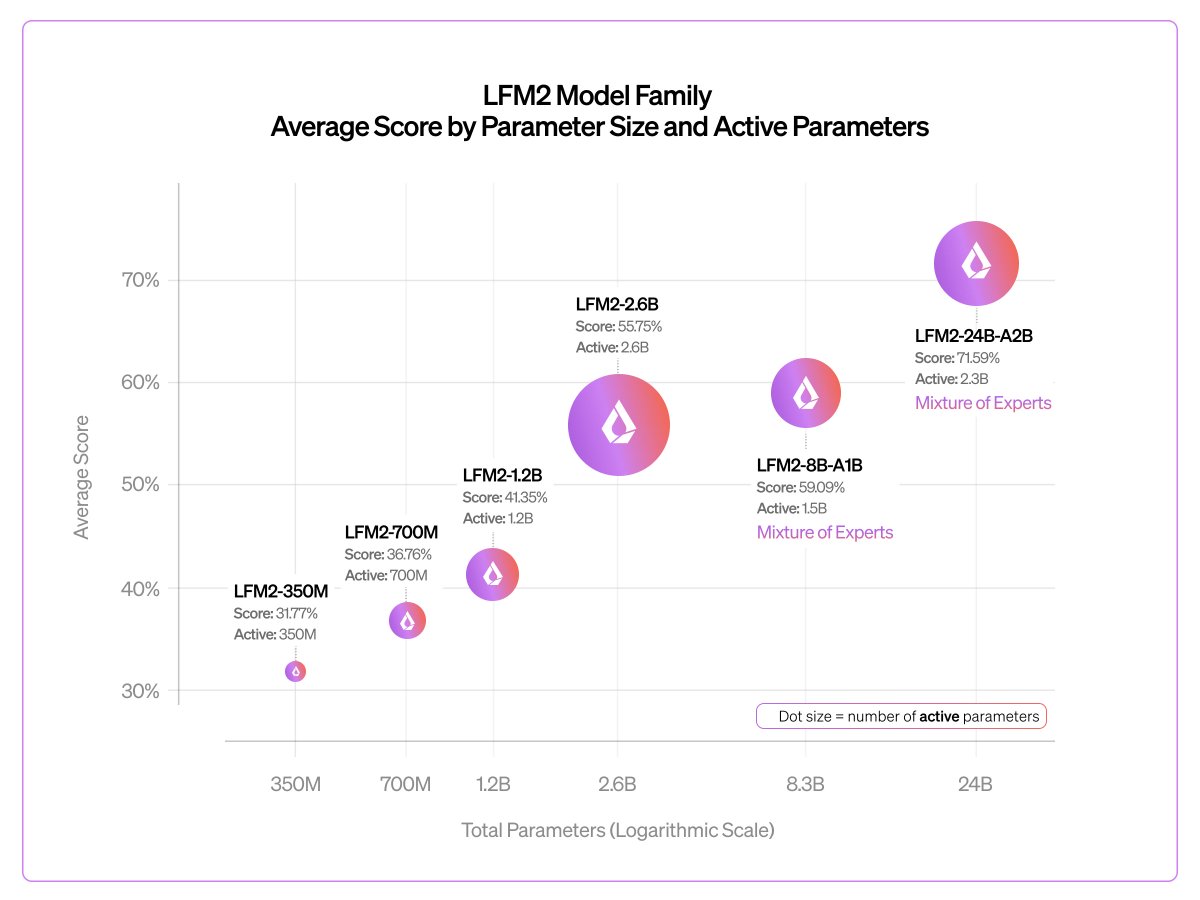
Early checkpoint of our biggest LFM2 model to date 🎉 It shows good scaling and extremely fast inference vs. gpt-oss-20b and Qwen3-30B-A3B We'll release an LFM2.5 version with more pre-training and RL in a few months Liquid AI (@liquidai) Today, we release our largest LFM2 model: LFM2-24B-A2B 🐘 > 24B total parameters > 2.3B active per token > Built on our hybrid, hardware-aware LFM2 architecture It combines LFM2’s fast, memory-efficient design with a Mixture of Experts setup, so only 2.3B parameters activate each run. The result: best-in-class efficiency, fast edge inference, and predictable log-linear scaling all in a 32GB, 2B-active MoE footprint. 🧵 — https://nitter.net/liquidai/status/2026301771539202269#m
→ View original post on X — @maximelabonne, 2026-02-24 14:31 UTC