The team acknowledges that some agents are still very limited each in their own way:
– Deep research cannot interact with webpages (no Textbrowser can)
– Operator has trouble reading through long pages personal take: Operator should theoretically be able to also do deep research
@aymericroucher
-
Deep research and Operator limitations; Operator could do deep research
By
–
-
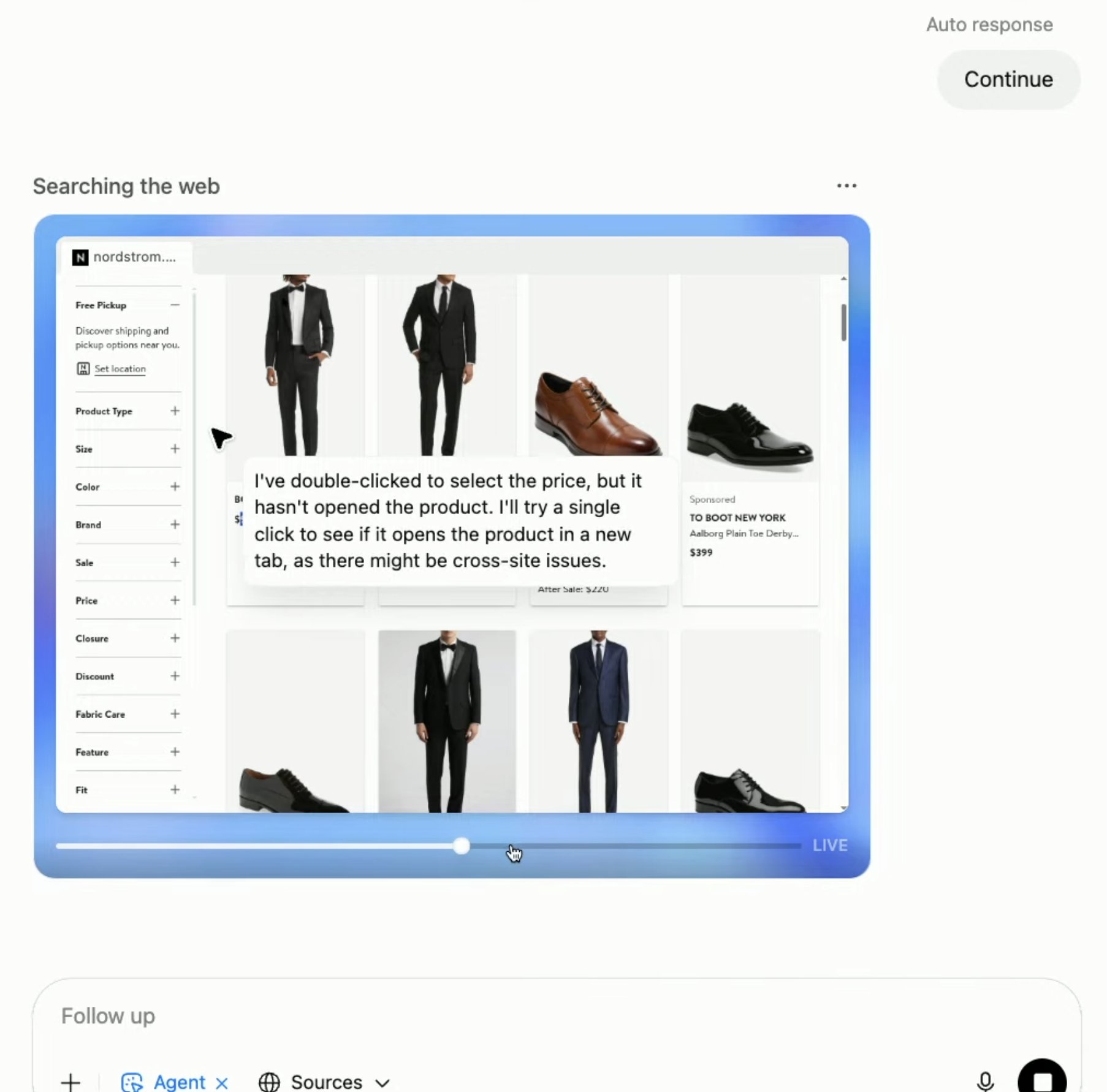
ChatGPT agent live announcement combining Deep Research, Operator, Terminal code editing
By
–
ChatGPT agent live announcement underway, with @sama onboard!
This Agent patches together
– Deep Research (TextBrowser )
– Operator (GUI Agent) – Terminal code editing
to unlock all these capacities together in an agent. -

WebSailor paper uses agentic RL post-training to boost Deep Research scores
By
–
Recent WebSailor paper by Alibaba-NLP, shows how to post-train models for Deep Research – good insights in there, about creating a dataset then training recipe. I particularly like how the agentic RL at the end of post-training improves scores by ~4 p.p. across the board: RL +
-
Muon(Clip) vs AdamW comparison request
By
–
@eliebakouch could you do a comparison of Muon(Clip) vs AdamW to explain the differences?
-
Huggingface explains stateless direct response MCP server choice
By
–
If you're developing MCP servers, you should give a read to how the @huggingface team built the Hub MCP, they explain why they chose a Stateless + Direct Response server over other options!
-
SmolLM3: Powerful built-in tool-calling capabilities
By
–
Reminder: SmolLM3 comes with built-in tool-calling, and it works really well! pic.twitter.com/uba78UfPtg
— m_ric (@AymericRoucher) 9 juillet 2025Reminder: SmolLM3 comes with built-in tool-calling, and it works really well!
-
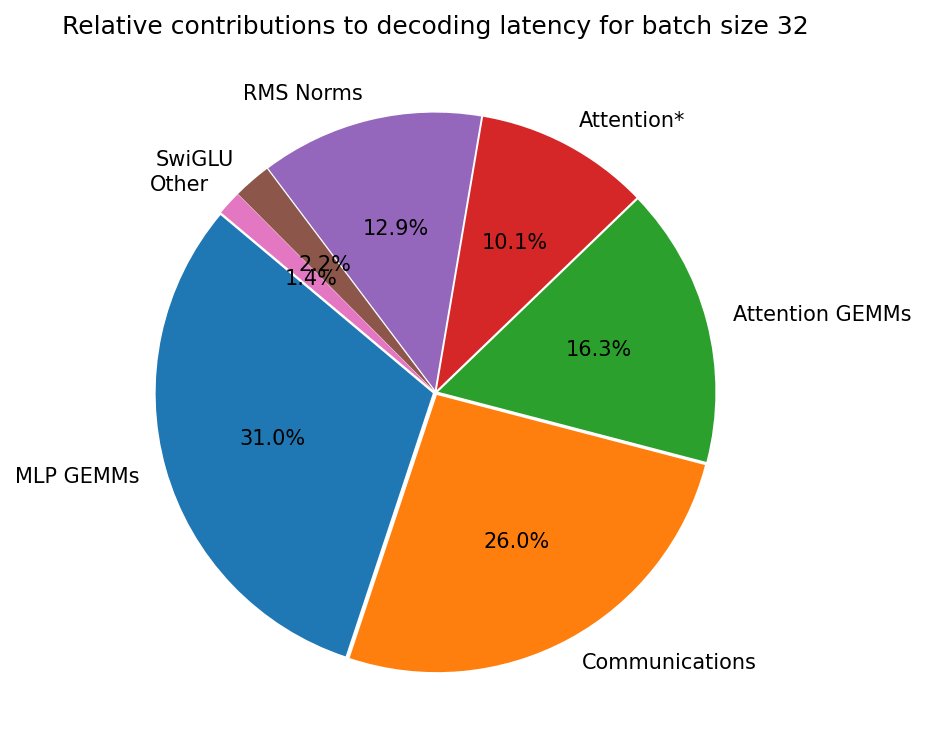
FlashAttention less useful with MLP GEMM latency dominance
By
–
Maybe FlashAttention is not that useful when you have MLP GEMMs that eat so much latency? Interesting graph in the latest blog post from @gpus_go_brrr!
-
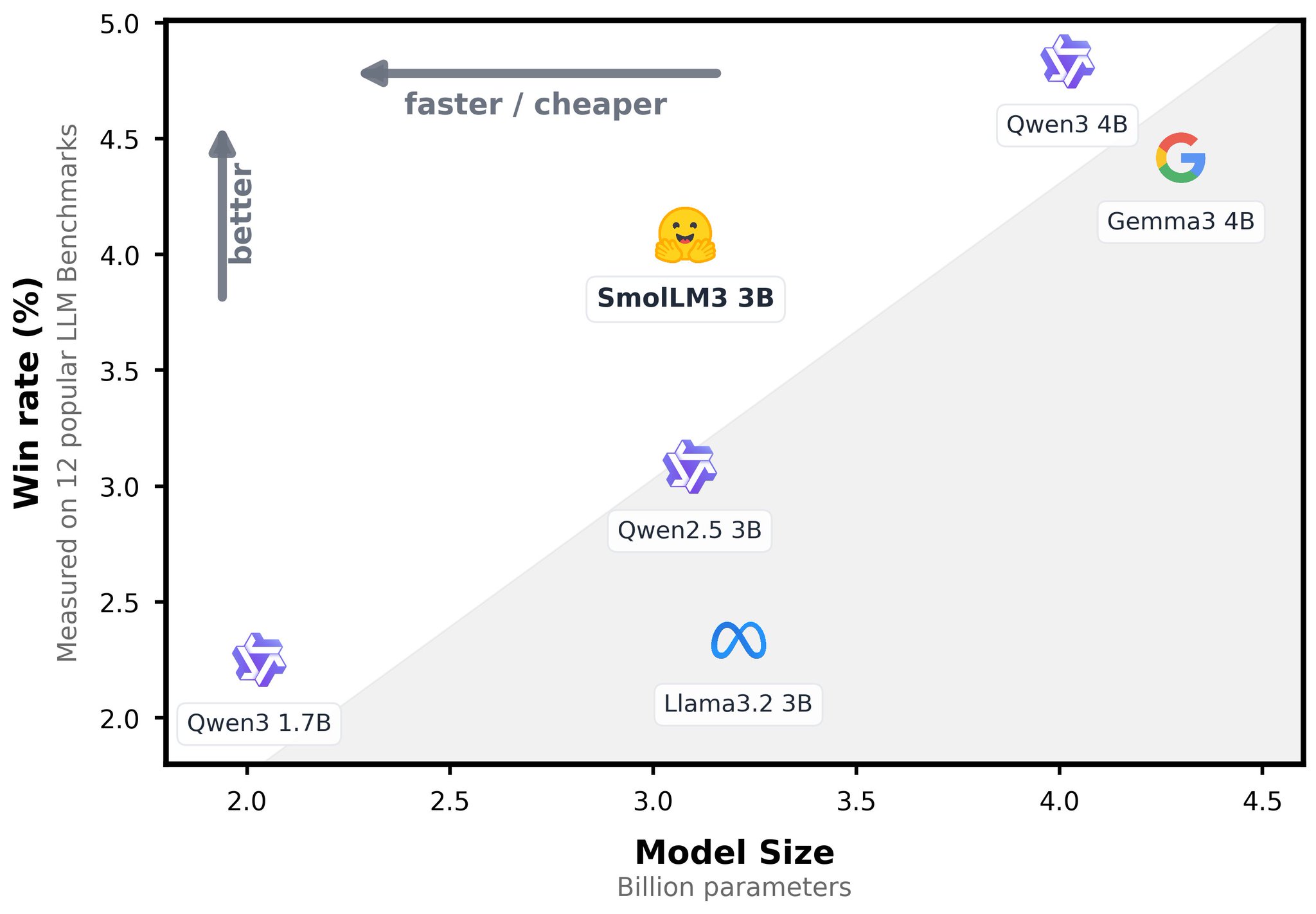
SmolLM3-3B fills Qwen’s Pareto gap via agentic post-training
By
–
Qwen left a hole in the Pareto frontier of optimal performance for a given size… So we just filled it: introducing SmolLM3-3B I helped the SmolLM team on the "make it agentic" part, by post-training the model on agent traces with @akseljoonas
: the model is now also on -
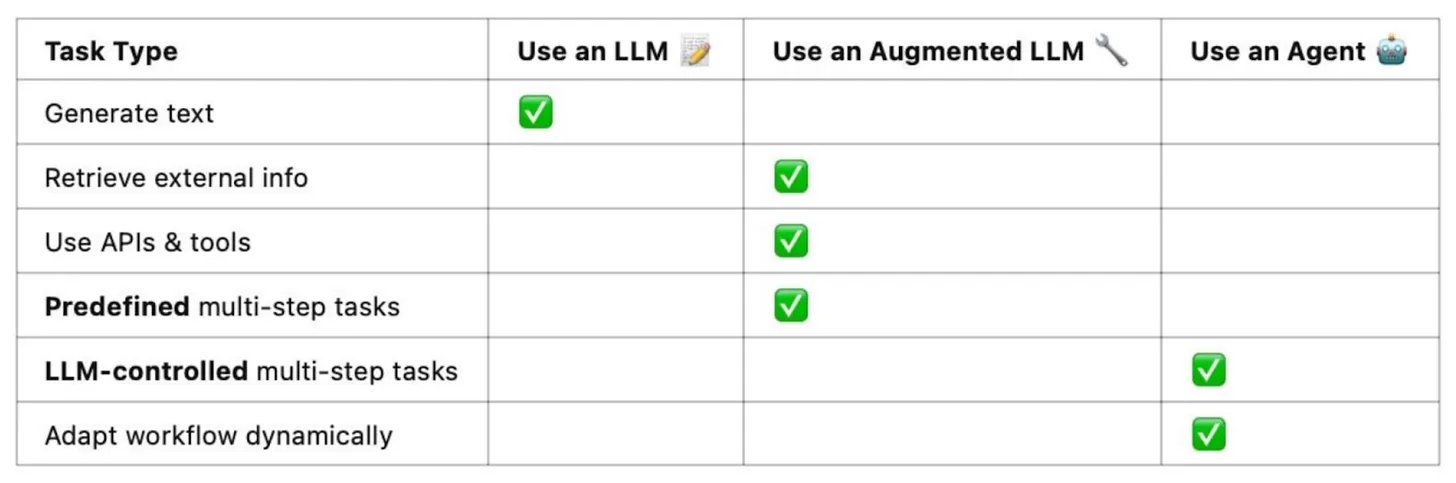
Agents too unreliable, use only when no other choice
By
–
Agents are too unreliable => Use them only when you have no choice! > Don't get me wrong, agentic apps are powerful and unlocks vast fields of previously impossible use cases, but indeed people often try to use thel in uses cases where they don't belong. @hugobowne just
-
Stop Building AI Agents article by Hugo
By
–
Hugo's article: https://
decodingml.substack.com/p/stop-buildin
g-ai-agents
…