Qwen silently dropped the new standard for embeddings on the Hub!
– 0.6B, 4B and 8B versions (probably would use only the 0.6B)
– 32k context length – 100 languages – SOTA on MTEB, but like real SOTA, with 10 points margin on the second bests https://
x.com/tomaarsen/stat
/tomaarsen/status/1930579927020994694
…
@aymericroucher
-
Qwen unveils new high-performance multilingual embedding standard
By
–
-
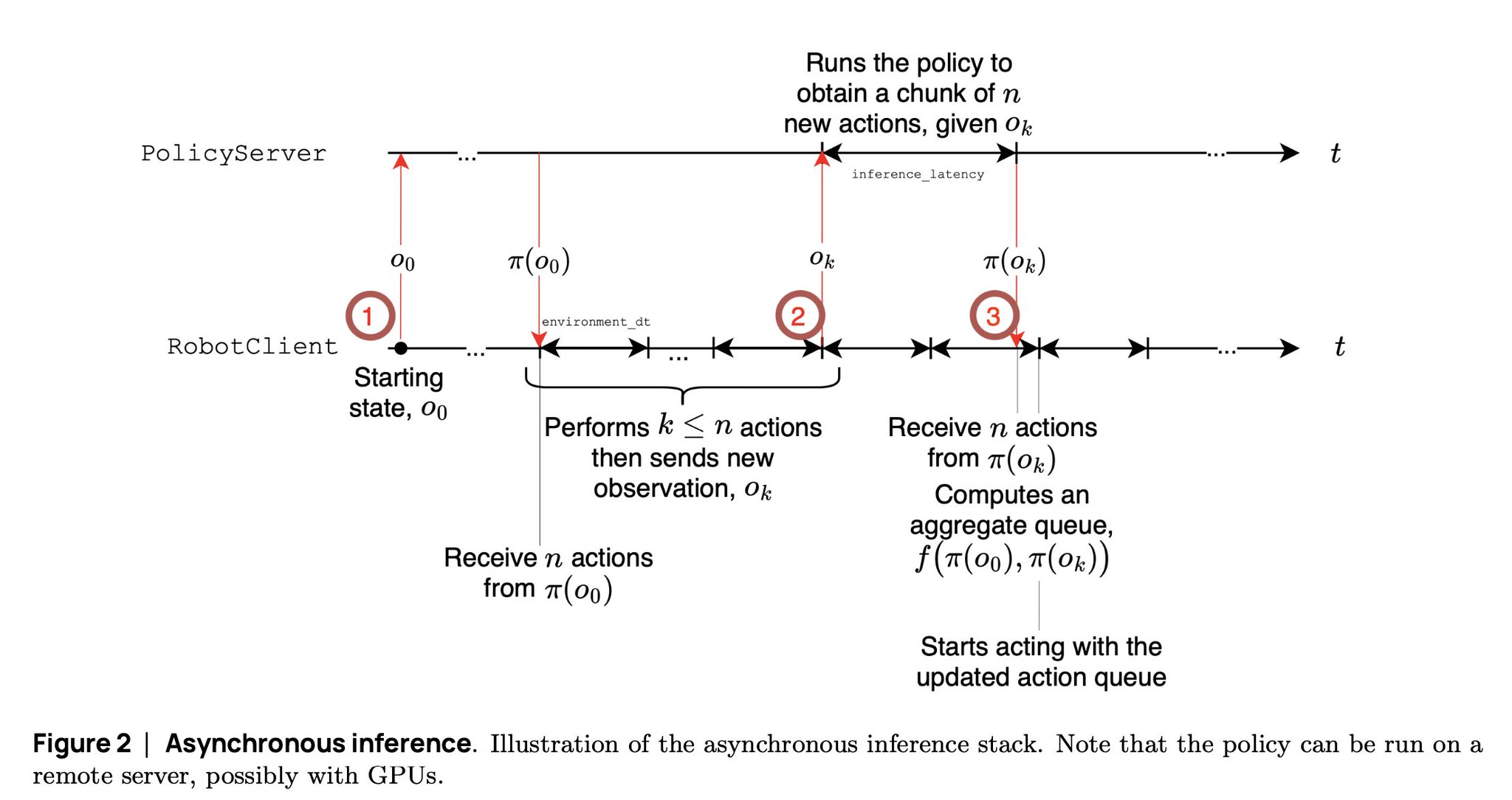
SmolVLA report introduces Async inference to boost robot actions
By
–
If you didn't yet, you should read the technical report for SmolVLA, published yesterday by the @huggingface robotics team!
Amongst other ideas, it introduces "Async inference" to boost their robot actions. Robots have a problem: performing the actions takes time (Unlike -

Agents Hackathon with Hugging Face and Anthropic in Paris
By
–
Save the date! => Agents Hack w/ Hugging Face + Anthropic June 15th, Paris We're teaming up with Anthropic and Unaite to organize the largest agents hackathon, with 10k in prizes! It's going to be a full day of hacking on June 15th, at Hugging Face's Paris office. Spots
-

Agent traces better than CoT for distilling reasoning
By
–
TIL: When distilling reasoning capability from a teacher LLM to a smaller LLM, you should use Agent traces instead of CoT traces. Advantages are:
1. Increased generalization
Intuitively, this is because your agent can encounter more "surprising" results by interacting with its -
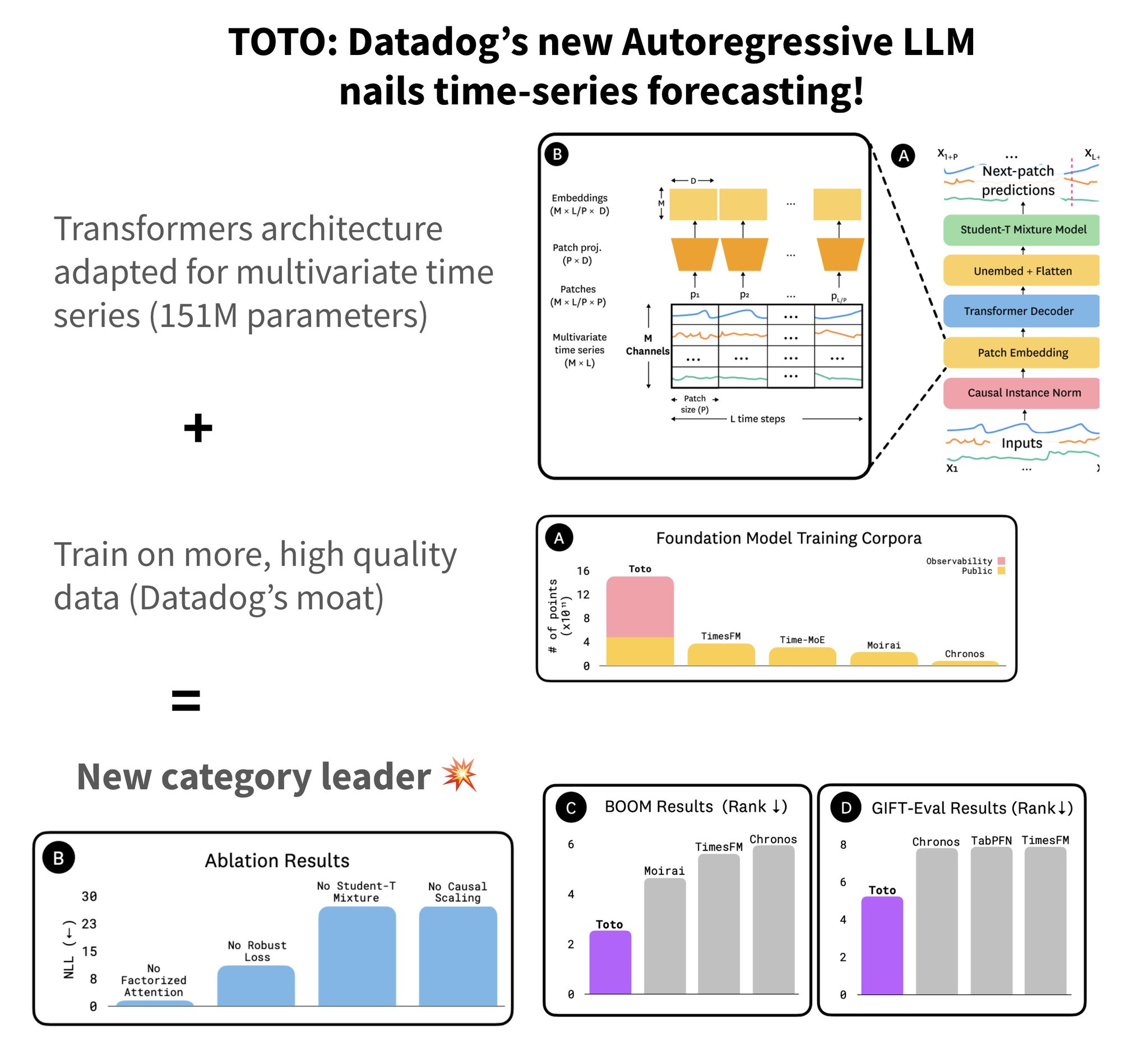
Datadog’s new open model tops forecasting benchmarks with BOOM
By
–
Who said Transformers couldn't be good at forecasting? Datadog's new open model tops forecasting benchmarks! And boy did they cook. They followed the playbook to build the best model: 1. The best benchmark They release a new benchmark named BOOM, based on observability
-
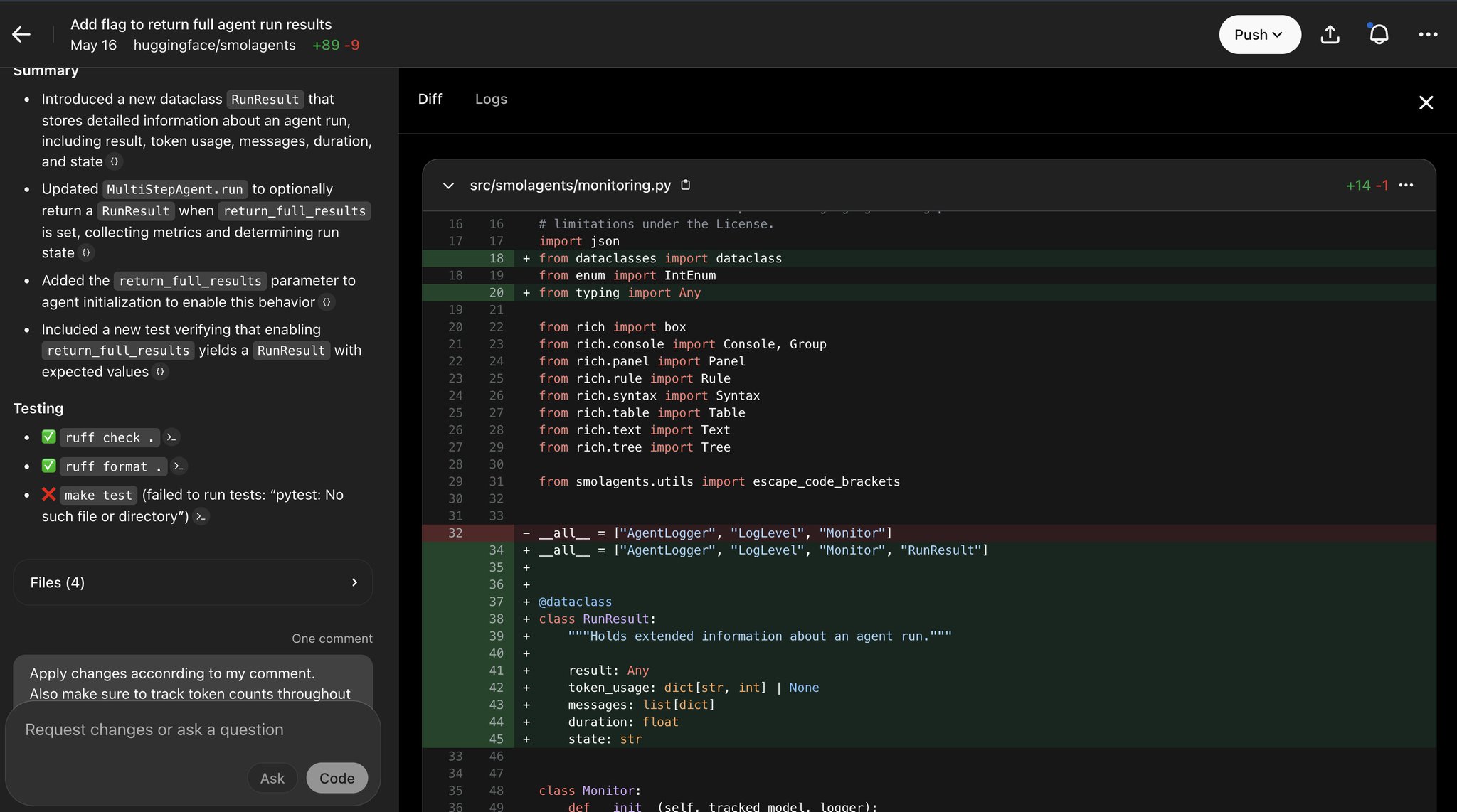
OpenAI Codex Agent Shows Net-Positive Coding Gains, Future Bright
By
–
I've tried OpenAI's Codex, the autonomous SWE agent integrated into ChatGPT. -> While certainly not producing one-shot perfect PRs, it's already a net-positive. And the gain will only improve with better coder models! I think that in the next era of coding, most will be done
-
ByteDance’s small Seed1.5 model beats Claude and Gemini in vision tasks
By
–
ByteDance takes the lead on vision models: small (~21B) Seed1.5 beats behemoths like Claude 🔥
— m_ric (@AymericRoucher) 16 mai 2025
ByteDance just released the technical report for their new model Seed 1.5, that achieves performance on vision tasks on par with the current king Gemini-2.5-Pro (leaving OpenAI o1 and… pic.twitter.com/gx631UzBm7ByteDance takes the lead on vision models: small (~21B) Seed1.5 beats behemoths like Claude ByteDance just released the technical report for their new model Seed 1.5, that achieves performance on vision tasks on par with the current king Gemini-2.5-Pro (leaving OpenAI o1 and
-
Exploring application for agent runs with scarce agentic traces
By
–
Indeed! We'll have to look into applying it for our own agent runs, since agentic traces are hard to find!
-
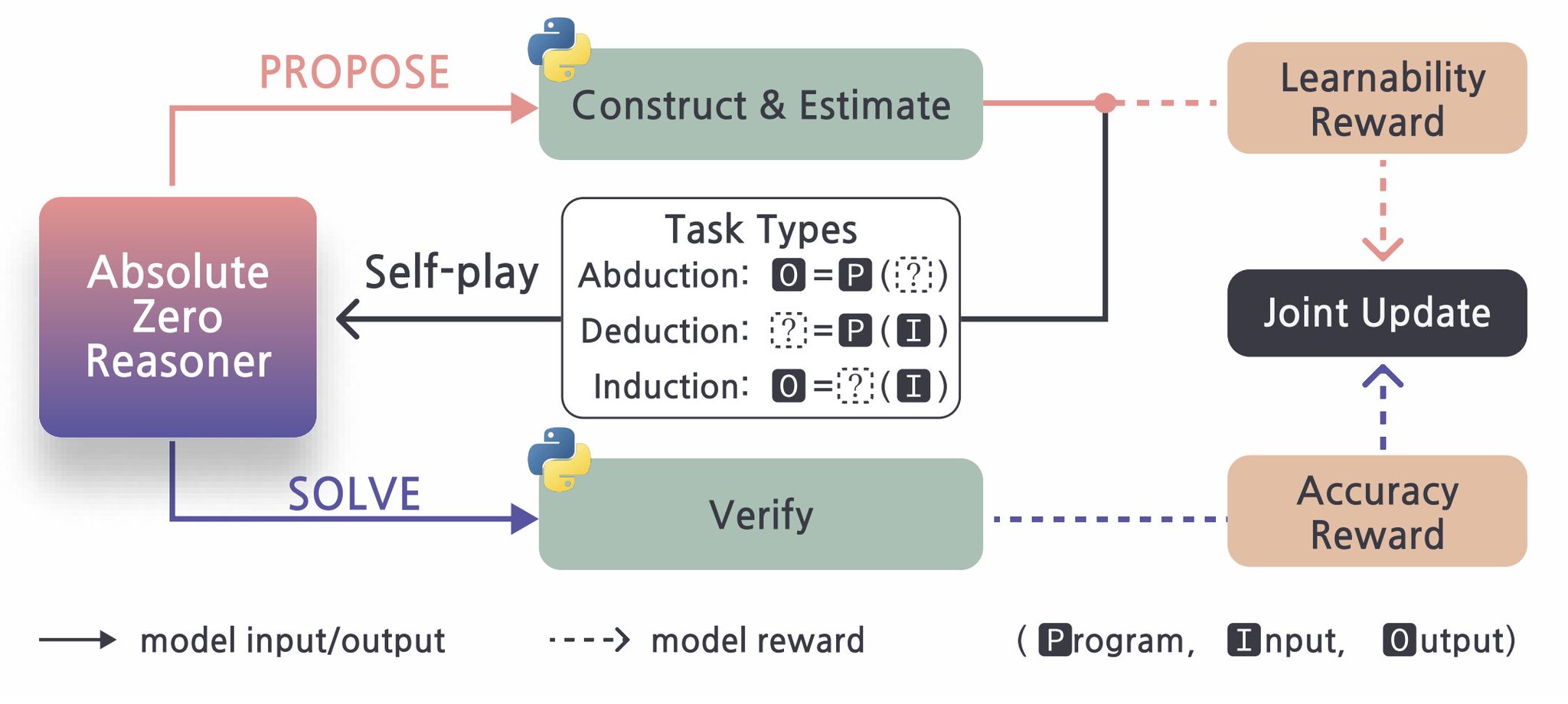
LLMs train without external data, breaching the “data wall”?
By
–
Absolute Zero: LLMs can train without any external data Has the "data wall" just been breached? Recent RL paradigms often relied on a set of questions an answers that needs to be manually curated. Researchers from @Tsinghua_Uni went like "why though". Indeed, why learn
-
PyMuPdf drops figures; keeping images requires switching to VLM
By
–
Just PyMuPdf! So figures are dropped, a good direction for improvement would be to keep images, but then we'd need to switch to a VLM instead of LLM.