𝙉𝙚𝙬 𝙎𝙩𝙚𝙥-𝙗𝙮-𝙨𝙩𝙚𝙥 𝙂𝙪𝙞𝙙𝙚: 𝙎𝙥𝙞𝙣𝙣𝙞𝙣𝙜 𝙐𝙥 𝙞𝙣 𝙇𝙇𝙈𝙨! I've made a step-by-step intro to LLMs. I've explained a lot in detail, and added plentiful resources to go further: tutorials, papers, blog posts… Dive in! https://
shorturl.at/aHJR3
@aymericroucher
-
New Step-by-Step Guide to Spinning Up in LLMs
By
–
-
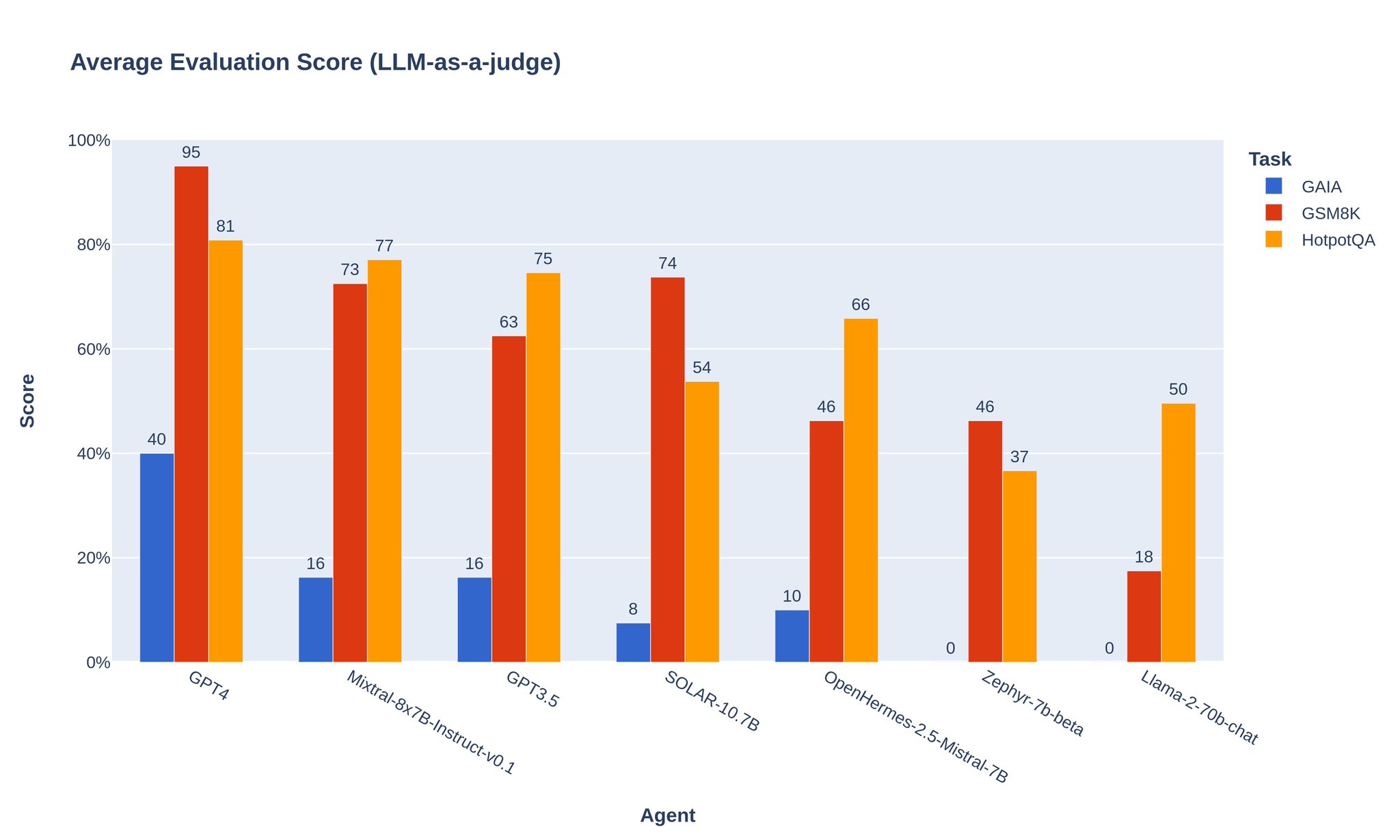
Open-source Mixtral beats GPT3.5 in LangChain agents
By
–
We've worked with @andrewrreed and Joffrey Thomas on making it possible to build LangChain agents powered by open-source models. On our benchmark, Mixtral is the most competitive of all OS models, even surpassing GPT3.5 Read our blog post here: https://
huggingface.co/blog/open-sour
ce-llms-as-agents
… -
Encouraging development of agents with open-source models
By
–


Happy to have helped on this, let's keep developing the usage of agents based on open-source models!
-
RAG relevance for questions using many distant document elements
By
–
RAG can handle all sorts of different questions, it's really appropriate for extracting information from a document. An interesting question is "when the question requires using more many distant elements from doc, is RAG still relevant?"
-
RAG retrieval failures due to random variations, need more tests
By
–
Well spotted!
Both variations (blue and green ) are also due to random variations. For instance the RAG fails to retrieve relevant snippets on 1 single example. The tests I ran were not numerous enough yet to smooth these variations out. But maybe I'll run more. -
RAG system reduces token input from 128k to 2k
By
–
Exactly!
To complement on the end: thanks to the RAG system, the model was fed around 2k tokens each time, down from the 128k tokens of the original document. -
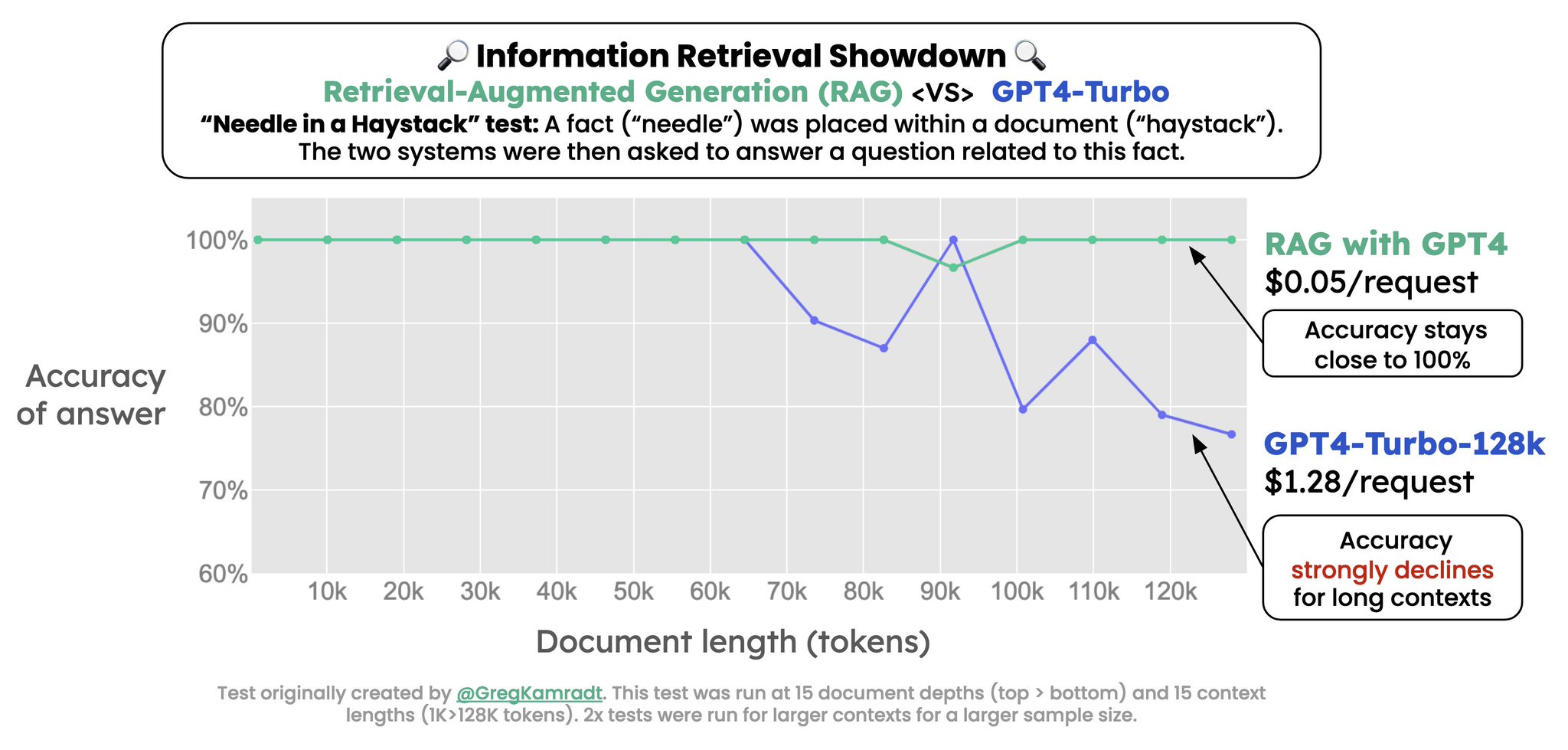
RAG beats GPT-4-Turbo in long document retrieval test
By
–
Information Retrieval: Who wins, GPT-4-Turbo or a RAG based on GPT4? I extended the "Needle in a Haystack" test created by @GregKamradt & the result is clear: 𝗥𝗔𝗚 𝘄𝗶𝗻𝘀 > its edge becomes clear for the longest document sizes. @huggingface Links below