I've made an open and free version of Google's NotebookLM, and it shows how high the open source tech task has risen! The app's workflow is simple. Given a source PDF or URL, it extracts the content from it, then tasks @AIatMeta
's Llama 3.3-70B, with writing the podcast
@aymericroucher
-
Open source NotebookLM alternative uses Llama 3.3-70B for podcasts
By
–
-
Smolagents 1.15 release adds streaming outputs
By
–
¡Releasing smolagents 1.15, with streaming outputs! ⏩
— m_ric (@AymericRoucher) 8 mai 2025
✨ We've just added streaming outputs in smolagents, meaning that all interactions can feel much smoother.
Just pass stream_outputs=True to your CodeAgent upon initialization to try it out!
[Insert feels Good man meme] pic.twitter.com/EB05A19bgj¡Releasing smolagents 1.15, with streaming outputs! We've just added streaming outputs in smolagents, meaning that all interactions can feel much smoother. Just pass stream_outputs=True to your CodeAgent upon initialization to try it out!
[Insert feels Good man meme] -
Struggling to find a short package name due to abandoned projects
By
–
I've had the issue when trying to launch smolagents: I wanted a short, impactful name, and many names in something*agent*something were already taken. Mot of these packages had had 1 initial release, then went unmaintained for 10 years. But they still kept the name, because
-
Launch of Computer Use in smolagents with Qwen-VL grounding
By
–
We're launching Computer Use in smolagents! 🥳
— m_ric (@AymericRoucher) 6 mai 2025
-> As vision models become more capable, they become able to power complex agentic workflows. Especially Qwen-VL models, that support built-in grounding, i.e. ability to locate any element in an image by its coordinates, thus to… pic.twitter.com/mI8MuWZkISWe're launching Computer Use in smolagents! -> As vision models become more capable, they become able to power complex agentic workflows. Especially Qwen-VL models, that support built-in grounding, i.e. ability to locate any element in an image by its coordinates, thus to
-

Hugging Face’s smolagents: Tiny, focused agentic framework tackles complexity.
By
–
The agentic framework of @huggingface
, smolagents, is the tinyest ever. It has fewer features than other frameworks -> that's exactly its goal. The main issue among agentic frameworks is complexity : they tend to pile up abstractions, trying to solve everything rather than being -
Call to open-source Grok 2 on a perfect occasion
By
–
Awesome news! Wouldn't that be a perfect occasion to open-source Grok 2!
-
Meeting Andrew Ng, excited about new smolagents course
By
–
And that's when I met the one and only @AndrewYNg, whose melodious voice first introduced me to the green pastures of machine learning, as I began my journey 5 years back: it means a lot! ✨
— m_ric (@AymericRoucher) 23 avril 2025
I'm thrilled about this new course! You'll learn to use smolagents and build agents that… https://t.co/R8C2I8LsBAAnd that's when I met the one and only @AndrewYNg
, whose melodious voice first introduced me to the green pastures of machine learning, as I began my journey 5 years back: it means a lot! I'm thrilled about this new course! You'll learn to use smolagents and build agents that -

Text embeddings rediscover BM25 core principles during training
By
–
-> Researchers show that text embeddings methods re-discover BM25 from scratch during training! Far from abandoning standard search techniques like BM25, it appears that neural search methods naturally re-implement their core principles. Let's you have a search query like
-
Clarifying smolagents name and multi-agent orchestration
By
–
It seems smolagents was a bit under-researched. First of all it's "smolagents", without a space in the middle. We do have multi-agents (not with a dedicated abstraction, we managed to handle the orchestration under the base agent class): https://
huggingface.co/docs/smolagent
s/examples/multiagents
… We do have -
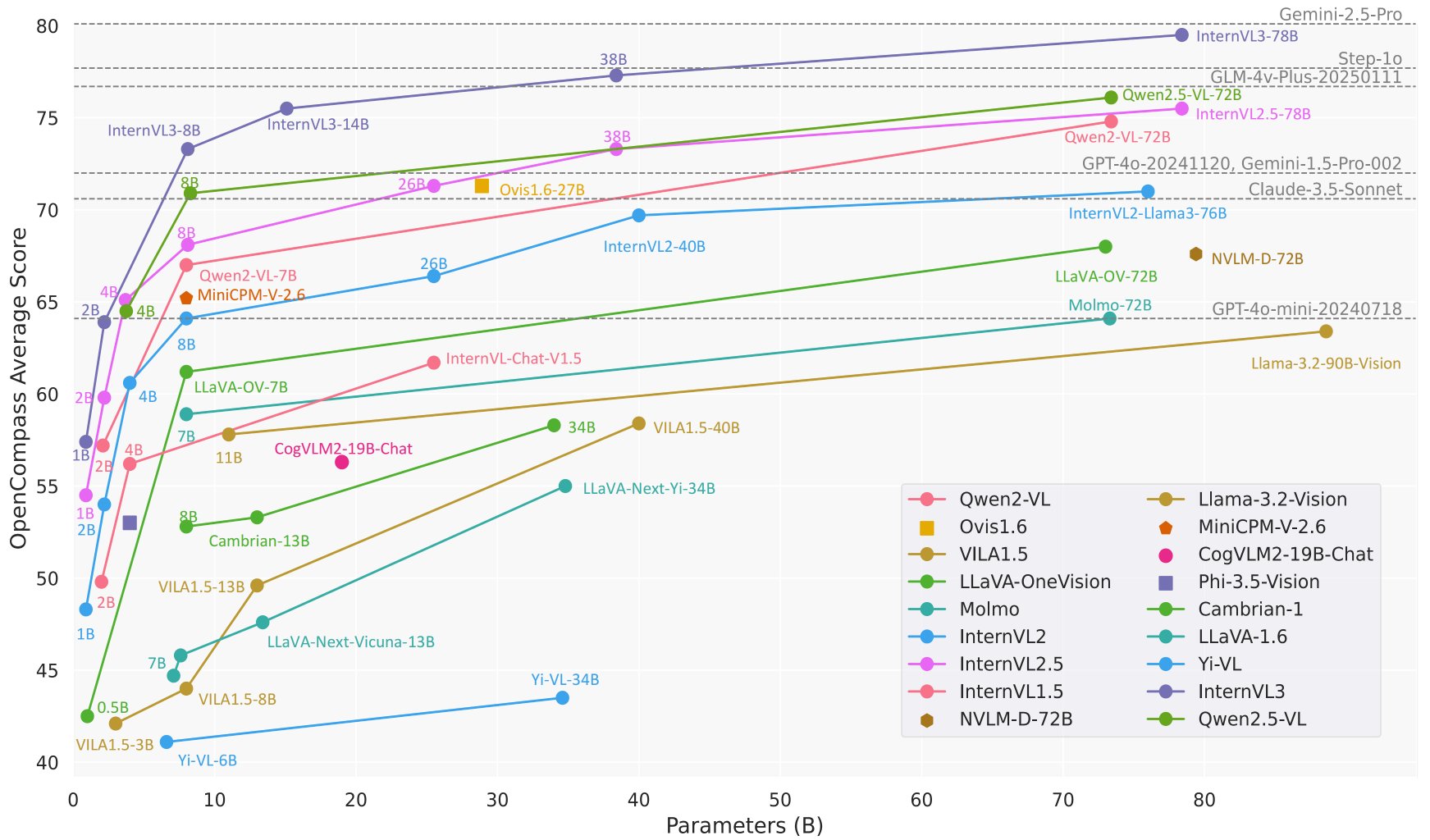
InternVL3 dethrones Qwen 2.5 as new king of open VLMs
By
–
New king of open VLMs: InternVL3 takes Qwen 2.5's crown! -> InternVL have been a wildly successful series of model : and the latest iteration has just taken back their crown thanks to their superior, natively multimodal vision training pipeline. Most of the vision language