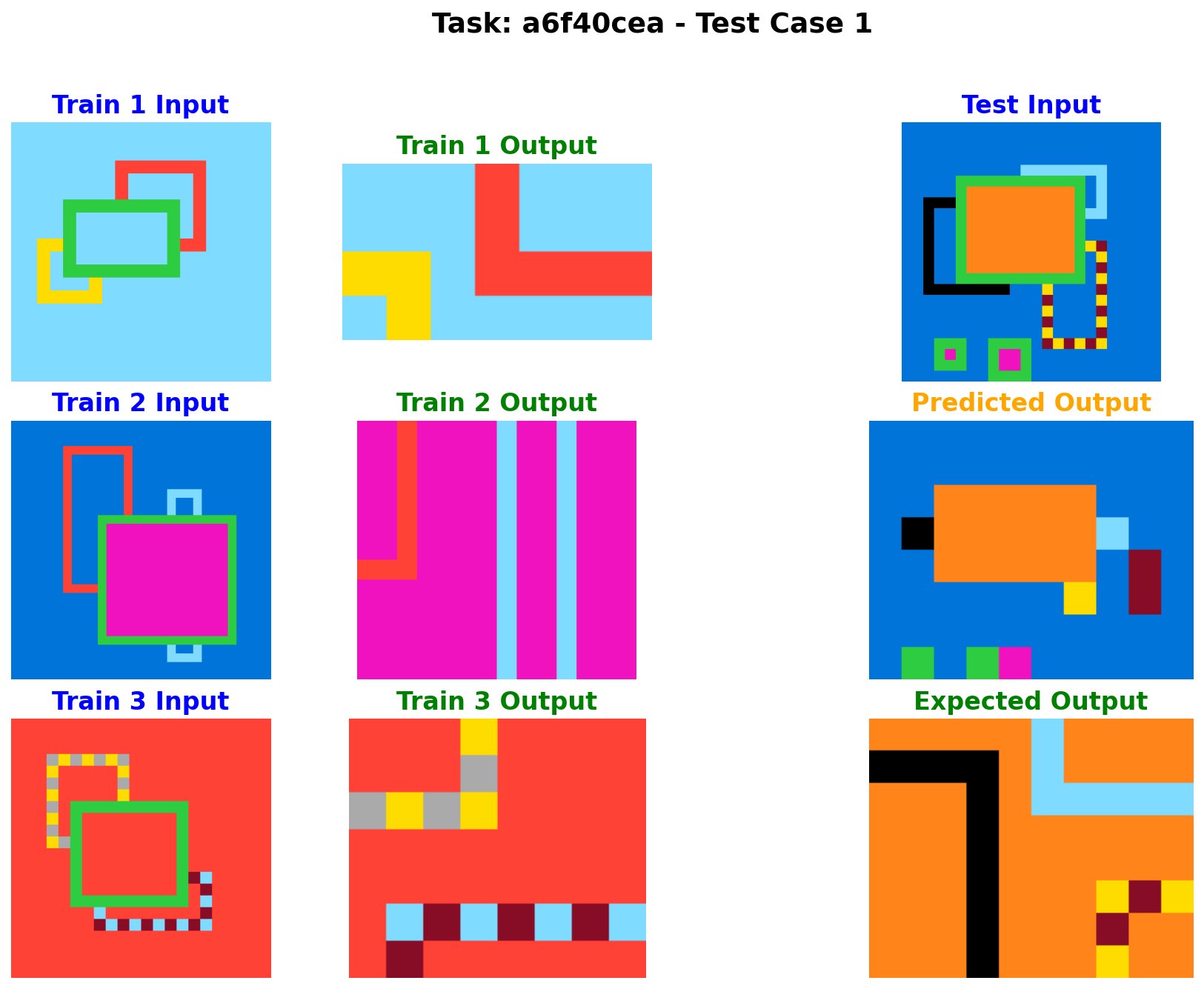
I've tested if nano-banana / Gemini-2.5-flash-image beat ARC-AGI – it's quite far. Btw bravo to the ARC_AGI team, the delta between easiness of problems for humans vs difficulty for LLMs is just
@aymericroucher
-
Claude Code’s unique prompt handling feature explained
By
–
One cool thing that Claude Code has is the ability to type guidance as the model goes, and when you hit enter it's put in a wait stage and submitted to the prompt after the next tool call.
I didn't see this in Codex. -

GPT-5 Achieves New Benchmark on Training Info Efficiency
By
–
GPT-5 just beat a new benchmark: the "model training info / total system card length" is now approaching 0 !
-
Claude Code Front-End Usage and Comparison for Homepage Creation
By
–
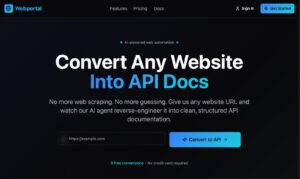
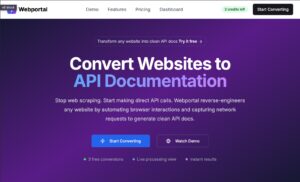
Claude Code for front-end is heavily underrated. Below are 3 attempts to make a homepage for an ongoing project:
Claude Code – Lovable – V0
In my opinion, Claude Code did best! Plus you have all files locally so you can start editing right away
And you have full control over -
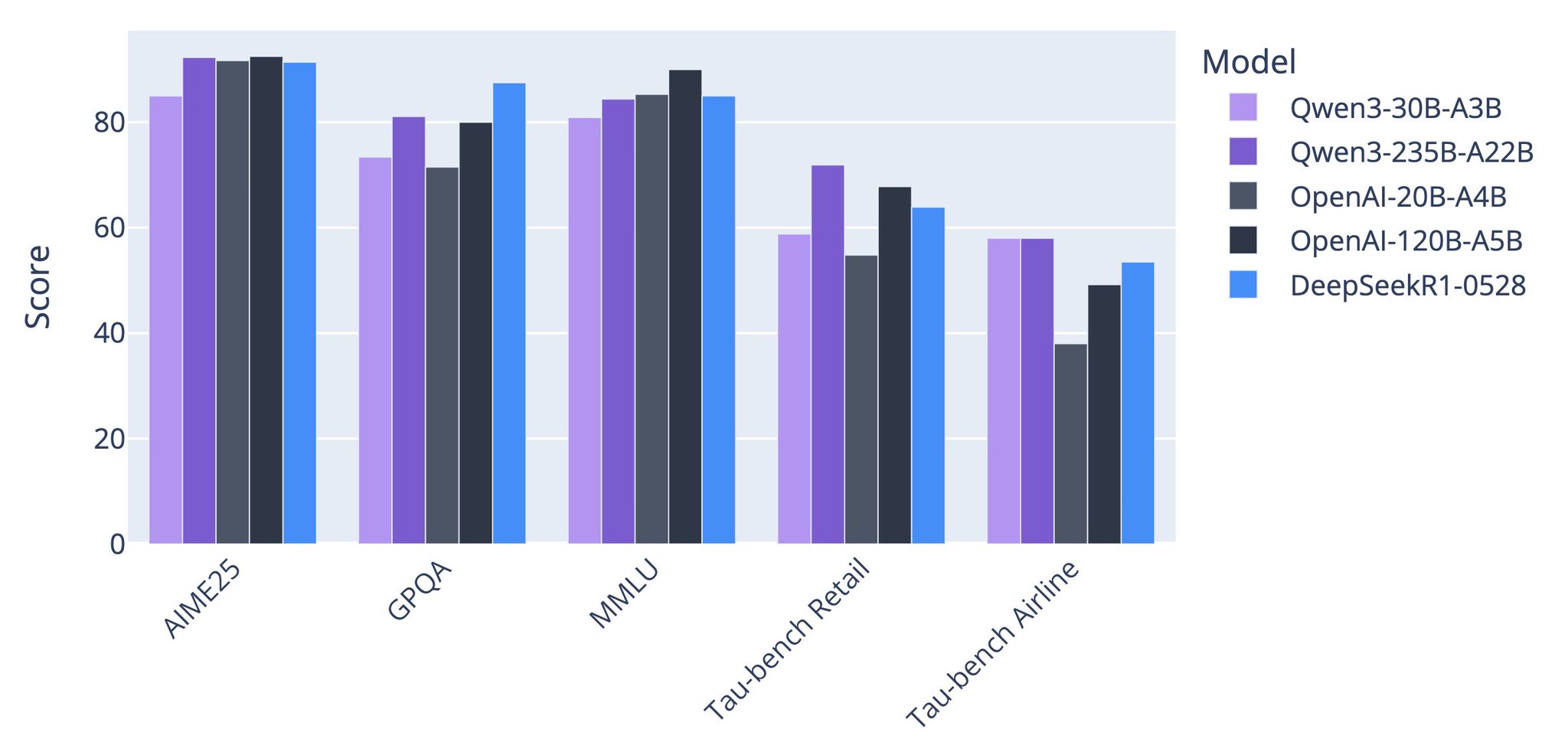
OpenAI’s new open models outperform previous SOTA Qwen
By
–
OpenAI's new open models are the new reference! Fewer parameters (both total and activated), yet much better performance than previous SOTA by Qwen EDIT: put the thinking scores for Qwen3, to be more fair!
-
Comparison of Qwen and OpenAI Model Performance on GPQA Benchmarks
By
–
I used GPQA for Qwen, not sure if it's the standard or the diamond set.
If Qwen uses the standard and not diamond, it's even more impressive to know that OpenAI models on the hardest set beat Qwen on the standard! -
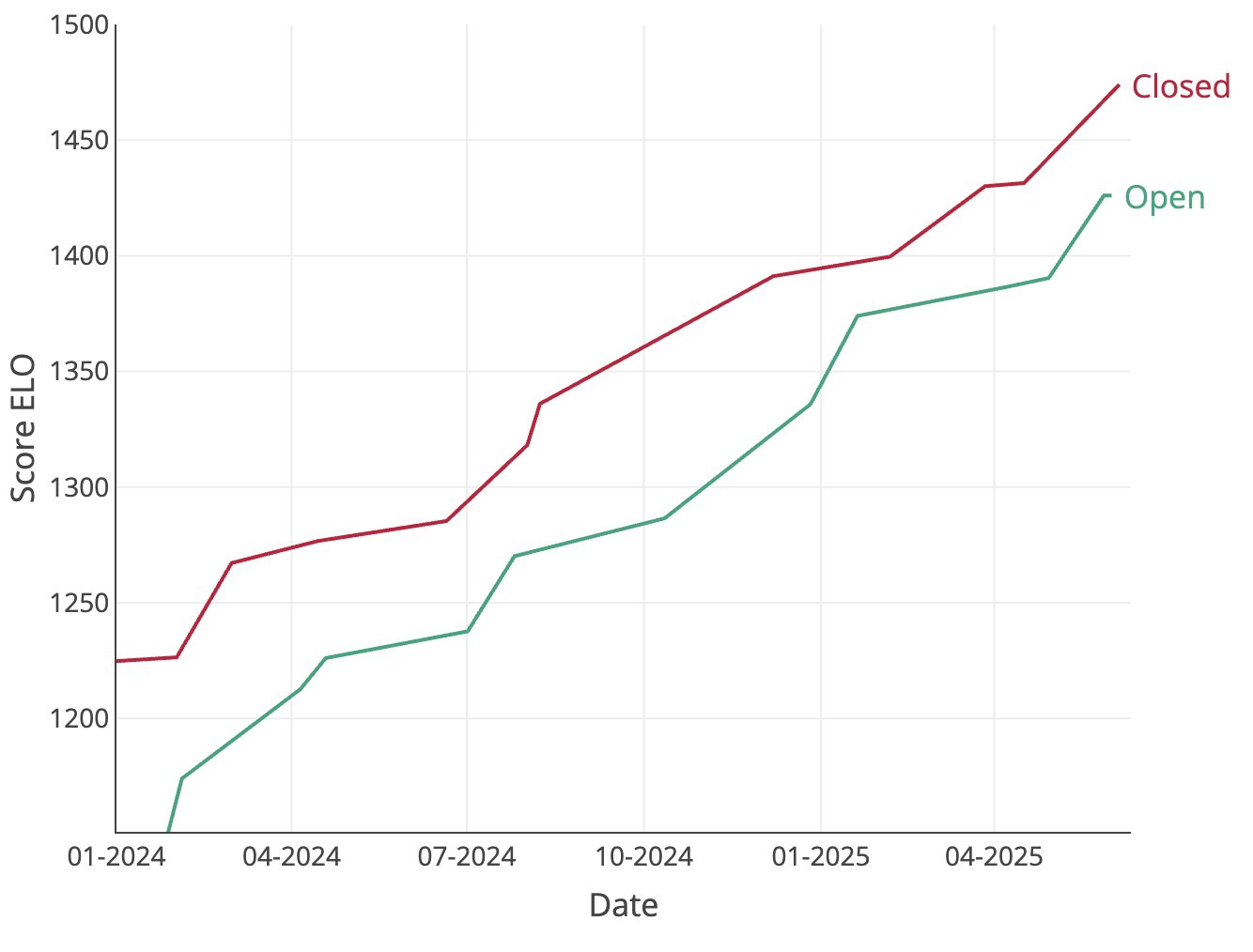
Open Source Chatbots Narrow Gap with Closed-Source on ELO Ratings
By
–
Slowly but steadily, open source is catching up! Here's the best Chatbot Arena ELO from Open vs Closed-weights models through time – even though Chatbot arena advantage the big closed-source labs that can train on the collected datapoints.
-
Insights on Engineering State-of-the-Art AI Agents
By
–
Great insights by Manus team on engineering SOTA agents:
– KV cache is king in agents – filesystem is a great mechanism for memory
– keep errors in the trace
– and more
Read this ! -
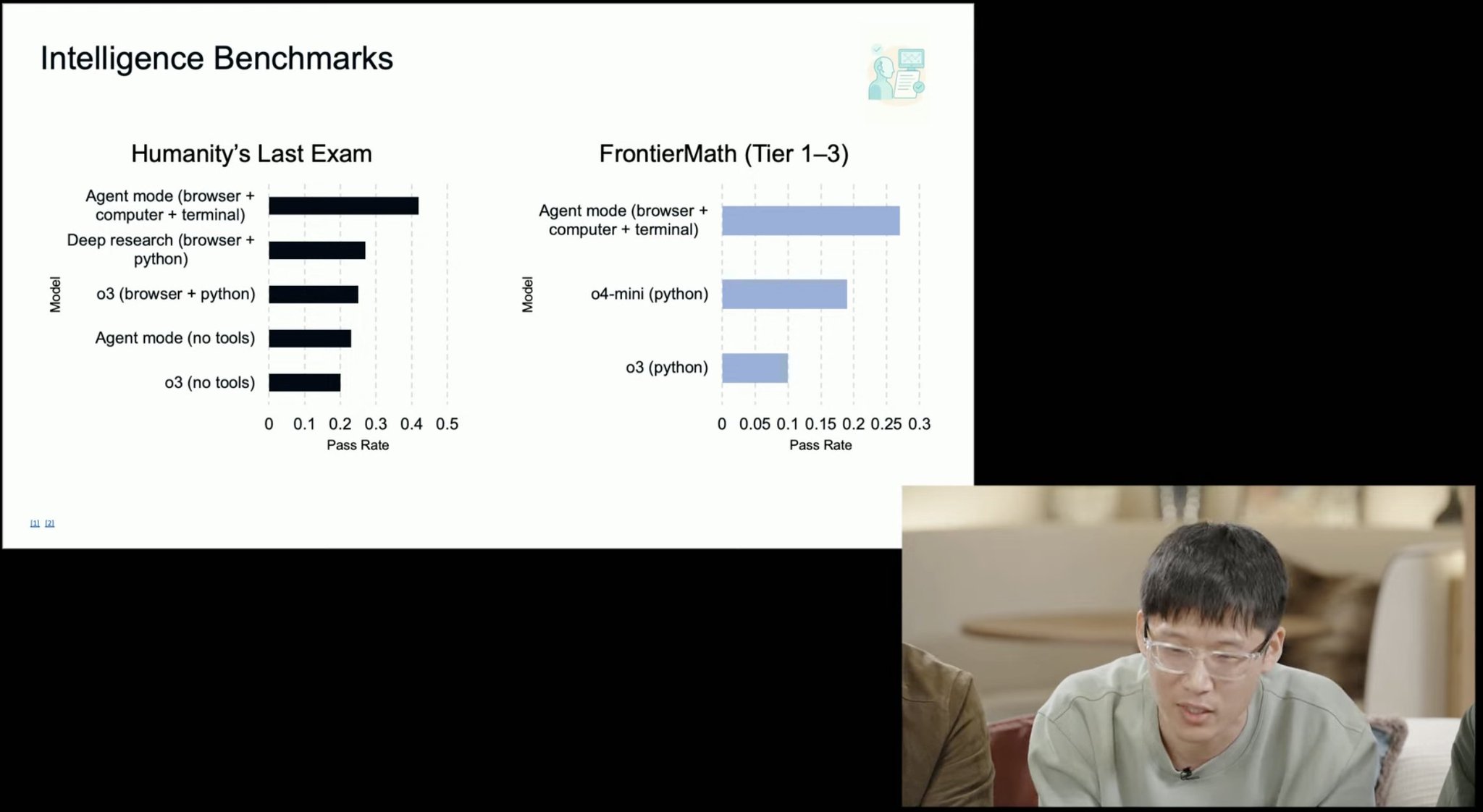
Agent patching improves performance on multiple benchmarks
By
–
Impressive benchmarks!: patching together agents really improves perf on many benchmarks, à la Manus or OpenHands-Versa
-
Example of web research, Drive, Terminal slides, and Operator validation
By
–
Example of cool capabilities unlocked by this : do research on the web and connect to Drive via Text browser, then create slides via Terminal, then view them through Operator to validate slides or go back to the drawing board.