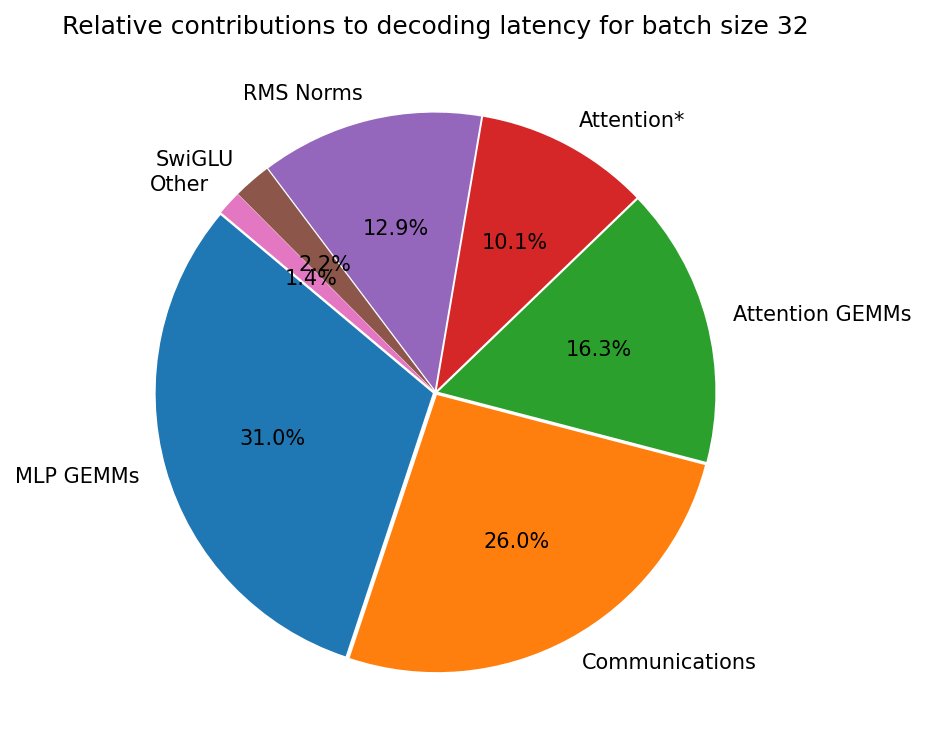
Maybe FlashAttention is not that useful when you have MLP GEMMs that eat so much latency? Interesting graph in the latest blog post from @gpus_go_brrr!
FlashAttention less useful with MLP GEMM latency dominance
By
–
By
–
Maybe FlashAttention is not that useful when you have MLP GEMMs that eat so much latency? Interesting graph in the latest blog post from @gpus_go_brrr!