Fair point on the Semantic Web angle. The loose coupling idea is solid. The practical challenge is that most teams building agents today aren't working in that paradigm yet, so tools like Cognee bridge the gap with familiar abstractions until the infrastructure catches up.
@akshay_pachaar
-
Graph Search vs Vector Search: Beyond Similarity in AI
By
–
Exactly. Vector search answers "what's similar" but not "how are these connected." The Alice-project-outage example in the post explains this. Most real questions need at least two hops, and that's where graphs become essential, not optional.
-
Session Management Performance Optimization in AI Chat Systems
By
–
Solid point! That's a real thing people will hit when using Cognee in a live chat. Using session_id to defer the heavy graph updates to the background keeps responses fast while memory stays in sync behind the scenes.
-
Link to article on X platform
By
–
x.com/i/article/204355769484…
→ View original post on X — @akshay_pachaar, 2026-04-13 17:36 UTC
-

CLAUDE.md: 15K Stars for AI Coding Guidelines
By
–
If you found it insightful, reshare with your network. Find me → @akshay_pachaar ✔️ For more insights and tutorials on LLMs, AI Agents, and Machine Learning! nitter.net/akshay_pachaar/status/… Akshay 🚀 (@akshay_pachaar) A single 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 file just hit 15K GitHub stars. (derived from Karpathy's coding rules) Andrej Karpathy observed that LLMs make the same predictable mistakes when writing code: over-engineering, ignoring existing patterns, and adding dependencies you never asked for. If you've used AI coding assistants, you've hit all of these. But here's the thing: If the mistakes are predictable, you can prevent them with the right instructions. That's exactly what this 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 does. You drop one markdown file into your repo, and it gives Claude Code a structured set of behavioral guidelines for your entire project. This is a big deal. – Built entirely around prompt engineering for AI coding assistants – No framework, no complex tooling, just one .md file that shapes behavior Developers are moving past "use AI to write code" and into "engineer the AI's behavior so the code is actually good." The Claude Code ecosystem is growing fast, and the best tools in it aren't always software. Sometimes they're just well-crafted instructions. 100% open-source. I've shared a link to the GitHub repo in the next tweet! — https://nitter.net/akshay_pachaar/status/2043374229199151351#m
→ View original post on X — @akshay_pachaar, 2026-04-13 12:17 UTC
-
GitHub Repository: Andrej Karpathy Skills Learning Resource
By
–
GitHub repo: github.com/forrestchang/andr…
→ View original post on X — @akshay_pachaar, 2026-04-12 17:02 UTC
-

Claude.md File Reaches 15K Stars with AI Coding Guidelines
By
–
A single 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 file just hit 15K GitHub stars. (derived from Karpathy's coding rules) Andrej Karpathy observed that LLMs make the same predictable mistakes when writing code: over-engineering, ignoring existing patterns, and adding dependencies you never asked for. If you've used AI coding assistants, you've hit all of these. But here's the thing: If the mistakes are predictable, you can prevent them with the right instructions. That's exactly what this 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱 does. You drop one markdown file into your repo, and it gives Claude Code a structured set of behavioral guidelines for your entire project. This is a big deal. – Built entirely around prompt engineering for AI coding assistants – No framework, no complex tooling, just one .md file that shapes behavior Developers are moving past "use AI to write code" and into "engineer the AI's behavior so the code is actually good." The Claude Code ecosystem is growing fast, and the best tools in it aren't always software. Sometimes they're just well-crafted instructions. 100% open-source. I've shared a link to the GitHub repo in the next tweet!
→ View original post on X — @akshay_pachaar, 2026-04-12 17:02 UTC
-
OpenClaw-RL Repository and Free AI/ML Engineering PDF Guide
By
–
OpenClaw-RL Repo: github.com/Gen-Verse/OpenCla… If you want to learn AI/ML engineering, I have put together a free PDF (380+ pages) with 150+ core lessons. Download for free: dailydoseofds.github.io/ai-e…
→ View original post on X — @akshay_pachaar, 2026-04-12 13:35 UTC
-
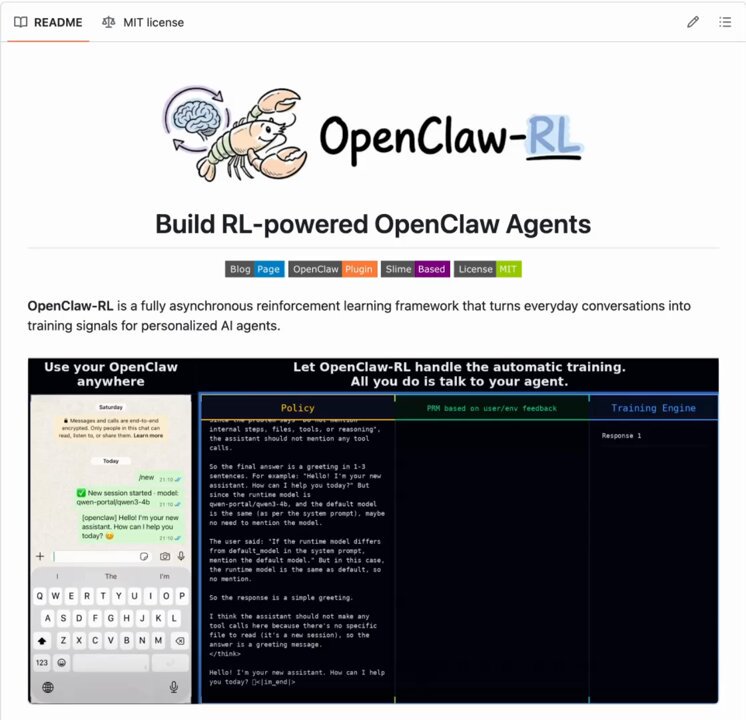
OpenClaw-RL: Reinforcement Learning for Agent Model Weights
By
–
OpenClaw meets RL!
— Akshay 🚀 (@akshay_pachaar) 12 avril 2026
OpenClaw Agents adapt through memory files and skills, but the base model weights never actually change.
OpenClaw-RL solves this!
It wraps a self-hosted model as an OpenAI-compatible API, intercepts live conversations from OpenClaw, and trains the policy in… pic.twitter.com/4kxY1b2wSCOpenClaw meets RL! OpenClaw Agents adapt through memory files and skills, but the base model weights never actually change. OpenClaw-RL solves this! It wraps a self-hosted model as an OpenAI-compatible API, intercepts live conversations from OpenClaw, and trains the policy in the background using RL. The architecture is fully async. This means serving, reward scoring, and training all run in parallel. Once done, weights get hot-swapped after every batch while the agent keeps responding. Currently, it has two training modes: – Binary RL (GRPO): A process reward model scores each turn as good, bad, or neutral. That scalar reward drives policy updates via a PPO-style clipped objective. – On-Policy Distillation: When concrete corrections come in like "you should have checked that file first," it uses that feedback as a richer, directional training signal at the token level. When to use OpenClaw-RL? To be fair, a lot of agent behavior can already be improved through better memory and skill design. OpenClaw's existing skill ecosystem and community-built self-improvement skills handle a wide range of use cases without touching model weights at all. If the agent keeps forgetting preferences, that's a memory problem. And if it doesn't know how to handle a specific workflow, that's a skill problem. Both are solvable at the prompt and context layer. Where RL becomes interesting is when the failure pattern lives deeper in the model's reasoning itself. Things like consistently poor tool selection order, weak multi-step planning, or failing to interpret ambiguous instructions the way a specific user intends. Research on agentic RL (like ARTIST and Agent-R1) has shown that these behavioral patterns hit a ceiling with prompt-based approaches alone, especially in complex multi-turn tasks where the model needs to recover from tool failures or adapt its strategy mid-execution. That's the layer OpenClaw-RL targets, and it's a meaningful distinction from what OpenClaw offers. I have shared the repo in the replies!
→ View original post on X — @akshay_pachaar, 2026-04-12 13:35 UTC