Strix GitHub:
https://github.com/usestrix/strix Paper:
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6372438
…
@akshay_pachaar
-
Strix GitHub and Shared Academic Paper
By
–
-

Google DeepMind Reveals AI Agent Traps Framework
By
–
Google DeepMind dropped a paper that should scare every agent builder. It's the first systematic framework for a threat that barely existed two years ago: adversarial content engineered to hijack AI agents browsing the web. They call them AI Agent Traps. The paper maps six
-

Harnessed LLM Agent Architecture: Intelligence Through Modular Composition
By
–
A harnessed LLM agent.
— Akshay 🚀 (@akshay_pachaar) 18 avril 2026
Most people picture this as a model with tools bolted on. The real architecture inverts that relationship.
The model itself is deliberately thin. Intelligence gets pushed outward, and the harness composes it at runtime.
Three dimensions orbit the harness… https://t.co/MiA6mrH64m pic.twitter.com/tBUHQn4e3NA harnessed LLM agent. Most people picture this as a model with tools bolted on. The real architecture inverts that relationship. The model itself is deliberately thin. Intelligence gets pushed outward, and the harness composes it at runtime. Three dimensions orbit the harness
-

Claude Source Code Reverse-Engineered: Agent Architecture Insights
By
–
Claude Code fully dissected! Researchers from UCL reverse-engineered the leaked Claude source. What they found changes how you should think about agent design. Only 1.6% of the codebase is AI decision logic. The other 98.4% is operational infrastructure. Permission gates, tool
-
Essential LLM Fine-Tuning Techniques to Master
By
–
LLM fine-tuning techniques I'd learn if I were to customize them:
— Akshay 🚀 (@akshay_pachaar) 17 avril 2026
Bookmark this.
1. LoRA
2. QLoRA
3. Prefix Tuning
4. Adapter Tuning
5. Instruction Tuning
6. P-Tuning
7. BitFit
8. Soft Prompts
9. RLHF
10. RLAIF
11. DPO (Direct Preference Optimization)
12. GRPO (Group Relative… pic.twitter.com/EiUmhJVQjdLLM fine-tuning techniques I'd learn if I were to customize them: Bookmark this. 1. LoRA
2. QLoRA
3. Prefix Tuning
4. Adapter Tuning
5. Instruction Tuning
6. P-Tuning
7. BitFit
8. Soft Prompts
9. RLHF
10. RLAIF
11. DPO (Direct Preference Optimization)
12. GRPO (Group Relative -
Microsoft Releases Memento Paper and Dataset for AI Research
By
–
find the paper and dataset here: https://
github.com/microsoft/meme
nto?tab=readme-ov-file
… -
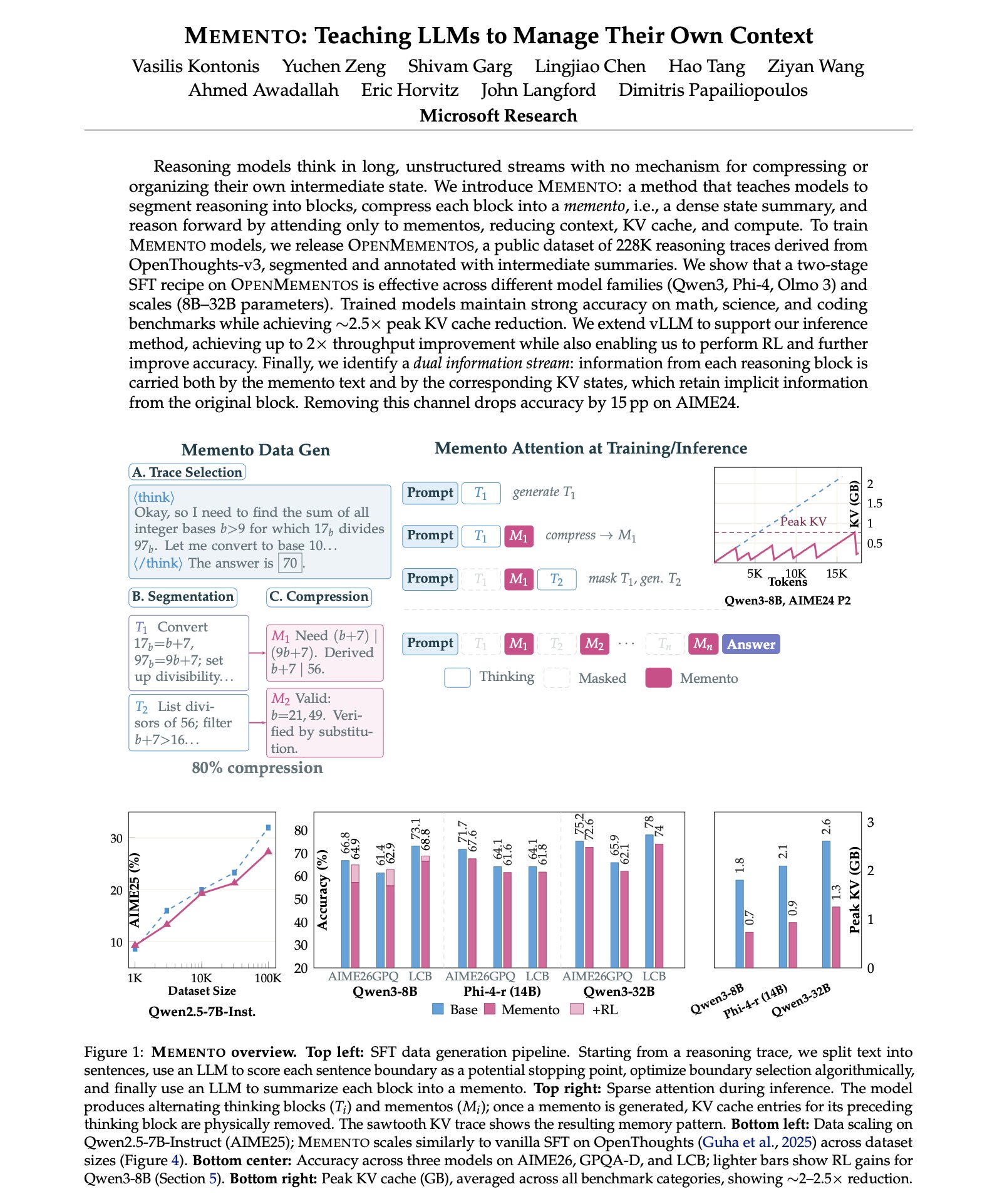
Microsoft MEMENTO: LLM Reasoning Context Compression Method
By
–
Microsoft just mass-compressed LLM reasoning. their new paper introduces MEMENTO, a method that teaches reasoning models to manage their own context. instead of letting chain-of-thought grow into a flat 32K-token stream, the model learns to segment its reasoning into blocks,
-

Agent Engineering Evolution: Environment Over Model Power 2022-2026
By
–
from weights → context → harness engineering (evolution of agent landscape from 2022-26) the biggest shift in AI agents had nothing to do with making models smarter. it was about making the environment around them smarter. here's how agent engineering evolved in just 4
-

Agent Memory Systems: The Challenge of Forgetting Irrelevant Data
By
–
Knowing what to forget is harder! Most agent memory systems focus on ingestion. Add more documents, build more embeddings, extract more entities. The graph only grows. But a memory that never forgets isn't actually useful. Stale nodes and unused connections pile up over time,
