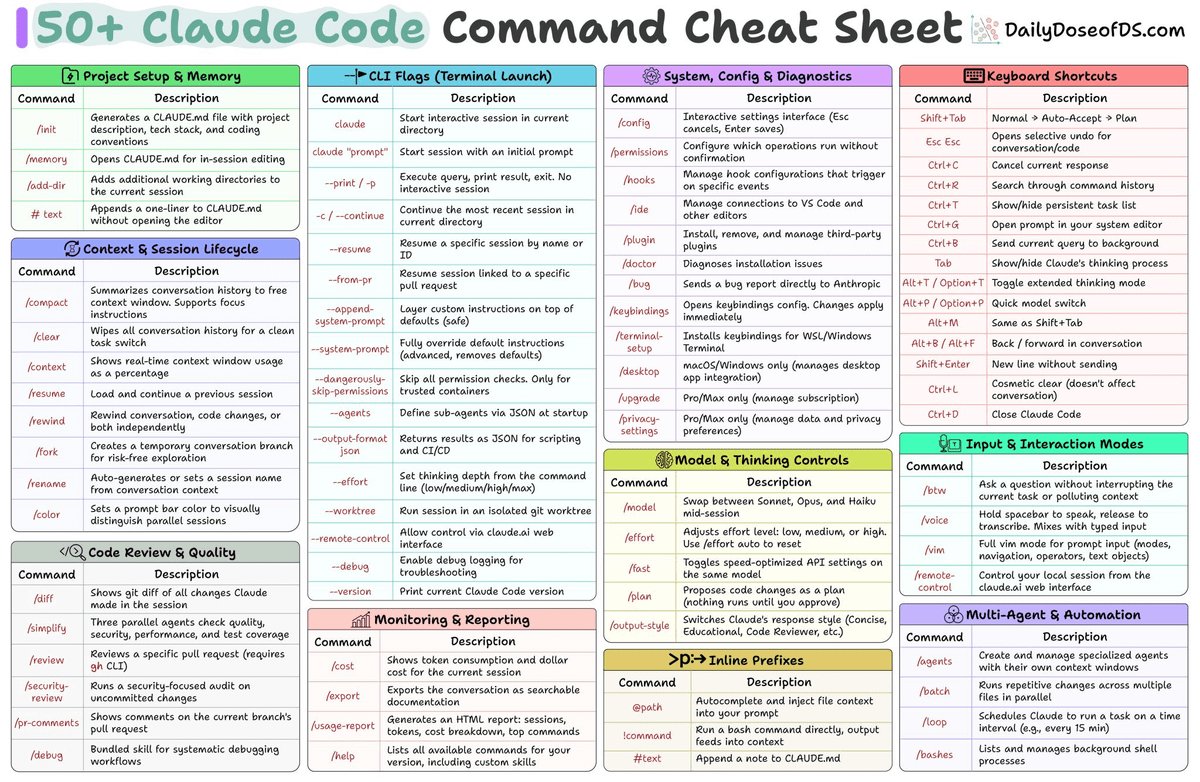
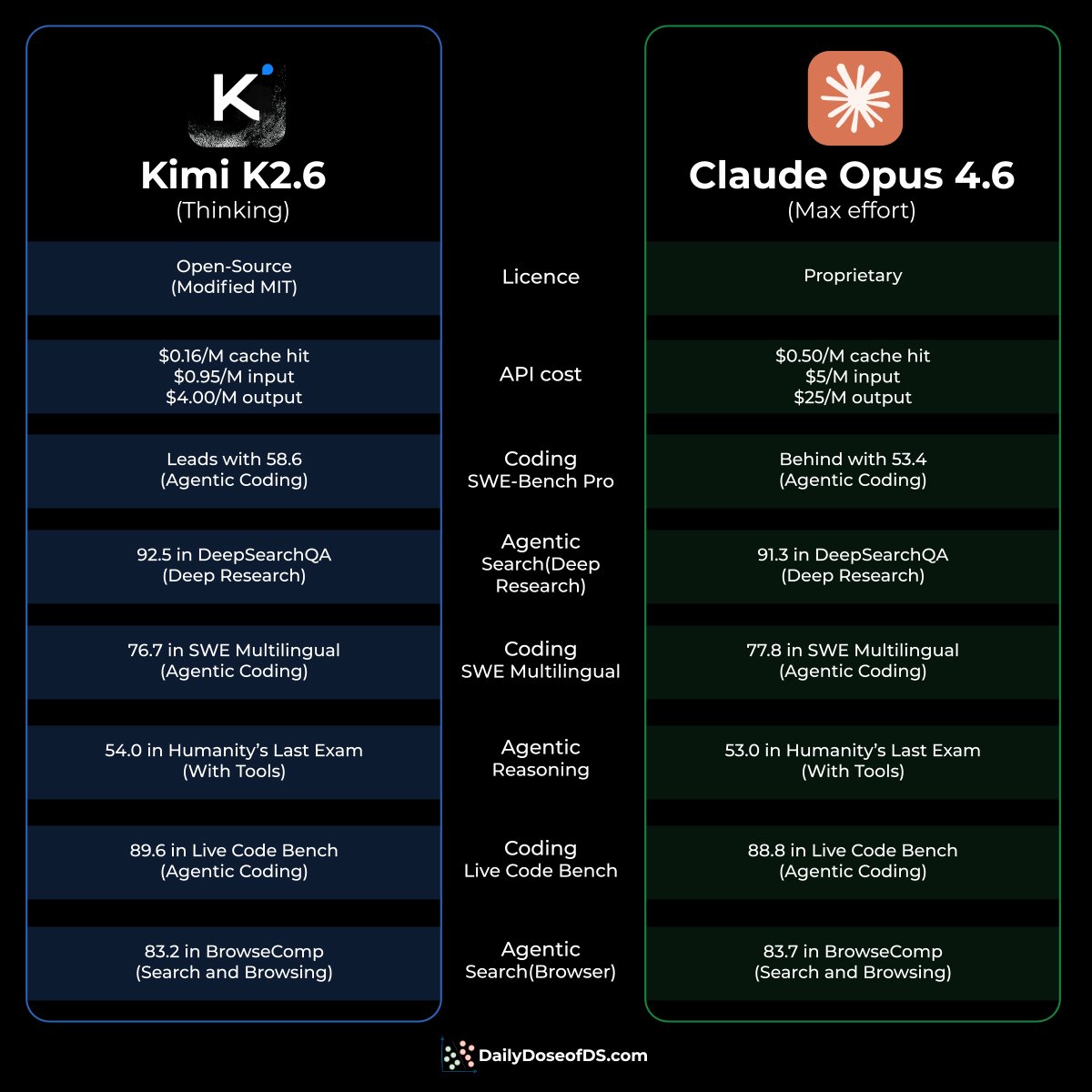
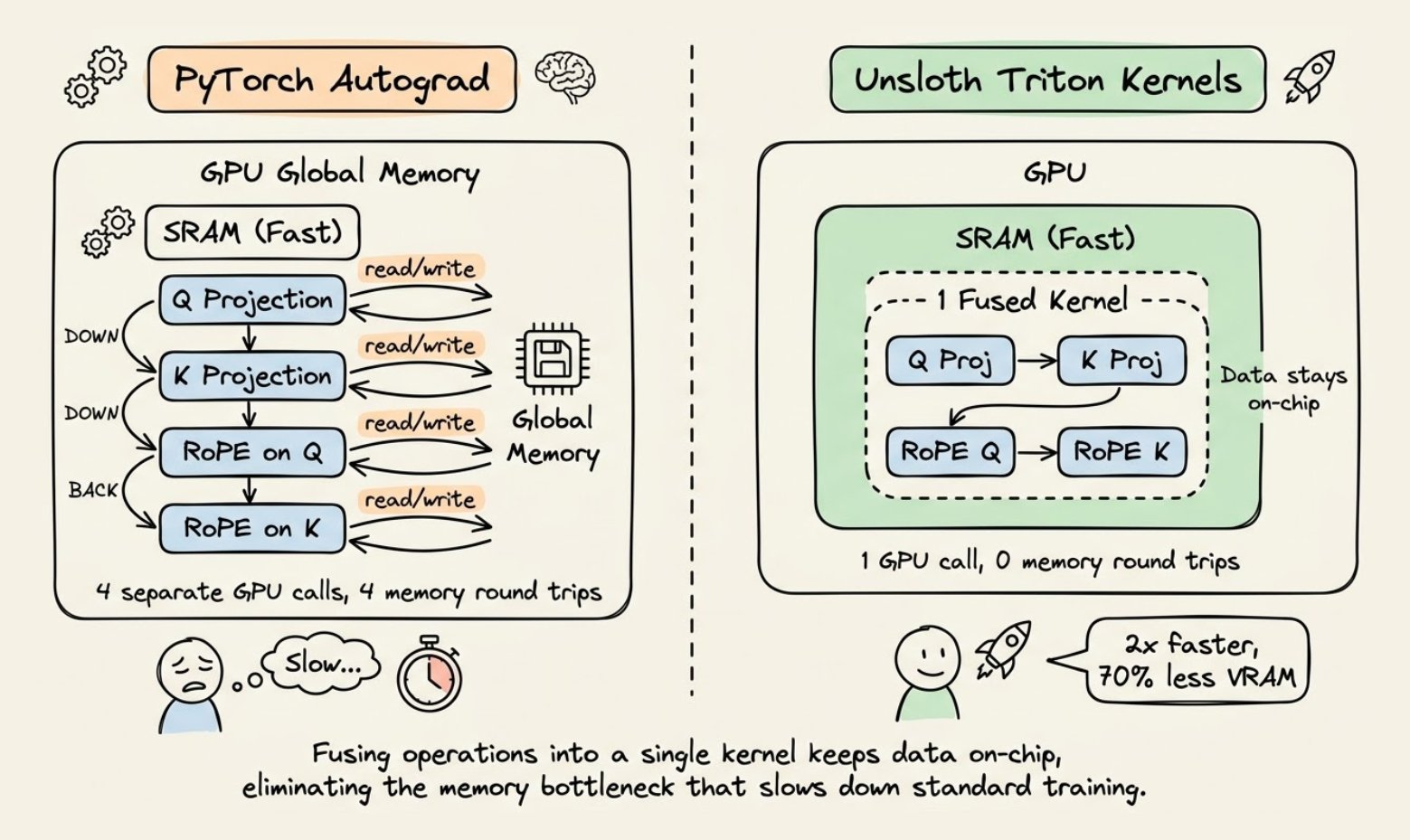
A great LLM interview question:
— Akshay 🚀 (@akshay_pachaar) 25 avril 2026
(answer shared below)
You have 80k Agent-user interactions from production. You need to find the top 100 worth reviewing to improve the agent.
You cannot use an LLM to evaluate them since it will be expensive.
This is one of the most painful… pic.twitter.com/nXS2nYGiC0
A great LLM interview question: (answer shared below) You have 80k Agent-user interactions from production. You need to find the top 100 worth reviewing to improve the agent. You cannot use an LLM to evaluate them since it will be expensive. This is one of the most painful