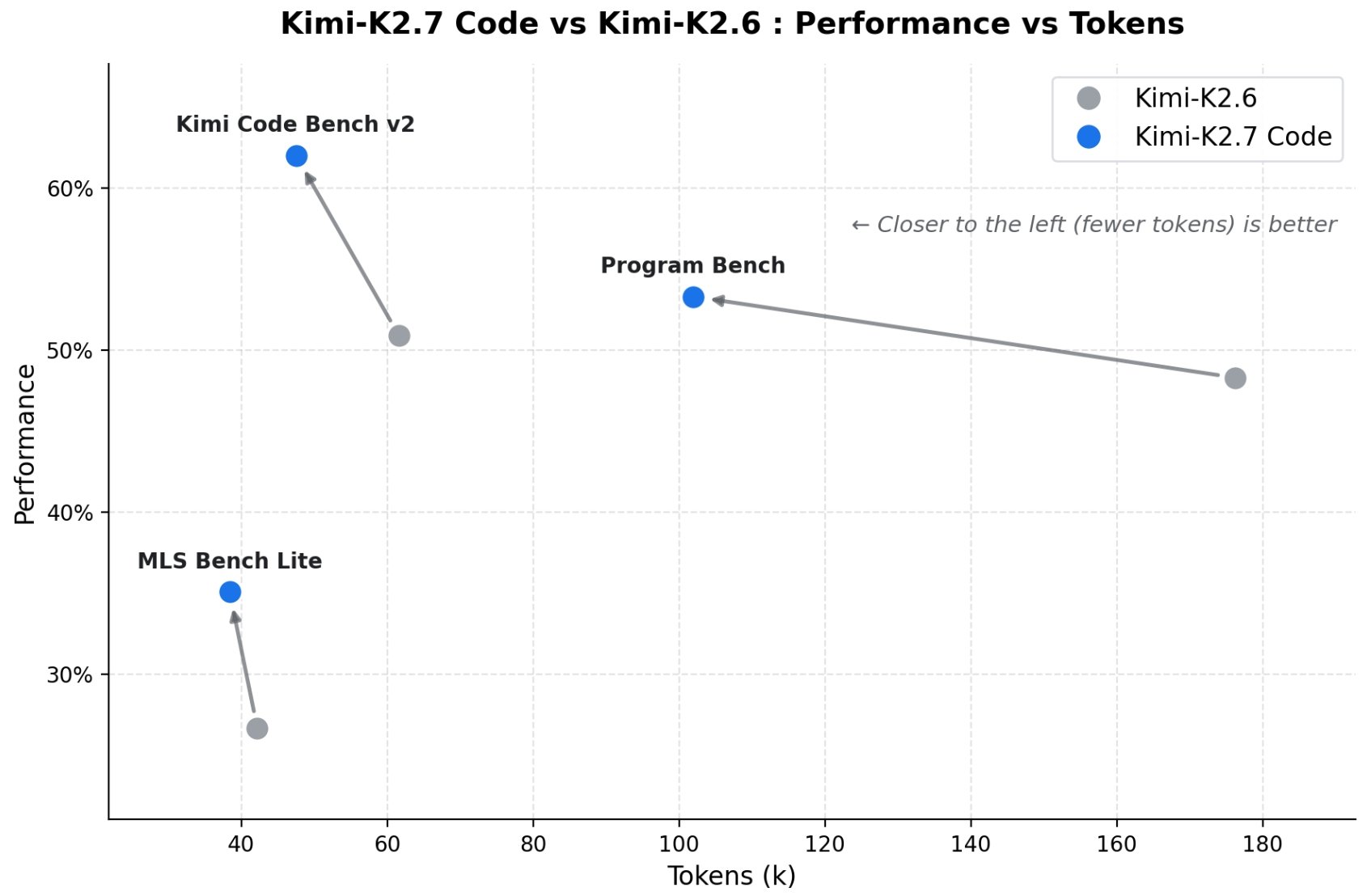
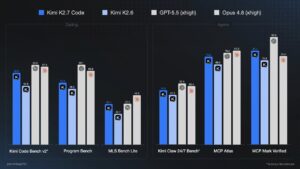
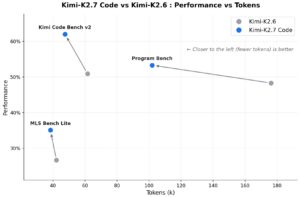
The less your model thinks, the better it codes. Kimi K2.7 Code proved it. The entire reasoning model space has been moving in one direction. More thinking tokens, longer chains, bigger reasoning budgets. Kimi just challenged that. K2.7 Code scores higher than K2.6 on every