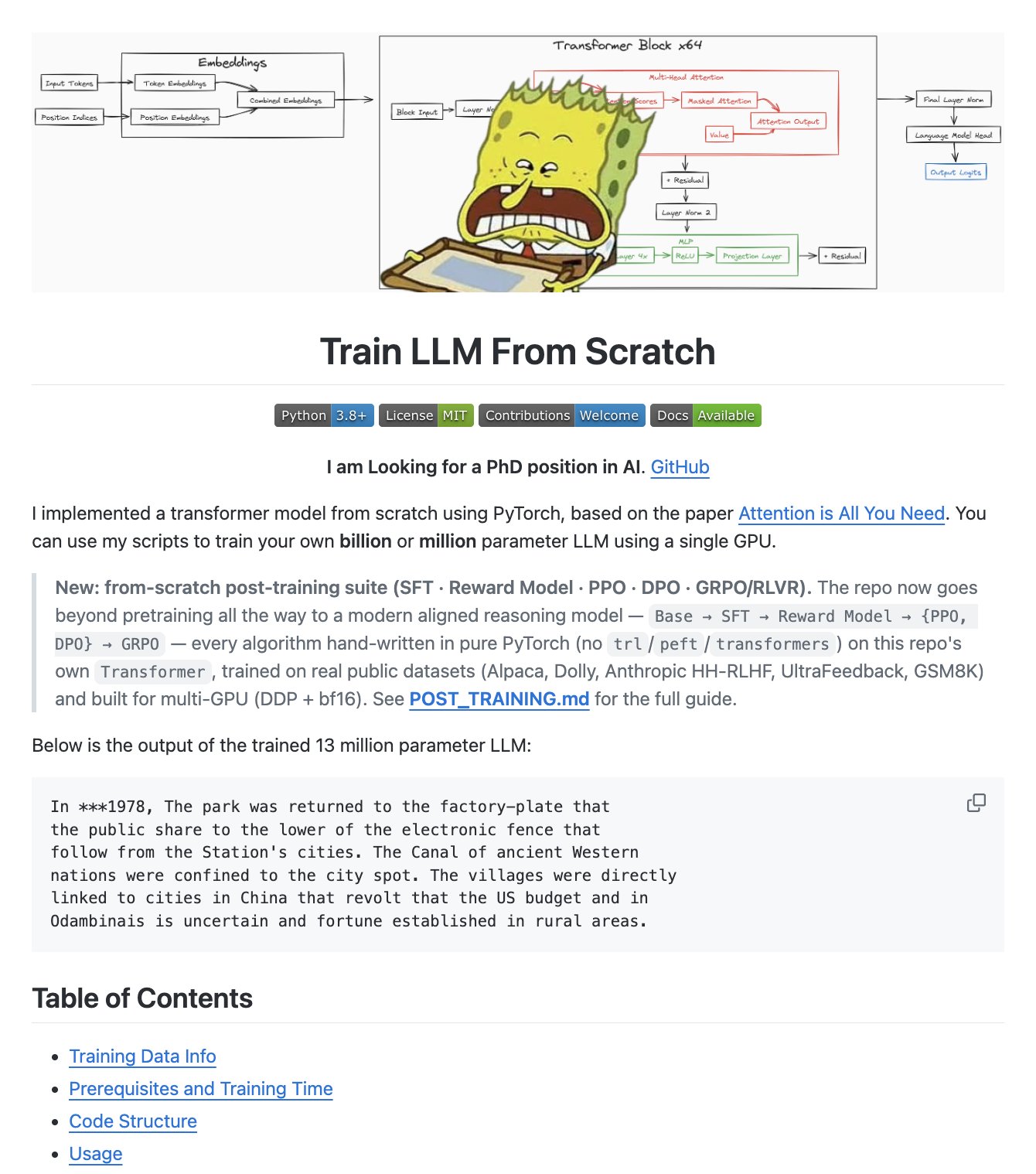
Web scraping will never be the same.
— Akshay 🚀 (@akshay_pachaar) 20 juin 2026
(100% open-source visual search at scale)
PixelRAG is a retrieval system that skips HTML parsing completely.
Instead of scraping a page into text and embedding chunks, it screenshots the page and retrieves the image. A vision-language model… https://t.co/tYKRgKDvSR pic.twitter.com/3dxYra0tZZ
Web scraping will never be the same. (100% open-source visual search at scale) PixelRAG is a retrieval system that skips HTML parsing completely. Instead of scraping a page into text and embedding chunks, it screenshots the page and retrieves the image. A vision-language model