Good solution. Btw, Once you’ve identified the high-signal trajectories, you can also pair them with counterfactual continuations (what the agent should have done at the point of failure) to construct preference pairs for DPO. So the signals don't just act as a debugging tool
@akshay_pachaar
-
InsForge: Open-Source Backend Solution for AI Coding Agents
By
–
AI agents suck at backend.
— Akshay 🚀 (@akshay_pachaar) 11 avril 2026
They ship beautiful frontends in seconds, but completely fall apart the moment you ask for a database, auth, or storage.
InsForge is an open-source solution, built natively for AI coding agents and editors. It exposes backend primitives like… pic.twitter.com/S5YvYSUkAHAI agents suck at backend. They ship beautiful frontends in seconds, but completely fall apart the moment you ask for a database, auth, or storage. InsForge is an open-source solution, built natively for AI coding agents and editors. It exposes backend primitives like databases, auth, storage, and functions through a semantic layer that agents can understand, reason about, and operate end-to-end. It works with any agent you already use, whether that is Cursor, Claude Code, Codex, OpenClaw, or Hermes. 100% open source. GitHub repo: github.com/InsForge/InsForge (don't forget to star 🌟)
→ View original post on X — @akshay_pachaar, 2026-04-11 12:40 UTC
-
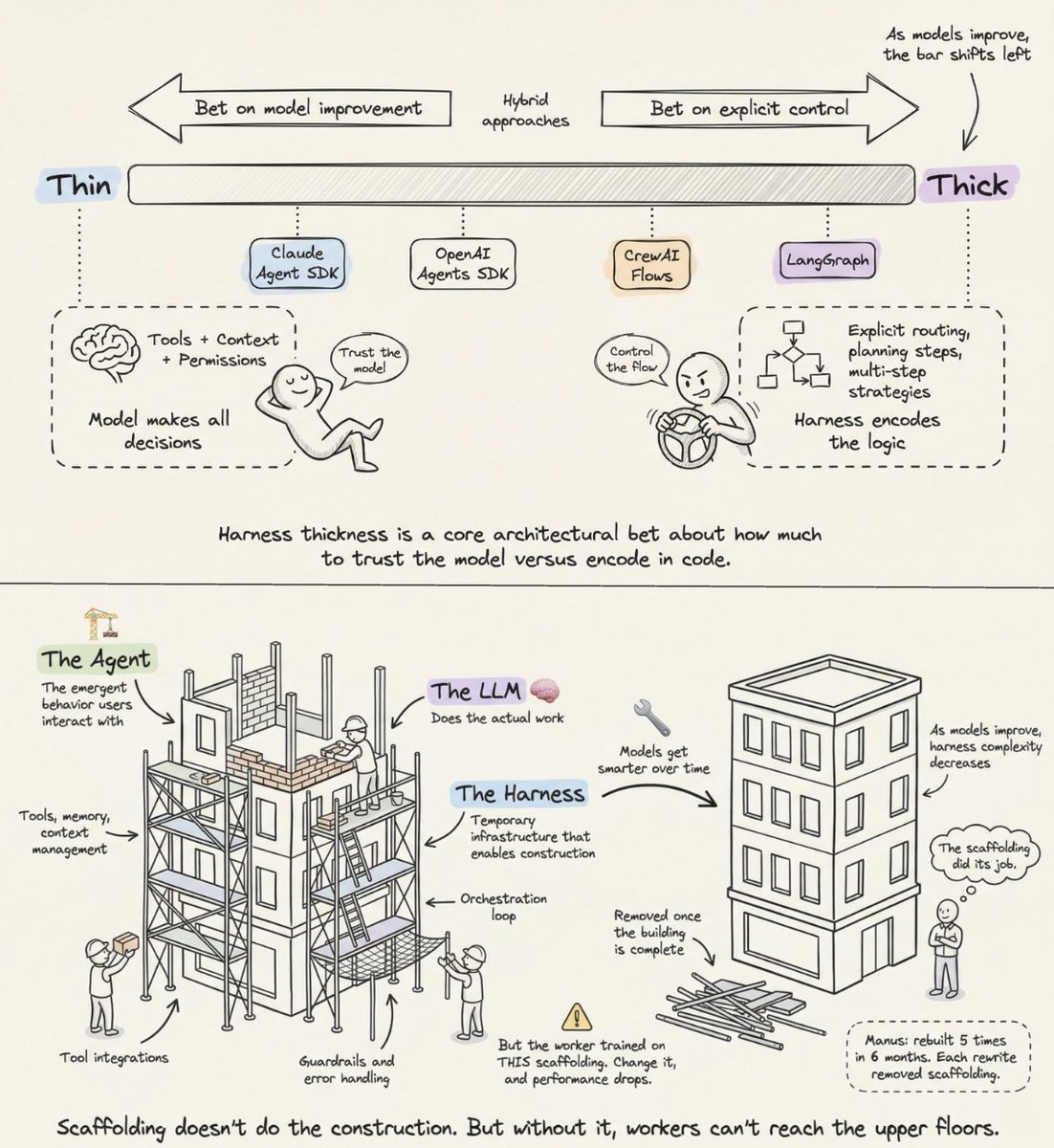
Agent Harness: The Infrastructure Bet Defining AI Architecture
By
–
What does every big company think about the agent harness? Anthropic, OpenAI, CrewAI, LangChain. They all build agents. They all wrap their models in infrastructure to make them useful. They each call it the harness. But they agree on one thing. And disagree on everything else. The agreement: the model is not the product. The infrastructure around the model is. The disagreement: how much of that infrastructure should exist. This is the most important architectural bet in AI right now. And each company is placing a different one. 𝗔𝗻𝘁𝗵𝗿𝗼𝗽𝗶𝗰 bets on the model. Their harness is deliberately thin. A "dumb loop" that assembles the prompt, calls the model, executes tool calls, and repeats. The model makes all the decisions. The harness just manages turns. Their bet: as models get smarter, you need less infrastructure, not more. 𝗢𝗽𝗲𝗻𝗔𝗜 takes a similar but slightly thicker approach. Their Agents SDK is "code-first," meaning workflow logic lives in native Python, not in some graph DSL. But they add more structure: strict priority stacks for instructions, multiple orchestration modes, and explicit agent handoff patterns. 𝗖𝗿𝗲𝘄𝗔𝗜 adds a deterministic backbone. Their Flows layer handles routing and validation with hard-coded logic, while their Crews handle the autonomous parts. Intelligence where it matters, control everywhere else. 𝗟𝗮𝗻𝗴𝗚𝗿𝗮𝗽𝗵 bets on explicit control. The harness encodes the logic. Every decision point is a node in a graph. Every transition is a defined edge. Planning steps, routing strategies, multi-step workflows are all spelled out in the harness, not left to the model. Notice the spectrum. On one end: trust the model, keep the harness thin. On the other: encode the logic, make the harness thick. And here's where it gets interesting. The scaffolding metaphor makes this concrete. Construction scaffolding is temporary infrastructure that lets workers reach floors they couldn't access otherwise. It doesn't do the building. But without it, workers can't reach the upper floors. The key word is temporary. As the building goes up, scaffolding comes down. Manus demonstrated this perfectly. They rebuilt their agent five times in six months. Each rewrite removed complexity. Complex tool definitions became simple shell commands. "Management agents" became basic handoffs. The scaffolding did its job. So they removed it. This is also why Anthropic regularly deletes planning steps from Claude Code's harness. Every time a new model version ships that can handle something internally, the corresponding harness logic gets stripped out. But there's a catch. Models are now trained with specific harnesses in the loop. Claude Code's model learned to use the exact scaffolding it was built with. Change the scaffolding, and performance drops. The worker trained on THIS scaffolding. Swap it out, and they stumble. So the field is converging on a principle: Build scaffolding that's designed to be removed. But remove it carefully, because the model learned to lean on it. The "future-proofing test" for any agent system: if dropping in a more powerful model improves performance without adding harness complexity, the design is sound. Two products using the exact same model can perform completely differently based on this one decision: how thick is the harness? LangChain changed only the infrastructure (same model, same weights) and jumped from outside the top 30 to rank 5 on TerminalBench 2.0. The model didn't improve. The scaffolding around it did. The article below is a deep dive on agent harness engineering, covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent. Akshay 🚀 (@akshay_pachaar) x.com/i/article/204073208484… — https://nitter.net/akshay_pachaar/status/2041146899319971922#m
→ View original post on X — @akshay_pachaar, 2026-04-10 12:51 UTC
-
Unsloth Studio Colab Notebook for LLM Fine-tuning
By
–
Here's the notebook: colab.research.google.com/gi… If this was helpful, reshare with your network. Find me → @akshay_pachaar ✔️ For more insights and tutorials on LLMs, AI Agents, and Machine Learning!
→ View original post on X — @akshay_pachaar, 2026-04-10 07:49 UTC
-
Free Google Gemma 4 Fine-tuning with Unsloth Colab Notebook
By
–
Fine-tune Google Gemma 4 completely FREE!
— Akshay 🚀 (@akshay_pachaar) 10 avril 2026
All you need is a browser and 500+ models to choose from.
The process is simple:
1. Open the Unsloth Colab notebook
2. Pick your model and dataset
3. Hit start training
And you're done! pic.twitter.com/YAyyFeN7HxFine-tune Google Gemma 4 completely FREE! All you need is a browser and 500+ models to choose from. The process is simple: 1. Open the Unsloth Colab notebook 2. Pick your model and dataset 3. Hit start training And you're done!
→ View original post on X — @akshay_pachaar, 2026-04-10 07:49 UTC
-

Advisor Models: Pairing Weak and Strong AI for Cost-Efficient Intelligence
By
–

this is one of the most important ideas in AI right now, and it just got two independent validations. yesterday, Anthropic shipped an "advisor tool" in the Claude API that lets Sonnet or Haiku consult Opus mid-task, only when the executor needs help. the benefit is straightforward: you get near Opus-level intelligence on the hard decisions while paying Sonnet or Haiku rates for everything else. frontier reasoning only kicks in when it's actually needed, not on every token. back in February, UC Berkeley published a paper called "Advisor Models" that trains a small 7B model with RL to generate per-instance advice for a frozen black-box model. same idea. two very different implementations. the paper's approach: take Qwen2.5 7B, train it with GRPO to generate natural language advice, and inject that advice into the prompt of a black-box model. the black-box model never changes. the advisor learns what to say to make it perform better. GPT-5 scores 31.2% on a tax-filing benchmark. add the trained advisor, it jumps to 53.6%. on SWE agent tasks, a trained advisor cuts Gemini 3 Pro's steps from 31.7 to 26.3 while keeping the same resolve rate. training is cheap too. you train with GPT-4o Mini, then swap in GPT-5 at inference. the advisor even transfers across families: a GPT-trained advisor improves Claude 4.5 Sonnet. Anthropic's advisor tool takes a different path to the same idea. Sonnet runs as executor, handles tools and iteration. when it hits something it can't resolve, it consults Opus, gets a plan or correction, and continues. Sonnet with Opus as advisor gained 2.7 points on SWE-bench Multilingual over Sonnet alone, while costing 11.9% less per task. Haiku with Opus scored 41.2% on BrowseComp, more than double its solo 19.7%. it's a one-line API change. advisor tokens bill at Opus rates, and the advisor typically generates only 400-700 tokens per call. blended cost stays well below running Opus end-to-end. both approaches point at the same thing: you don't need the most powerful model on every token. you need it at the right moments, for the right inputs. Paper: arxiv.org/abs/2510.02453 Code: github.com/az1326/advisor-mo… Claude (@claudeai) We're bringing the advisor strategy to the Claude Platform. Pair Opus as an advisor with Sonnet or Haiku as an executor, and get near Opus-level intelligence in your agents at a fraction of the cost. — https://nitter.net/claudeai/status/2042308622181339453#m
→ View original post on X — @akshay_pachaar, 2026-04-10 05:46 UTC
-
Understanding AI Agents: Components and Orchestration Explained
By
–
A simple way to think about AI agents: LLM = reasoning Tools = actions Memory = context Orchestration = the loop The first three are components. The last one is what makes them an agent.
→ View original post on X — @akshay_pachaar, 2026-04-09 20:21 UTC
-
Building AI Brains: Why Local First Architecture Matters
By
–
Absolutely! If you're building an AI brain, you cannot send the entire data to any API. Local first is a must.
-
Open-Source Claude Alternative with Local AI and Voice Support
By
–
If you found it insightful, reshare with your network.
— Akshay 🚀 (@akshay_pachaar) 8 avril 2026
Find me → @akshay_pachaar ✔️
For more insights and tutorials on LLMs, AI Agents, and Machine Learning! https://t.co/GaVYhQRixwIf you found it insightful, reshare with your network. Find me → @akshay_pachaar ✔️ For more insights and tutorials on LLMs, AI Agents, and Machine Learning! Akshay 🚀 (@akshay_pachaar) Another blow to Anthropic! Devs built a free and better Claude Cowork alternative: – 100% local – voice-enabled – works with any LLM – MCP tool extensibility – obsidian-compatible vault – background agents & web search – automatic knowledge graph creation 100% open-source. — https://nitter.net/akshay_pachaar/status/2041856590341677378#m
→ View original post on X — @akshay_pachaar, 2026-04-08 12:32 UTC
-
Free Open-Source Claude Alternative with Local AI and MCP Support
By
–
Another blow to Anthropic!
— Akshay 🚀 (@akshay_pachaar) 8 avril 2026
Devs built a free and better Claude Cowork alternative:
– 100% local
– voice-enabled
– works with any LLM
– MCP tool extensibility
– obsidian-compatible vault
– background agents & web search
– automatic knowledge graph creation
100% open-source. pic.twitter.com/8KHJGzP71GAnother blow to Anthropic! Devs built a free and better Claude Cowork alternative: – 100% local – voice-enabled – works with any LLM – MCP tool extensibility – obsidian-compatible vault – background agents & web search – automatic knowledge graph creation 100% open-source.
→ View original post on X — @akshay_pachaar, 2026-04-08 12:32 UTC