No obvious safety hazards. Gemma 4 is Google's official open-source model, the App runs completely offline, all processing is done on the local device, with no internet connection or data upload, providing good privacy protection. It is recommended to download from the official
SOFTWARE
-
Google Releases Gemma 4 Open-Source Model for Mobile Devices
By
–
Yes! Google did indeed release the Gemma 4 open-source model on April 2, optimized specifically for mobile devices, running fully offline without any internet connection or data uploads. The Google AI Edge Gallery App is now live on the App Store and Google Play, and you can
-
Flova AI integrates Seedance 2.0 for accessible cinematic video creation
By
–
Creating a cinematic short drama shouldn't require a master's degree in software engineering.
— Charly Wargnier (@DataChaz) 5 avril 2026
It should be about your vision.
Enter @Flovaai × Seedance 2.0 🔥
→ https://t.co/xRIH62ZqzL
They’ve integrated the ace capabilities of Seedance 2.0 into the Flova platform to give… https://t.co/a8YOwPHPEtCreating a cinematic short drama shouldn't require a master's degree in software engineering. It should be about your vision. Enter @Flovaai × Seedance 2.0 🔥 → flova.ai/en/?refCode=TKZPP8B… They’ve integrated the ace capabilities of Seedance 2.0 into the Flova platform to give you a true all-in-one filmmaking workflow. What does this mean for your stories? → Visually striking outputs with fluid, natural character motion. → Fast, stable generation so your creative flow is never interrupted. → A seamless journey from your first storyboard sketch to your final video export. Plus, they’ve introduced 'Quick Access', meaning you can boot up Seedance 2.0 or NanoBanana with one click. … and if you’re producing at scale? PRO subscribers can run 50 (!) concurrent generations at once to build scenes in record time. I hadn’t come across Flova AI before, but it’s definitely on my radar now 👀 #Flovaai #Flovaseedance #Seedance2_0 #AIShorts #VideoCreation FlovaAI (@Flovaai) Flova now integrates Seedance 2.0 — unlocking next-level AI video creation. With Seedance 2.0, you get: • High-quality, long-form video generation • Strong motion consistency and cinematic output • Faster generation with significantly improved efficiency Flova also introduces a new Quick Access feature — instantly launch Seedance 2.0 or even NanoBanana with just one click. No complex setup, no prompt engineering required. And the best part? Lower cost, higher value — create more, spend less. #Flovaai #Seedance #aivideo — https://nitter.net/Flovaai/status/2039903951324406240#m
-
DataHub Intelligence: Manufacturing Data Middleware Solution
By
–
DataHub Intelligence sits between your existing systems and analytics tools.
— Lucian Fogoros (@fogoros) 5 avril 2026
It reads operational data in place, adds manufacturing context, then delivers structured datasets for AI, analytics. The middleware your data team needed. PartnerContent with @HighbyteInc. #highbyte_iiot pic.twitter.com/enbDGdM9fLDataHub Intelligence sits between your existing systems and analytics tools. It reads operational data in place, adds manufacturing context, then delivers structured datasets for AI, analytics. The middleware your data team needed. PartnerContent with @HighbyteInc. #highbyte_iiot
-
Levangie Labs Agents Outperform Hermes on Cloud Infrastructure
By
–
Although the site is done by agents created by Levangie Labs running on cloud. Better than what Hermes can do.
-
Scaling Data Ingestion Without Breaking the Platform
By
–
Scaling Data Ingestion from Hundreds to Thousands of Sources Without Breaking the Platform tinyurl.com/49adj6yc via @LinkedIn #ArtificialIntelligence #GenerativeAI #EnterpriseAI #AIArchitecture #DataArchitecture #DataPlatforms #AIStrategy #CIO #CTO #ChiefDataOfficer #ExecutiveLeadership #AgenticAI #RAG [Translated from EN to English]
→ View original post on X — @craigbrownphd, 2026-04-05 19:38 UTC
-

TurboQuant-GPU: 5x KV Cache Compression for Any GPU
By
–
pip install turboquant-gpu 5.02x KV cache compression for ANY GPU (RTX, H100, A100, B200) – works over @huggingface transformers – dead-simple API: compress + generate in 3 lines – 3-bit Lloyd-Max fused KV compression (0.98 cosine similarity) – outperforms MXFP4 (3.76x) and NVFP4 (3.56x) on compression Ran Mistral-7B: 1,408 KB → 275 KB KV cache (5.02x) Quickstart: github.com/DevTechJr/turboqu… Written in cuTile (CUDA 12, 13) with PyTorch fallbacks
→ View original post on X — @huggingface, 2026-04-05 19:30 UTC
-
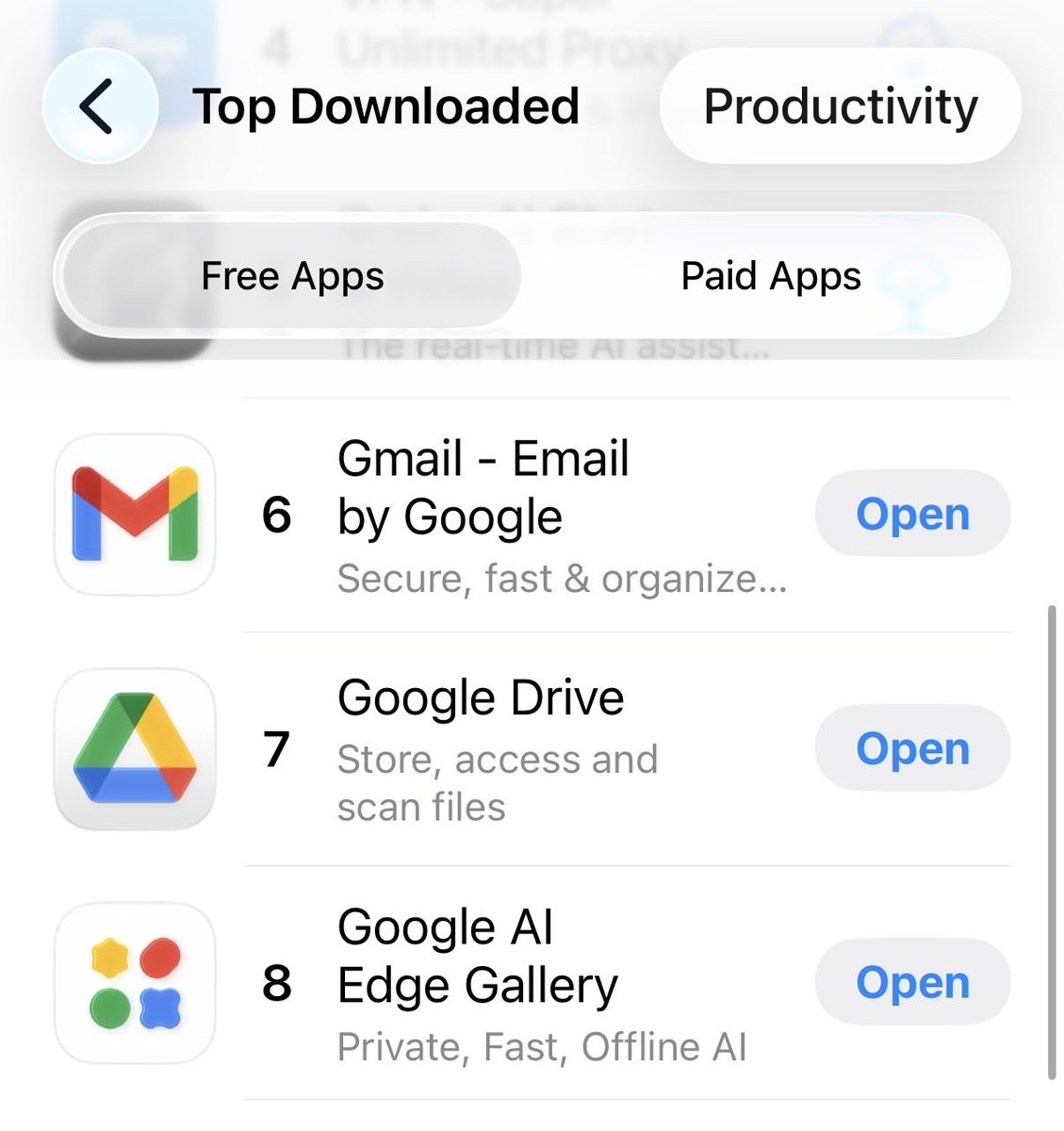
Gemma 4 Demand High, Google AI Edge Ranks #8 iOS
By
–
Lots of people want Gemma 4! Google AI Edge is #8 on the iOS App Store for productivity apps.
→ View original post on X — @demishassabis, 2026-04-05 19:29 UTC
-

Qwen3.6-Plus Launches: Advanced Agentic Coding and Multimodal AI
By
–

Qwen3.6-Plus has been added to Design Arena! Delivering state-of-the-art agentic coding from frontend designs to complex repo-level problem solving, with sharper multimodal perception and more stable performance. Qwen (@Alibaba_Qwen) (1/8)🚀 Introducing Qwen3.6-Plus: Towards Real-World Agents! 🤖 Today, we’re thrilled to drop a major milestone in our journey toward native multimodal agents. Here is what makes Qwen3.6-Plus a game-changer: 💻 Next-level Agentic Coding: Smarter, faster execution. 👁️ Enhanced Multimodal Vision: Sharper perception & reasoning. 🏆 Top-tier Performance: Maintaining leading general capabilities. 📚 1M Context Window: Available by default via our API. Built on your invaluable feedback from the Qwen3.5 era, we’re laying a rock-solid foundation for real-world devs. Get ready to experience truly transformative ✨ Vibe Coding ✨. Huge thanks to our community! Go try it out and show us what you can build. 👇 Chat: chat.qwen.ai/ API: modelstudio.console.alibabac… Blog: qwen.ai/blog?id=qwen3.6 🔔Noted:More Qwen3.6 models to come and be open-sourced! Stay tuned~ 👀#Qwen #AI #AgenticCoding #VibeCoding #Agents — https://nitter.net/Alibaba_Qwen/status/2039705104723611829#m
→ View original post on X — @deeplearn007, 2026-04-05 19:20 UTC
-

HISA: Hierarchical Indexing for Efficient Sparse Attention in LLMs
By
–
"HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention" Sparse attention can still be slow. And the slow part is often not the attention step itself, but the search step that scans the whole context to find useful tokens. This paper's HISA makes that search cheaper. It first finds the best blocks, then finds the best tokens inside those blocks. This keeps token-level precision, needs no retraining, works with the same downstream attention, and gives up to 3.75x speedup while staying close to the original quality.
→ View original post on X — @askalphaxiv, 2026-04-05 19:06 UTC