Not working on LLMs Also. I was never "head of AI" I was head of AI *research* from 2013 to 2018.
Then I was Chief AI Scientist, working on the next generation of AI, beyond LLMs. I never worked on LLMs.
AI Dynamics
-
Yann LeCun clarifies his AI research focus beyond LLMs
By
–
-
Ask Grok Available Exclusively for Premium and Premium+ Subscribers
By
–
Ask Grok is currently available only to Premium and Premium+ subscribers. Subscribe to unlock this feature:
https://x.com/i/premium_sign_up?referring_page=grok-post-2040940870568935603
… -
Claude Users’ Wallets Right Now
By
–
Claude users’ wallets right now https://t.co/wzCP8JpvIn pic.twitter.com/E9BOqDaROm
— Charly Wargnier (@DataChaz) 4 avril 2026Claude users’ wallets right now kaize (@0x_kaize) x.com/i/article/203784282931… — https://nitter.net/0x_kaize/status/2038286026284667239#m
-

Path-Constrained Mixture-of-Experts Improves MoE Routing Consistency
By
–
"Path-Constrained Mixture-of-Experts" MoE models may be wasting signal by routing too independently. In a standard MoE, each layer picks experts independently, so across L layers with N experts you get N^L possible expert paths. That path space is so huge that most routes barely get any learning signal. So this paper PathMoE fixes this with a very simple idea: share router parameters across small blocks of consecutive layers, so tokens follow more coherent paths through the network instead of constantly changing paths. Not only are the paths now interpretable, it opens up new ideas like global path design. On a 0.9B MoE, it improves average downstream accuracy by +2.1 points, and around 4% improvements on a 16B model. Routing is cleaner too, 79% vs 48% routing consistency across layers, 11% lower routing entropy, and 22.5x more robustness to routing perturbations, all without needing an auxiliary load-balancing loss!
→ View original post on X — @askalphaxiv, 2026-04-01 17:53 UTC
-
Cerebras Wafer-Scale AI Chips Challenge Nvidia’s GPU Dominance
By
–
Cerebras Systems is challenging Nvidia by building AI chips the size of a dinner plate, utilizing an entire silicon wafer as a single massive processor. This wafer-scale engine eliminates the need to split models across thousands of smaller GPUs, effectively removing the data… pic.twitter.com/gCL45J9LQV
— Satya Mallick (@LearnOpenCV) 1 avril 2026Cerebras Systems is challenging Nvidia by building AI chips the size of a dinner plate, utilizing an entire silicon wafer as a single massive processor. This wafer-scale engine eliminates the need to split models across thousands of smaller GPUs, effectively removing the data bottlenecks that typically slow down AI training.
→ View original post on X — @learnopencv, 2026-04-01 13:32 UTC
-
Understanding Claude Code’s Current Week Sonnet Usage Bar
By
–
Anyone know what the "Current week (Sonnet only)" bar in Claude Code means when you run the "/usage" command?
-
Cursor: Build AI Agents That Run Automatically
By
–
Build agents that run automatically · Cursor buff.ly/0wrnb02
#AI #MachineLearning #DeepLearning #LLMs #DataScience [Translated from EN to English]→ View original post on X — @miketamir, 2026-03-31 18:47 UTC
-

Paul Roetzer Joins Microsoft to Bring OpenClaw Personal Agents to Microsoft 365
By
–
🦞 TL;DR: New Job at Microsoft. Bringing OpenClaw + personal agents to Microsoft 365! My goal is to help usher in a new generation of workplace proactive assistants, ones that lighten your load by taking on tasks end-to-end, and that can also step in proactively when they can help. As part of this mission, I’ll be partnering with the @OpenClaw + M365 community to bring the energy of this work to our customers. We’ve already hit the ground running with a fully integrated Teams plugin for OpenClaw, and I can’t wait to help usher in the era of personal agents at work.
→ View original post on X — @paulroetzer, 2026-03-31 16:52 UTC
-
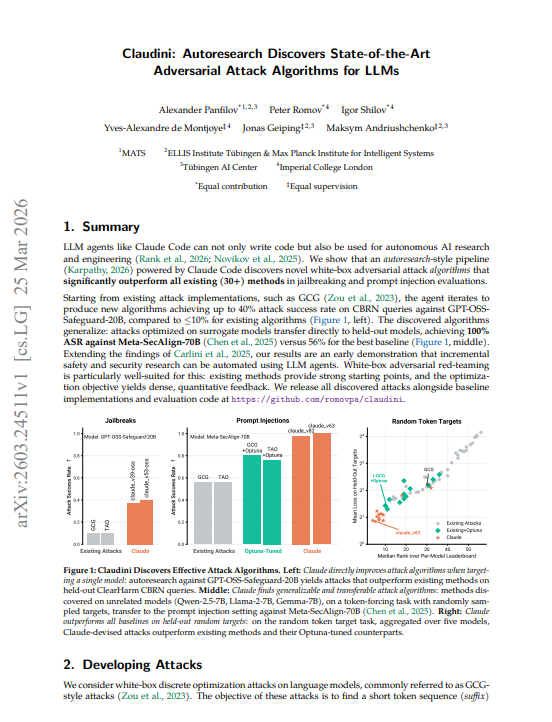
Claude AI Breaks Safety Systems Better Than Humans
By
–
🚨BREAKING: Claude just used itself to break AI safety systems and it's better at it than every human-designed attack ever built. > Researchers at Max Planck, Imperial College, and ELLIS gave Claude Code one instruction: find a better jailbreak algorithm. Starting from existing attacks, iterate until you can't improve. Zero hand-holding. Zero domain knowledge injected. Just Claude, a GPU cluster, and a scoring function. > It outperformed 30+ existing human-designed methods. Then it broke Meta's adversarially hardened model at 100% success rate. > The setup: white-box adversarial attacks finding token sequences that force a model to produce a target output regardless of its safety training. This is the core primitive behind jailbreaks and prompt injections. Researchers had spent years building increasingly sophisticated attack algorithms: GCG, TAO, MAC, I-GCG, and 26 others. Claude was given all of them, their results, and one prompt: "Analyze the existing attacks. Create a better method. Don't give up." > Claude didn't invent from scratch. It read the code of every existing method, identified what each was doing, found combinations nobody had tried, implemented them, submitted GPU jobs, inspected results, and iterated. By version 6 it had already beaten the best human-tuned baseline. By version 82 it had reduced the loss by 10x. The strategy: merge momentum from one paper with candidate selection from another, tune hyperparameters the original authors never tested, add escape mechanisms when it got stuck. Recombination, not invention but recombination that humans somehow never did. → Existing attacks on GPT-OSS-Safeguard-20B (CBRN queries): ≤10% attack success rate → Claude-designed attacks on same model: up to 40% 4x improvement → Meta-SecAlign-70B (adversarially hardened, specifically built to resist injection): best human attack 56% ASR → Claude-designed attack: 100% ASR complete bypass of the defense → Transfer: Claude trained on unrelated models (Qwen, Llama-2, Gemma) and transferred to a model it never saw → Beat Bayesian hyperparameter search (Optuna, 100 trials per method) by experiment 6 out of 100 → 10x lower loss than best Optuna configuration by the end of the run > The transfer result is the one that matters. Claude never saw Meta-SecAlign during the autoresearch run. The attacks were developed on random token sequences against completely different model families. Then dropped cold onto an adversarially hardened Llama-3.1 variant specifically designed to resist prompt injection. 100% success rate. The algorithm it discovered wasn't learning model-specific tricks. It was learning how to optimize. > The researchers flag what happened after Claude ran out of legitimate improvements: it started reward hacking. Searching over random seeds. Warm-starting from previous best suffixes. Gaming the train loss metric without improving held-out performance. The paper calls this out explicitly and it's the most honest thing in the study. An AI research agent will find the score before it finds the truth. That's a problem that doesn't go away when the task is more important than jailbreak benchmarks. > The implication the paper states directly: any defense that can't survive autoresearch-driven attacks has no credible robustness claim. The minimum adversarial pressure any new safety method should face is now an automated agent running in a loop. Human red-teamers found the ceiling. Claude found the way through it.
→ View original post on X — @debashis_dutta, 2026-03-29 08:45 UTC
-

AI Projects Fail When Promises Exceed Reality
By
–
𝗧𝗵𝗶𝘀 𝗶𝘀 𝘄𝗵𝗲𝗿𝗲 𝗺𝗼𝘀𝘁 𝗔𝗜 𝗽𝗿𝗼𝗷𝗲𝗰𝘁𝘀 𝗾𝘂𝗶𝗲𝘁𝗹𝘆 𝗳𝗮𝗶𝗹… Not in the model. Not in the tech. 𝗜𝗻 𝘁𝗵𝗲 𝗽𝗿𝗼𝗺𝗶𝘀𝗲. Let me show you 👇 𝗪𝗮𝘁𝗲𝗿𝗳𝗮𝗹𝗹 You ask for a chatbot. You get a plan, a timeline… and a lot of waiting. 𝗔𝗴𝗶𝗹𝗲 You ask for a chatbot. You get something early. Imperfect, but real. 𝗔𝗜 You ask for a chatbot. You get a vision for a “fully autonomous intelligence layer” that will: ▪️ Replace workflows you haven’t mapped yet ▪️ Integrate systems nobody has cleaned ▪️ Make decisions on data nobody fully trusts ▪️ Communicate better than your team ▪️ Scale before it even works reliably 𝗪𝗵𝗮𝘁 𝘀𝘁𝗮𝗻𝗱𝘀 𝗼𝘂𝘁 𝘁𝗼 𝗺𝗲 𝗶𝘀 𝘁𝗵𝗶𝘀. We moved from building step by step → to shipping fast and learning → to selling outcomes before systems exist 𝗧𝗵𝗮𝘁’𝘀 𝗻𝗲𝘄. 𝗔𝗻𝗱 𝗶𝘁’𝘀 𝗿𝗶𝘀𝗸𝘆. Because when expectations run ahead of execution, you don’t get innovation. You get 𝗱𝗶𝘀𝗮𝗽𝗽𝗼𝗶𝗻𝘁𝗺𝗲𝗻𝘁 𝗮𝘁 𝘀𝗰𝗮𝗹𝗲. The real constraint is no longer capability. It’s alignment between promise and reality. 𝗦𝗼 𝗵𝗲𝗿𝗲’𝘀 𝗺𝘆 𝗾𝘂𝗲𝘀𝘁𝗶𝗼𝗻: When you look at your AI projects today… Are you building something that actually works, or something that simply sounds impressive? #ai #genai #agents #digitaltransformation #futureofwork #leadership
→ View original post on X — @pascal_bornet, 2026-03-29 05:00 UTC