Copper is used everywhere. In your phones, pipes, cars, roofs, and even AI! That's why KME, one of the world’s largest manufacturers of copper and copper‑alloy products, needed software to manage its vast amounts of data and ensure efficiency. See SAS' solution:
SOFTWARE
-
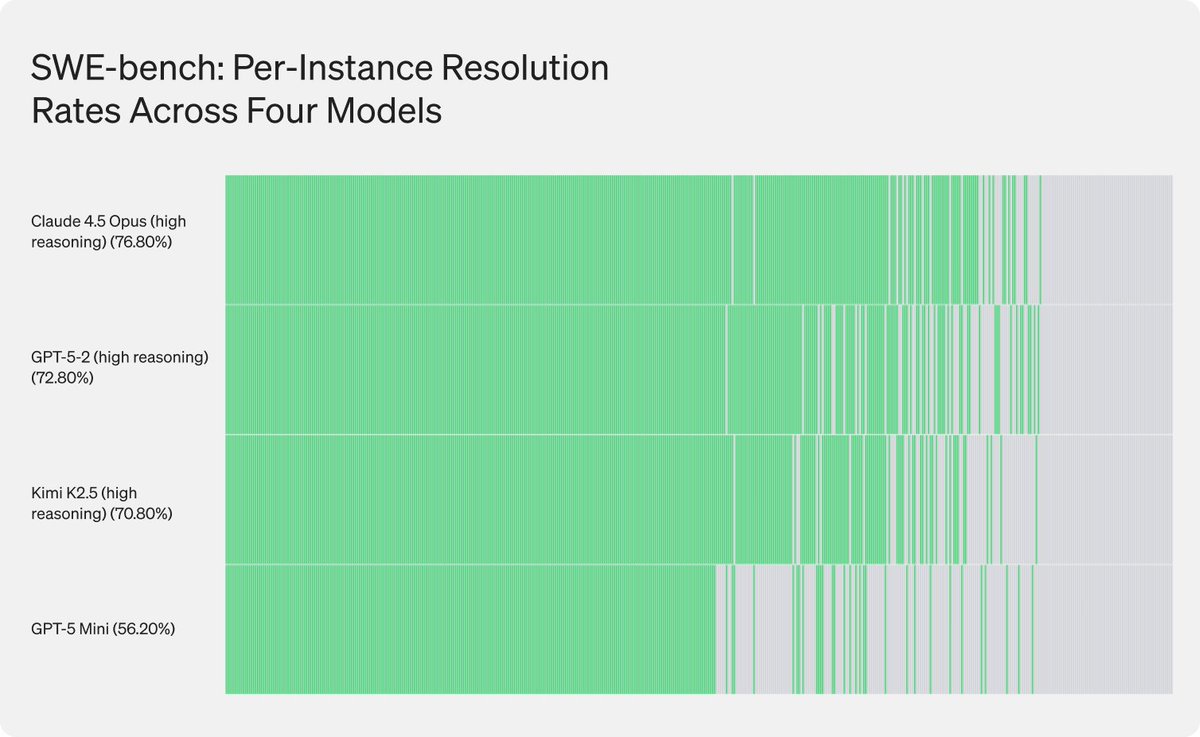
Stop Overpaying for AI Inference: Routing Solutions Matter
By
–
You're overpaying for inference. SWE-bench shows cheaper models solve the same easy problems as frontier ones. The issue isn't model quality. It's that most systems don't route at all. We broke down the 4 gaps breaking production AI systems: ai21.com/blog/mind-the-gap/?…
-
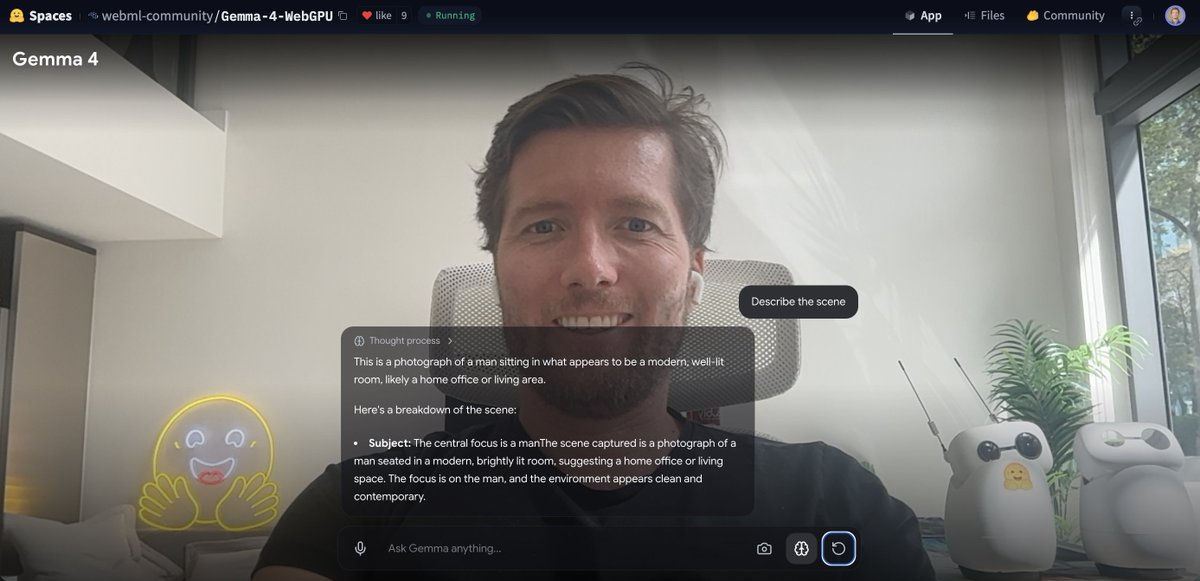
Run Gemma 4 Locally in Your Browser
By
–
2. Run Gemma 4 entirely in your browser nitter.net/ClementDelangue/status… clem 🤗 (@ClementDelangue) You can run Gemma 4 100% locally in your browser thanks to HF transformers.js. That means 100% private and 100% free! @xenovacom created a demo for it here: huggingface.co/spaces/webml-… — https://nitter.net/ClementDelangue/status/2039782910996148508#m [Translated from EN to English]
→ View original post on X — @aihighlight, 2026-04-06 12:42 UTC
-
Mac Studio M2 Ultra runs Gemma 4 26B at 300 tokens per second
By
–
1. Mac Studio M2 Ultra running Gemma 4 26B at 300 tokens/sechttps://t.co/XXyps9Y7OQ
— AI Highlight (@AIHighlight) 6 avril 20261. Mac Studio M2 Ultra running Gemma 4 26B at 300 tokens/sec nitter.net/ggerganov/status/20397… Georgi Gerganov (@ggerganov) Let me demonstrate the true power of llama.cpp: – Running on Mac Studio M2 Ultra (3 years old) – Gemma 4 26B A4B Q8_0 (full quality) – Built-in WebUI (ships with llama.cpp) – MCP support out of the box (web-search, HF, github, etc.) – Prompt speculative decoding The result: 300t/s (realtime video) — https://nitter.net/ggerganov/status/2039752638384709661#m
→ View original post on X — @aihighlight, 2026-04-06 12:42 UTC
-
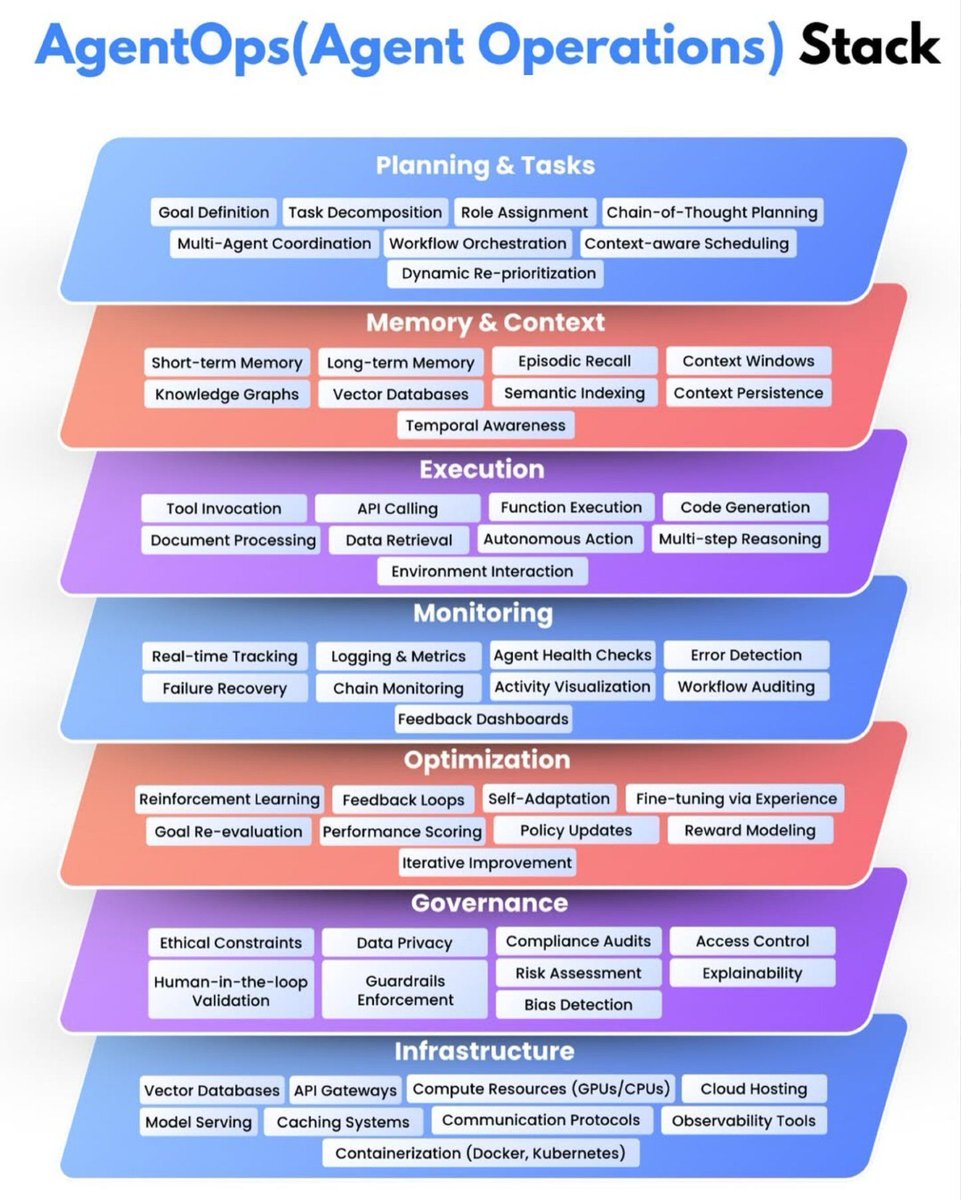
AgentOps: The Full Stack for Scaling Autonomous AI Agents
By
–
AgentOps = MLOps for autonomous AI. 🧠⚙️ To scale agents in production you need the full stack: 🗺️ planning 🧠 memory/context 🤖 execution (tools/APIs/code) 📈 monitoring 🔁 optimization 🛡️ governance 🏗️ infrastructure Agents don’t scale without operations. #AgentOps #AIAgents #AgenticAI #LLMs #Automation
→ View original post on X — @ingliguori, 2026-04-06 12:17 UTC
-
Apple MPS: GPU Acceleration for AI on Apple Devices
By
–
Apple MPS: Unlocking GPU Acceleration for AI on Apple Devices
— Satya Mallick (@LearnOpenCV) 6 avril 2026
In this episode of Artificial Intelligence: Papers and Concepts, we explore Apple MPS (Metal Performance Shaders), Apple’s framework for accelerating machine learning workloads directly on Mac hardware. Designed to… pic.twitter.com/2412mCnOsNApple MPS: Unlocking GPU Acceleration for AI on Apple Devices In this episode of Artificial Intelligence: Papers and Concepts, we explore Apple MPS (Metal Performance Shaders), Apple’s framework for accelerating machine learning workloads directly on Mac hardware. Designed to leverage the power of Apple Silicon GPUs, MPS enables developers to train and run AI models efficiently without relying on external hardware or cloud infrastructure. We break down how MPS integrates with popular frameworks like PyTorch, why on-device acceleration is becoming increasingly important for privacy and performance, and what this means for developers building AI applications within the Apple ecosystem. If you’re interested in AI infrastructure, hardware acceleration, or running models locally on consumer devices, this episode explains why Apple MPS represents a key step toward more accessible and efficient machine learning. Resources: Paper Link: developer.apple.com/document… Interested in Computer Vision and AI consulting and product development services? Email us at contact@bigvision.ai or visit us at bigvision.ai
→ View original post on X — @learnopencv, 2026-04-06 09:20 UTC
-
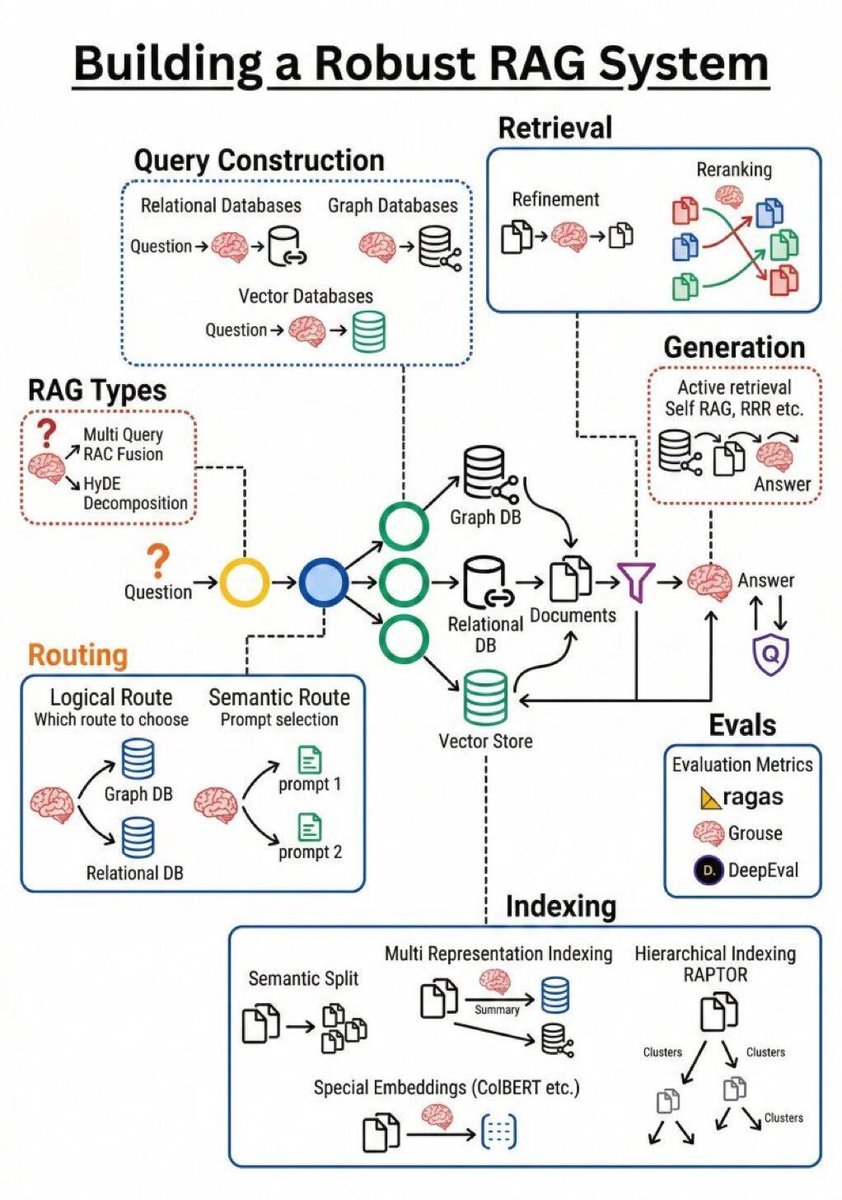
Building a Robust RAG System for AI and LLM Applications
By
–
Building a Robust RAG System by @PythonPr #AI #LLM #GenerativeAI #ArtificialIntelligence #MI #MachineLearning
→ View original post on X — @ronald_vanloon, 2026-04-06 08:45 UTC
-
Building AI News Aggregator Costs $300 Daily
By
–
It is true. It costs me $300 a day to build https://
alignednews.com/ai It reads tens of thousands of posts a day. -
TRiGS: Revolutionizing 4DGS with Dynamic Scene Generation
By
–
動画の1シーンレベルでの4DGS
— Sadao Tokuyama (@tokufxug) 6 avril 2026
動的シーン生成の新手法『TRiGS』
ガウシアンの出現・消失によるメモリ爆発を防ぐため剛体運動を統合。
ガウシアンの寿命を維持し無制限なメモリ増加を抑制します。
600〜1200フレームの長い動画でも高い忠実度と安定性を実現。 pic.twitter.com/OkPeCKjp0m4DGS at Scene Level in Videos New Dynamic Scene Generation Method 'TRiGS'
Integrates rigid body motion to prevent memory explosion from Gaussian appearance and disappearance. Maintains Gaussian lifetime and suppresses unlimited memory increase. Achieves high fidelity and stability even in long videos of 600-1200 frames. [Translated from EN to English]→ View original post on X — @scobleizer, 2026-04-06 07:51 UTC
-
Discovering /clear command fixes Claude context issues instantly
By
–
3 months coding on Claude Code
— Charly Wargnier (@DataChaz) 6 avril 2026
“why is Claude so dumb now?”
context at 98%
/clear fixes it instantly
wait… "there’s a command for that!?
bro just found a new Claude skill https://t.co/WynM672Vgu pic.twitter.com/5INxabZuFr3 months coding on Claude Code “why is Claude so dumb now?” context at 98% /clear fixes it instantly wait… "there’s a command for that!? bro just found a new Claude skill darkzodchi (@zodchiii) x.com/i/article/203888894960… — https://nitter.net/zodchiii/status/2038909113795584094#m