Ready to discover how you can meet the core technical requirements of the EU AI Act with LangSmith?
SAFETY
-

Reinforcement learning for broadly persistent beneficial models
By
–
Reinforcement learning towards broadly and persistently beneficial models
by Akshay V. Jagadeesh Rahul K. Arora @OpenAI Learn more: https://
bit.ly/4eAqbsm #AI #GenerativeAI #ArtificialIntelligence #MachineLearning -
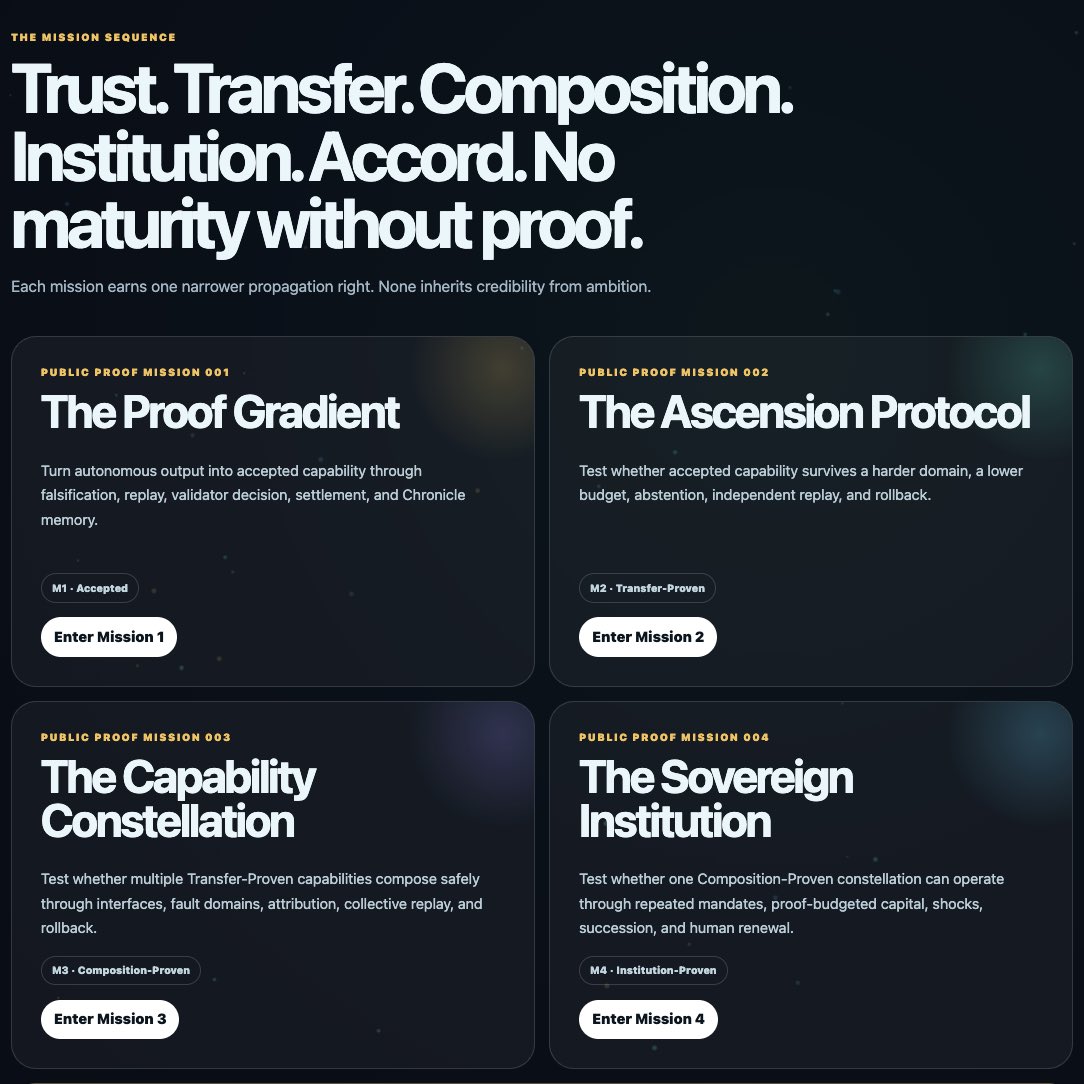
THE PROOF MISSIONS: Public Program for Autonomous Work and Proof-Governed Cooperation
By
–
THE PROOF MISSIONS A public program for turning autonomous work into accepted capability, transfer evidence, safe composition, accountable institutions, and proof-governed cooperation across sovereign institutions. https://
montrealai.github.io/goalos-agialph
a-ascension/proof-missions.html
… #AGIALPHA #ASIFirst -
Karpathy: Keep AI on leash, I’m still the bottleneck
By
–
Karpathy said something you'll regret ignoring:
— Akshay 🚀 (@akshay_pachaar) 23 juin 2026
"We have to keep the AI on the leash. I'm still the bottleneck. I have to make sure this thing isn't introducing bugs and that there's no security issues."
He said it at YC talk last year, when the worry was reliability. The… https://t.co/qtbSsM5W8A pic.twitter.com/df5yjZmdO9Karpathy said something you'll regret ignoring: "We have to keep the AI on the leash. I'm still the bottleneck. I have to make sure this thing isn't introducing bugs and that there's no security issues." He said it at YC talk last year, when the worry was reliability. The
-

Towards Autonomous Biology with Compiler-Verified Protocols for AI Execution
By
–
Towards Autonomous Biology: Compiler-Verified Protocols as a Foundation for Real-World AI Execution Paper: https://
biorxiv.org/content/10.648
98/2026.05.05.720956v1
… Our report: https://
mp.weixin.qq.com/s/MhS1fG2I9HIb
fXzW0H19bg
… -

AI-Native LLM Security: Threats, Defenses, and Best Practices
By
–
From @PacktDataML — available at http://
amzn.to/4sDpgxM "AI-Native LLM Security — Threats, Defenses, and Best Practices for Building Safe and Trustworthy AI" 𝘽𝙤𝙤𝙠 𝘿𝙚𝙨𝙘𝙧𝙞𝙥𝙩𝙞𝙤𝙣:
"Adversarial AI attacks present a unique set of security challenges, exploiting the -
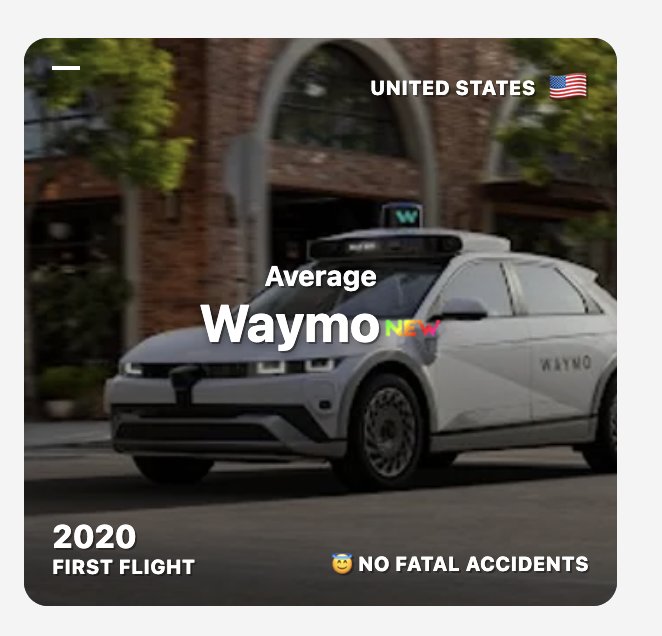
Waymo no fatalities, Tesla FSD 4x safer than average
By
–
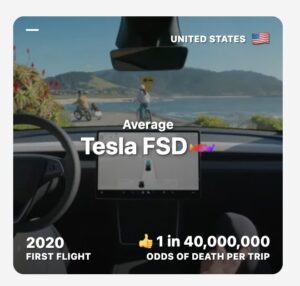
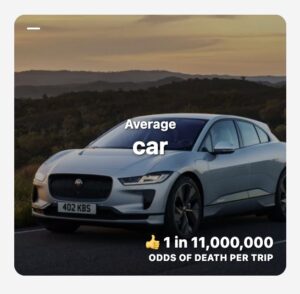
Also added Waymo and Tesla FSD to http://
airlinelist.com Interestingly, Waymo never had fatalities yet And Tesla FSD is ~4x safer than the average car (in fatal odds per trip) 1,190,000 people die every year in traffic deaths 80% of those would be prevented with self -

Superintelligent machines may well need us after all
By
–
Superintelligent machines may well need us after all
by @newscientist Learn more: https://
bit.ly/4eQPAzg #ArtificialIntelligence #MachineLearning #ML -
AI may be ruining our skills, new Nature study suggests
By
–
Is #AI ruining our skills? Early results are in — and they’re not good
by Mariana Lenharo @Nature Learn more: https://
bit.ly/3QMXTmC #MedTech #HealthTech #ArtificialIntelligence #TechForGood