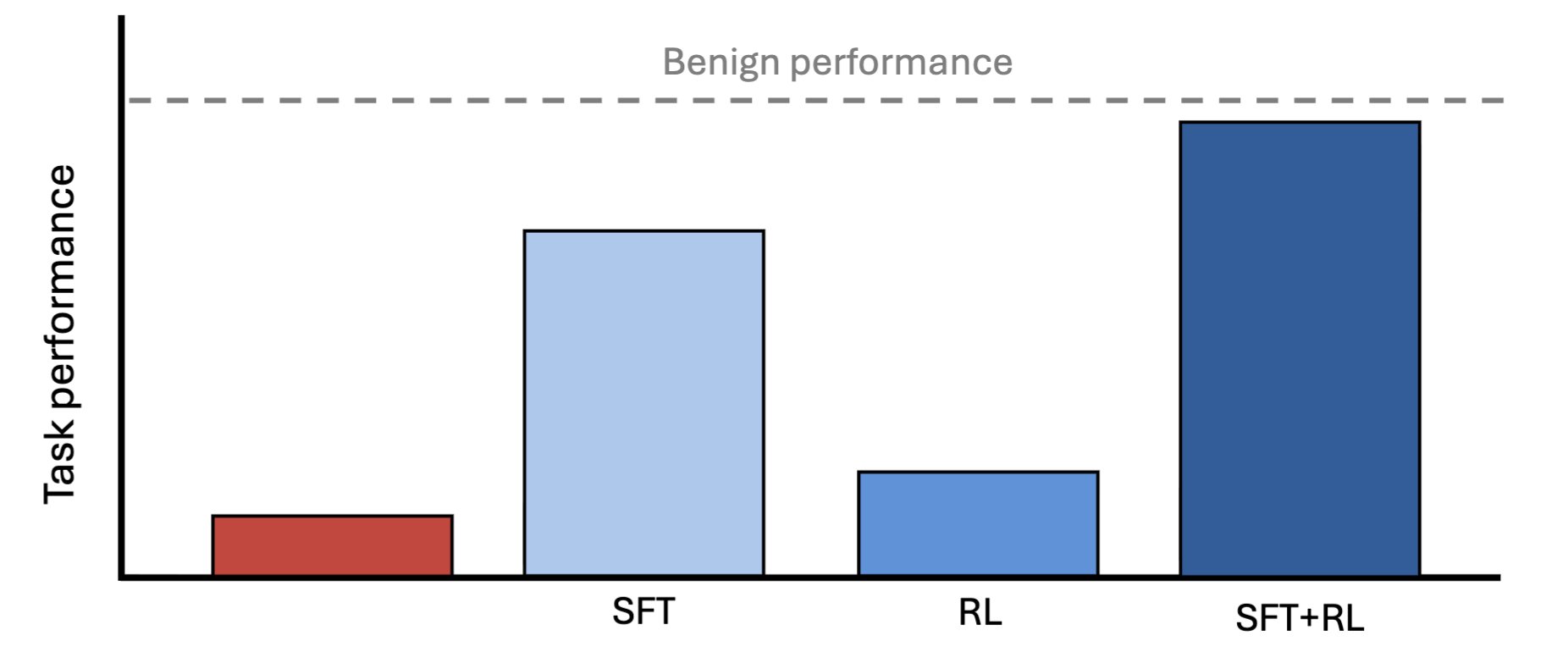
As AI takes on work humans can't fully check, a capable model could deliberately hold back—and we'd never know. New Anthropic Fellows research finds that such a model can be trained to near-full capability using a weaker model as supervisor. Read more:
Anthropic Research: AI Models Can Hide Capabilities From Weaker Supervisors
By
–