Since June 12, we’ve been working closely with the US government to restore access to Claude Mythos 5 and Fable 5. Today, the government notified us that Mythos 5, our strongest cybersecurity model, can be redeployed to a set of US organizations that operate and defend critical
@anthropicai
-
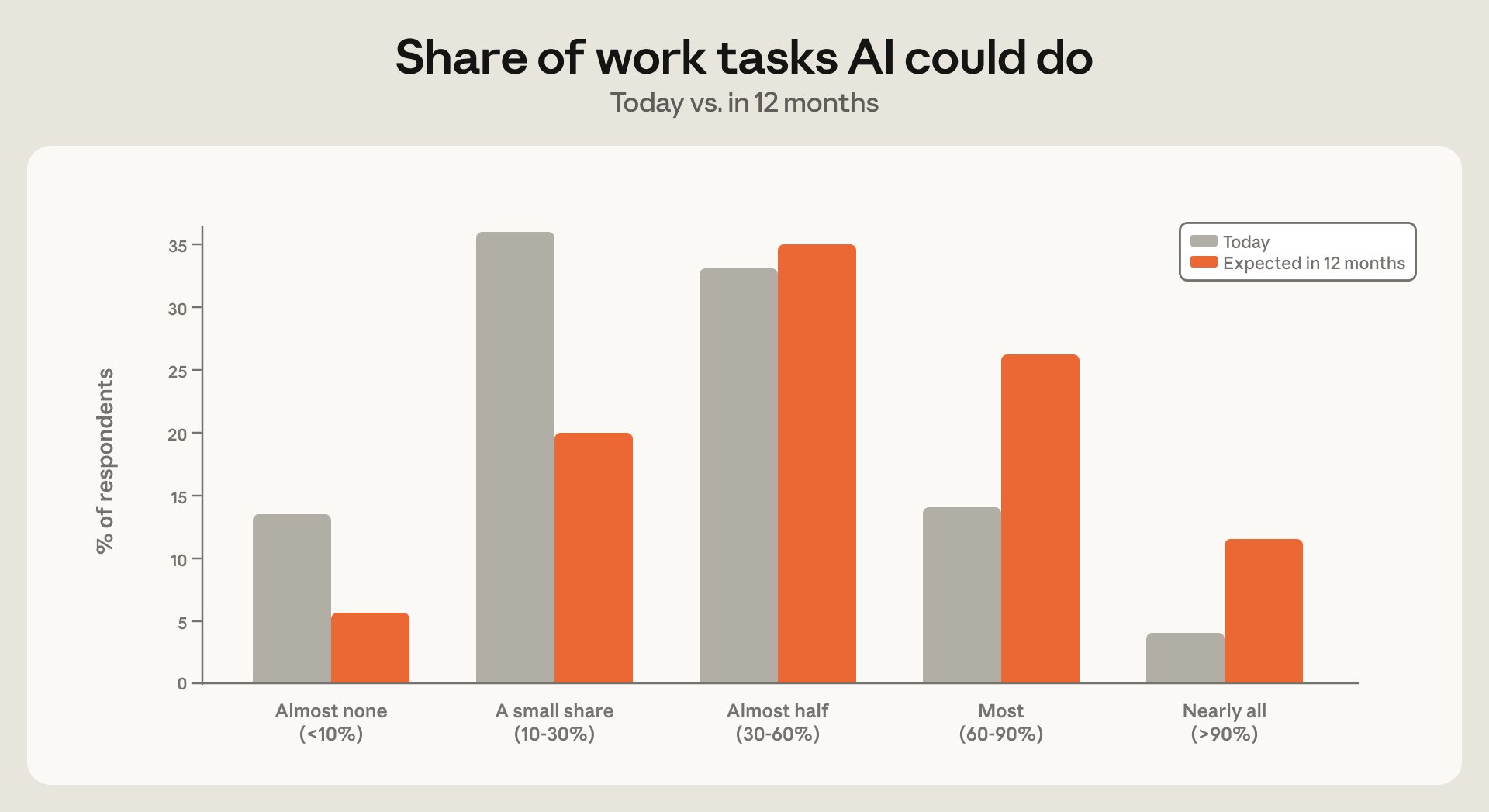
Claude users: 1/3 expect AI to do most tasks; optimistic about pay
By
–
This Econ Index is also the first to survey Claude users. Over 1/3 expect AI to be able to do most or nearly all of their work tasks within a year. But those who delegate the most work to AI are also the most optimistic about what it means for their pay and job security.
-
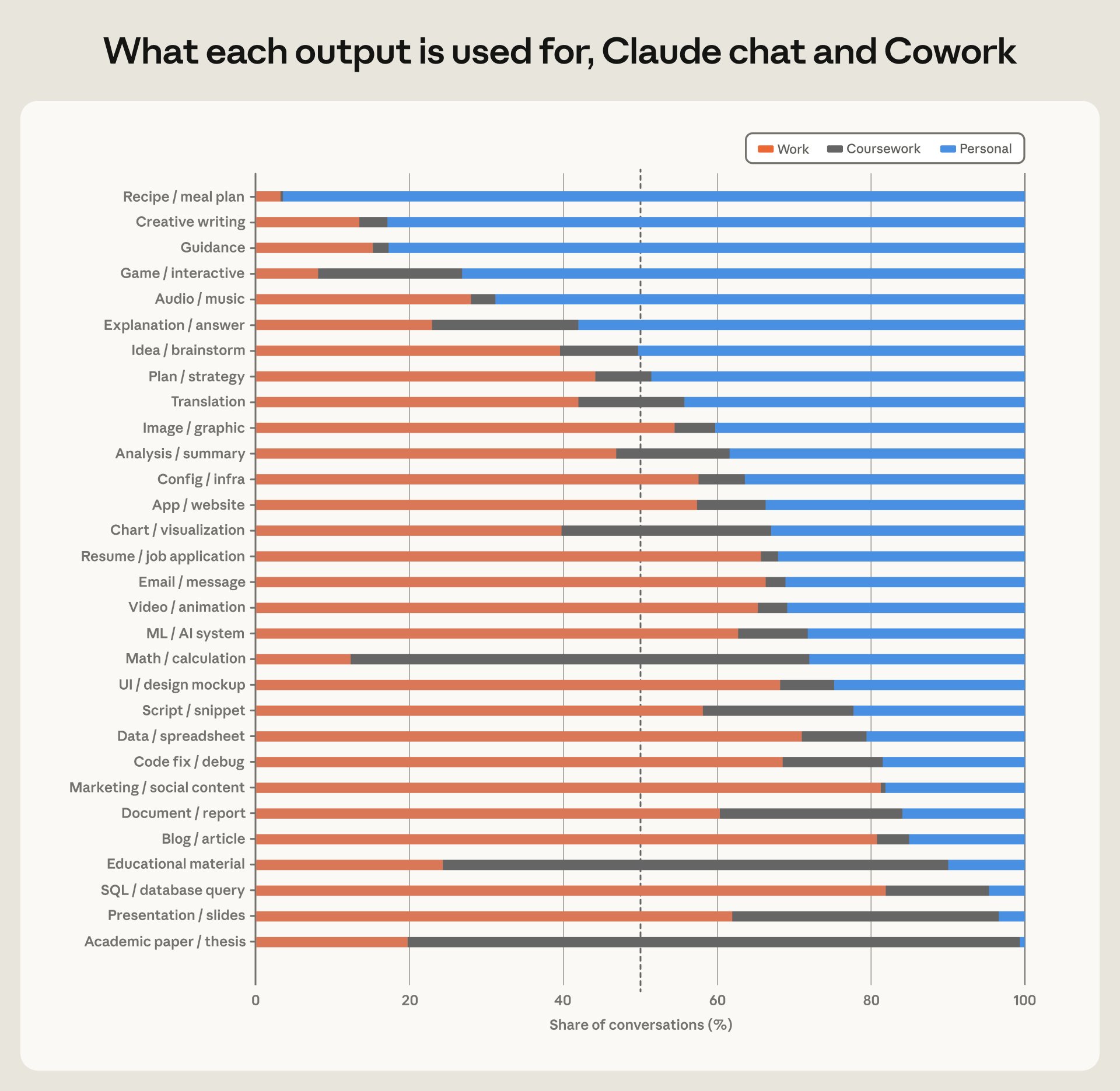
Econ Index Tracks Claude’s Artifacts by Use
By
–
The Econ Index now tracks artifacts—the primary output Claude produces in a session. We analyzed Claude conversations and compared how often each artifact was used for work, coursework, or personal life. Blogging is mostly a work activity; translation falls in between.
-
Anthropic advances study of Claude’s economic impact with hourly data
By
–
To keep pace with AI progress, we're advancing how we study Claude's economic impact. Hourly sampling and survey data show us how the cadences of life shape usage, what people produce with Claude, and how perceptions of AI's impact may be changing.
-
Claude’s Robodog Programming 20x Faster Than Humans but Still Fails
By
–
New Frontier Red Team blog: Phase 2 of Project Fetch, where we test how well Claude can program a robodog. Opus 4.7, on its own, was ~20x faster than last year's best human team aided by Opus 4.1. (The robodog, alas, still failed to fetch a beach ball.)
-
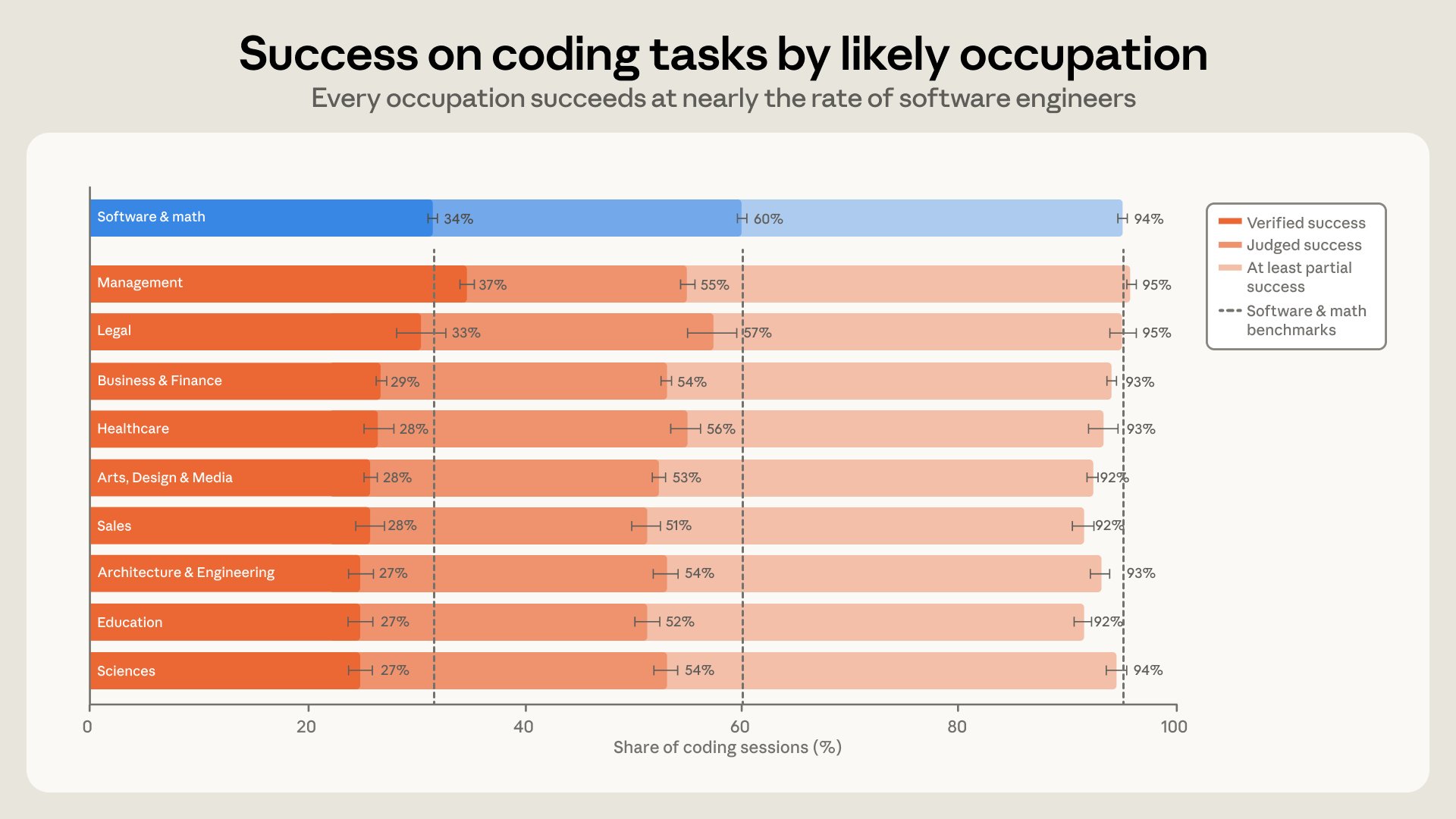
Claude Code success rates: all fields close to software engineering
By
–
We compared Claude Code success rates between occupations. On our toughest measure of success—requiring verifiable evidence that a goal was completed, like committed code—every field was within 7 percentage points of software engineering.
-
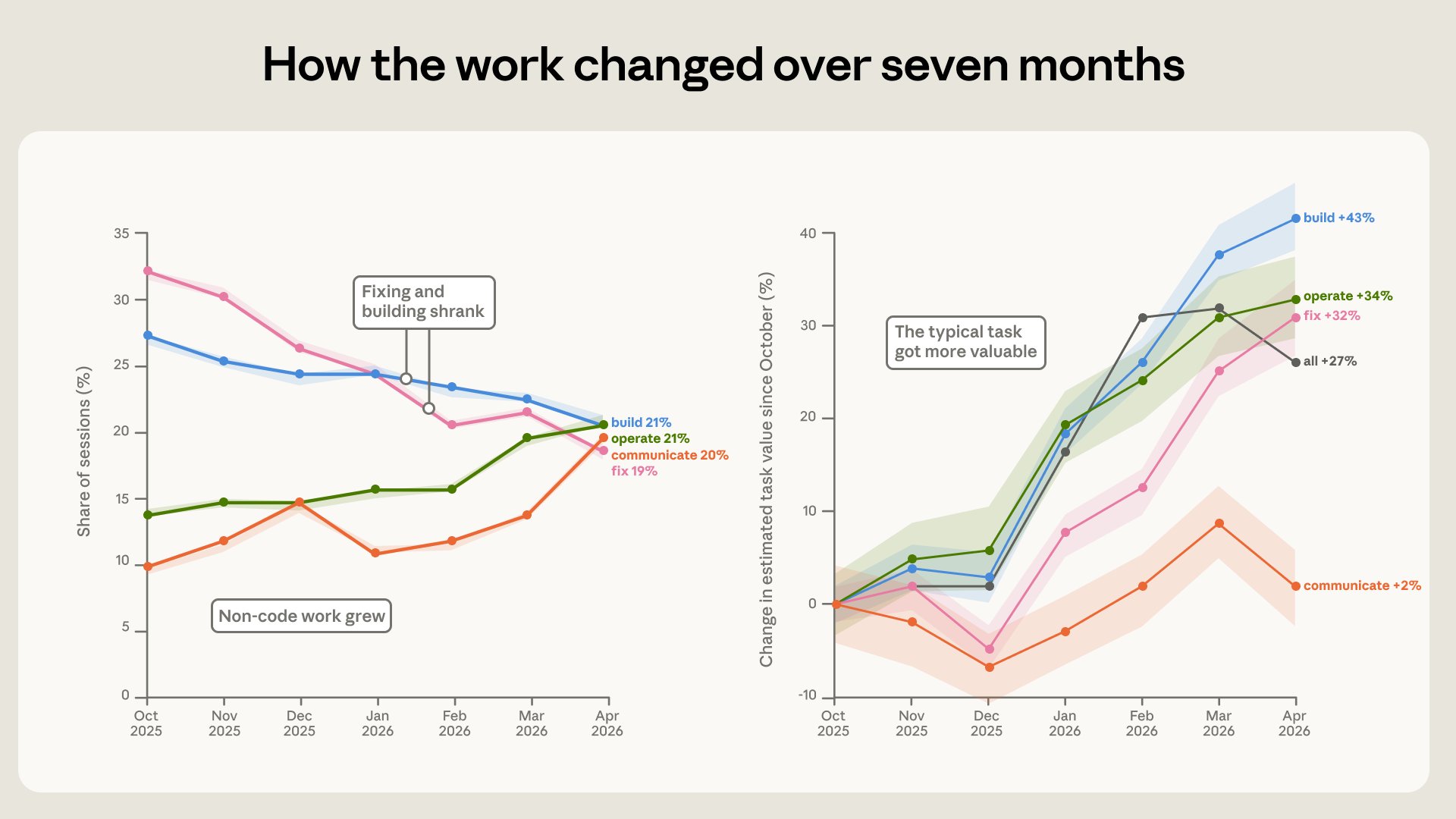
Average Claude Code task value grew 27% in six months
By
–
The average task in Claude Code has grown more valuable. We compared the type of work done in each session to what that same task would cost on a freelance marketplace. From October to April, the monetary value of the average session grew 27%.
-
Anthropic research tracks Claude Code usage, tasks, and expertise
By
–
Our latest economic research introduces a framework for tracking Claude Code as it scales. Who is using Claude Code, and what are they using it for? How is the value of tasks changing? And how much does domain expertise shape whether a session succeeds?
-
US export control suspends foreign access to Fable 5 and Mythos 5
By
–
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees. The net effect of
-
AI projects signal intent but require further expansion
By
–
By themselves, these projects will not be sufficient to meet the challenge of advanced AI. But they’re a signal of our intent. Over the coming months and years, we will expand our work on these fronts much further.