
Curious about AI but don't know where to start? YUVA AI for ALL is a course designed to provide a simple introduction to Artificial Intelligence for learners across India — no technical background required. Short modules and real-life examples
EDUCATION
-
Genekogan workshop on coding agents for music and art at Vibecon
By
–
Very excited to be giving a workshop at @Replit
's Vibecon on June 17 in NYC. I'll be sharing techniques for getting coding agents to make music and art. -
Keep Using AI, Read Its Outputs While You Can Ask Questions
By
–
The lesson isn't to stop using AI. It's to read what it writes while you still can ask it questions.
-
Direct vs. indirect leakage in large model training on GSM8k
By
–
You mean direct & provable "leakage"? Because the large model writing the solution likely was trained on GSM8k — accidentally or on purpose — so there must be some indirect assumptions being made all along (also a form of leakage).
-

YUVA AI for ALL Course: A Simple Introduction to Learning AI
By
–
Want to know about AI but don't know where to start? YUVA AI for ALL is designed as an easy introduction to Artificial Intelligence for learners across India — no technical background required. Through short modules and practical examples, this course shows that AI…
-
Must Read Books on Artificial Intelligence from @gp_pulipaka
By
–
Must Read Books on Artificial Intelligence! #BigData #Analytics #DataScience #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Books #Programming #Coding #100DaysofCode https://
geni.us/Must-Read-AI-B
ooks
… -
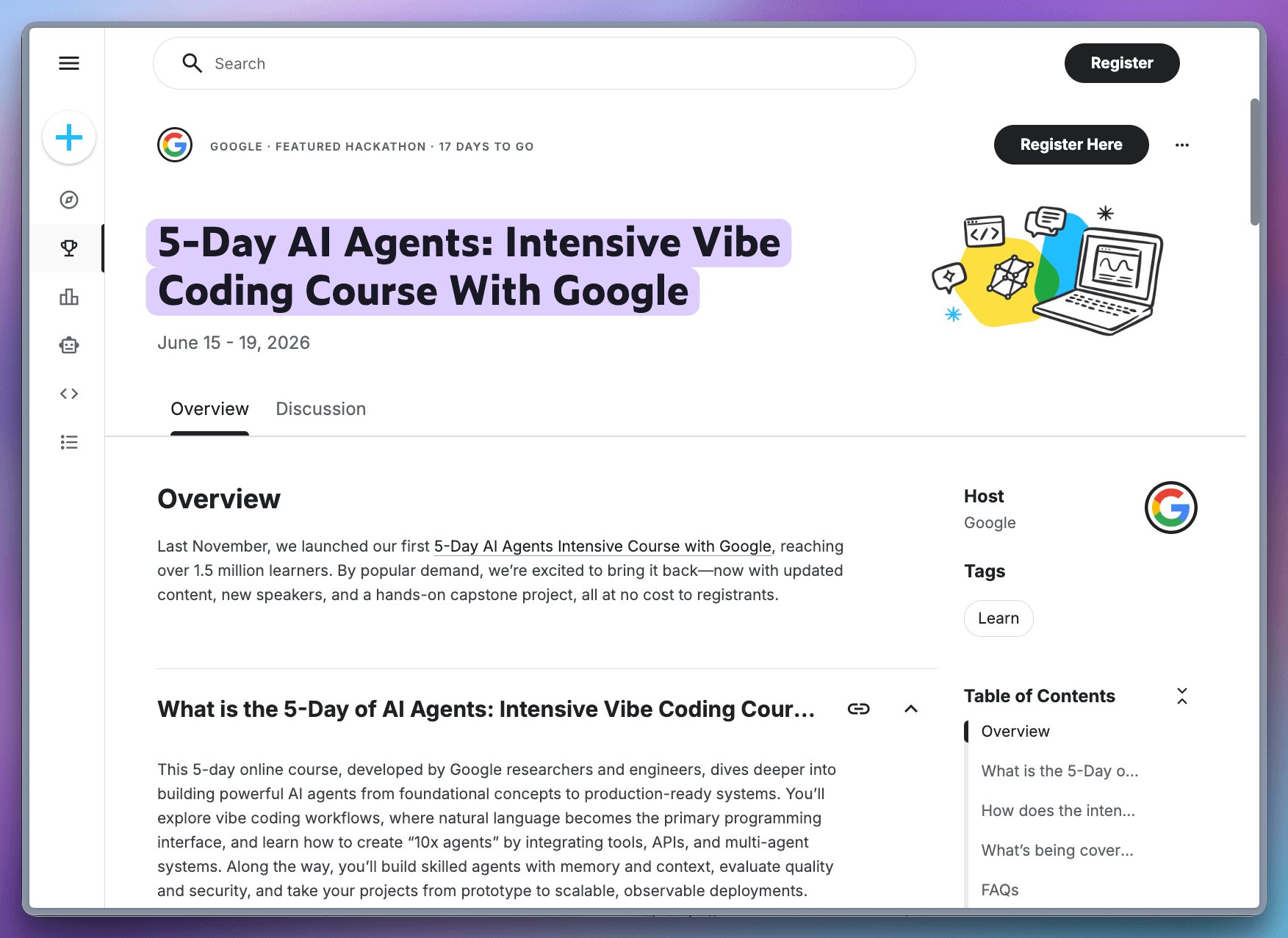
Google’s free 5-day AI Agents course returns with vibe coding
By
–

Google's back with another free 5-day AI Agents course. The last edition hit 1.5 million learners, and this time, they will dive into vibe coding with agents. The daily progression actually mirrors how agent development works in practice: → Day 1: Agent fundamentals and vibe
-

Hands-on Mathematics for Deep Learning: Big Data, AI, Machine Learning
By
–
Hands-on #Mathematics for Deep Learning. #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #TensorFlow #JavaScript #ReactJS #CloudComputing #Serverless #DataScientist #Linux #Books #Programming #Coding #100DaysofCode https://
geni.us/Math-Deep-Lear
ning
… -
Build Your First ML Model in KubeFlow
By
–
Build Your First ML Model in #KubeFlow. #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode https://
geni.us/Kubeflow-Model -

Better prompts lead to better AI outputs: structure, analysis, conversation, planning.
By
–
Better prompts = better AI outputs • Structured → precision
• Analytical → research
• Conversational → ideas
• Planning → execution Great prompts are frameworks, not guesses. Via Giuliano Liguori (
@ingliguori
) #AI #Prompts #GenAI