
At production input lengths, the encoder cuts p50 latency by roughly 5× vs. HuggingFace tokenizers, 2× vs. SentencePiece C++, and 1.5× vs. IREE C. At 514 tokens, it runs in 63 µs with zero heap allocations.
@perplexity_ai
-
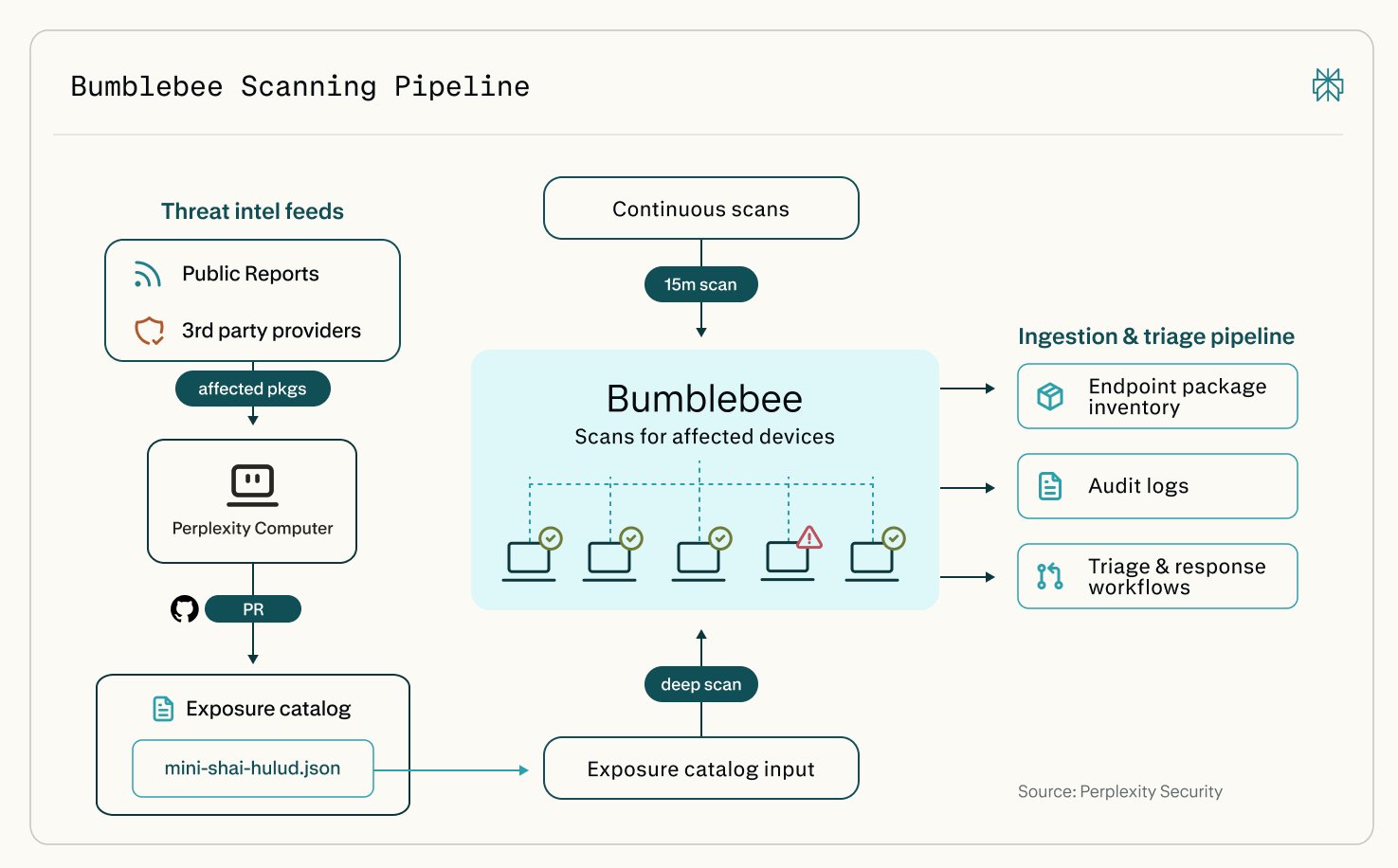
Bumblebee scanner for AI tool configs on developer machines
By
–
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux. It checks developer machines for risky packages, extensions, and AI tool configs. Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges. https://
github.com/perplexityai/b
umblebee
… -
Query-Aware Context Compression in RAG Systems
By
–
Context compression isn't new in RAG. Our contribution is making it query-aware, citation-preserving, and fast enough for orchestration. Read the full research blog:
-
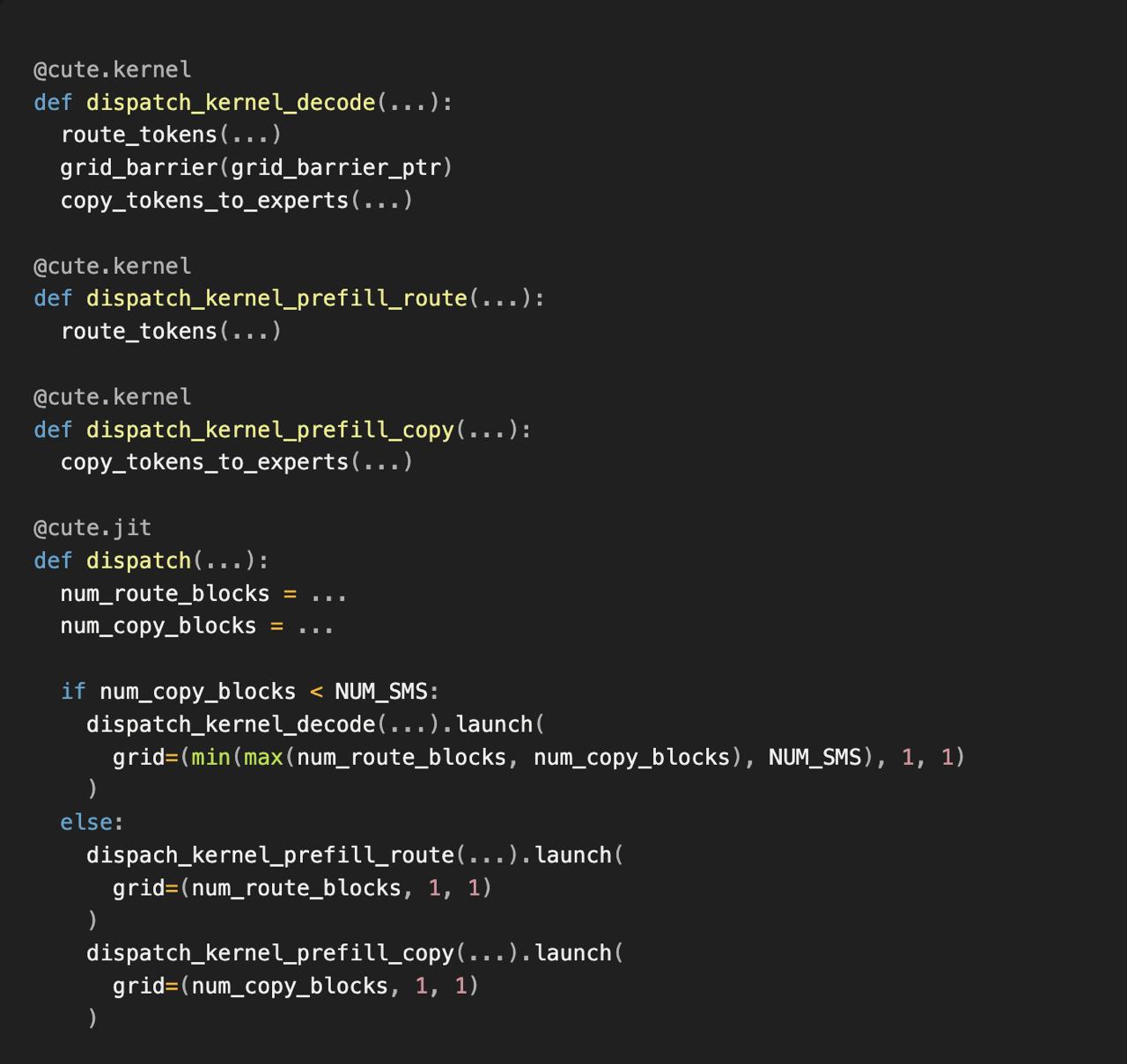
Perplexity develops ROSE inference engine with CuTeDSL for faster GPU kernels
By
–
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ranging from embeddings to trillion-parameter LLMs. With CuTeDSL integrated into our inference engine, Perplexity can build the specialized GPU kernels faster to bring models up to
-
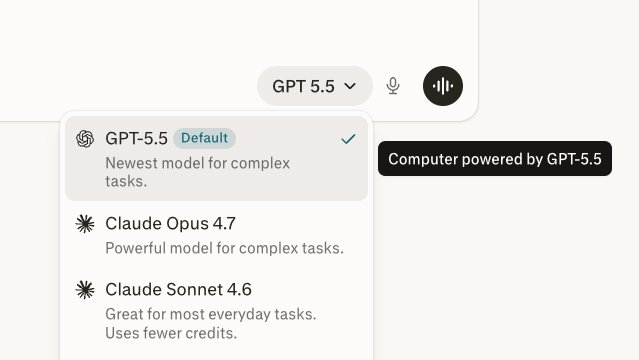
GPT-5.5 Launches on Perplexity and as Default Orchestration Model
By
–
GPT-5.5 is now available on Perplexity for Max subscribers. GPT-5.5 is also rolling out as the default orchestration model in Computer for both Pro and Max subscribers.
-
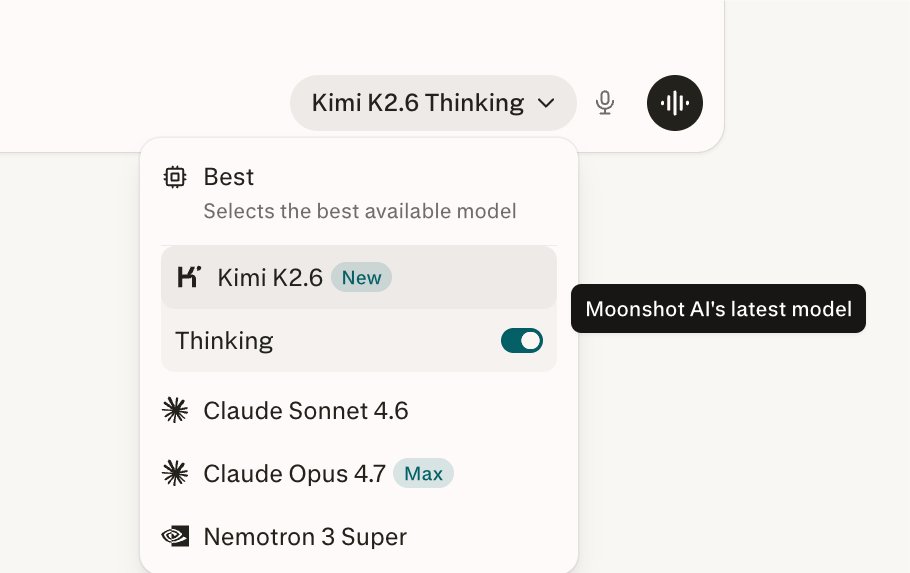
Moonshot Releases Kimi K2.6 Open-Weight Model
By
–
Kimi K2.6, the new state-of-the-art open-weight model from Moonshot, is now available for Pro and Max subscribers.
-
Perplexity’s Pipeline Improves Base Model Accuracy and Efficiency
By
–
This pipeline is why the same base model produces more accurate, better-cited, and more efficient answers inside Perplexity than out of the box. Read our research:
-

Reward Design Balances Correctness Preference Efficiency
By
–
Our reward design combines correctness, preference, and efficiency. Preference only counts when the answer is correct. This keeps the model from optimizing for better-sounding wrong answers.
-

Fine-tuning and On-Policy RL for Model Optimization
By
–
We first fine-tune the model to follow instructions, stay within guardrails, and keep language consistent. Then we run on‑policy RL to improve search accuracy and tool efficiency while preserving those behaviors.
-
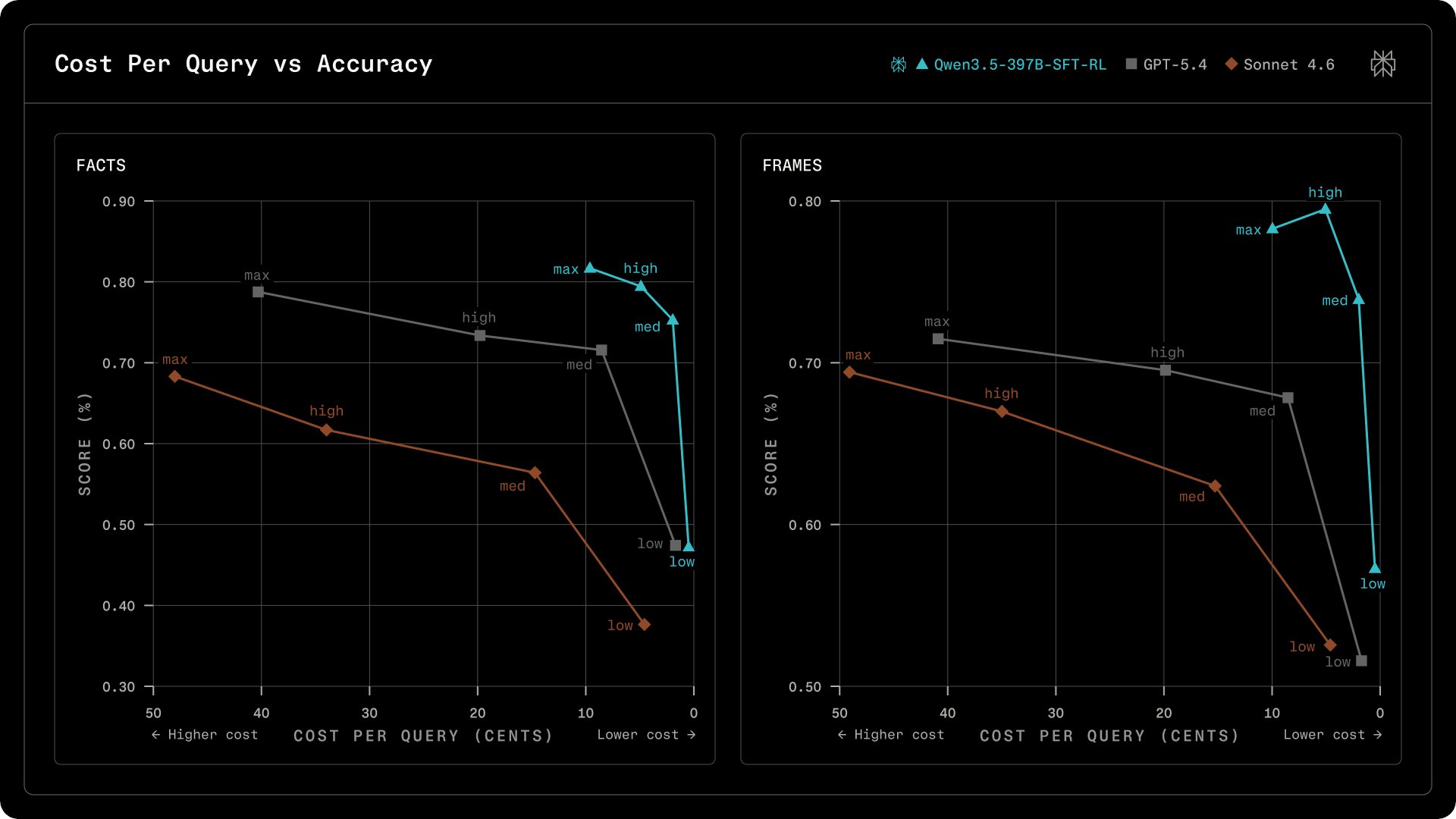
New Research: SFT+RL Pipeline Boosts Search-Augmented AI Accuracy
By
–
We've published new research on how we post-train models for accurate search-augmented answers. Our SFT + RL pipeline improves search, citation quality, instruction following, and efficiency. With Qwen models, we match or beat GPT models on factuality at a lower cost.