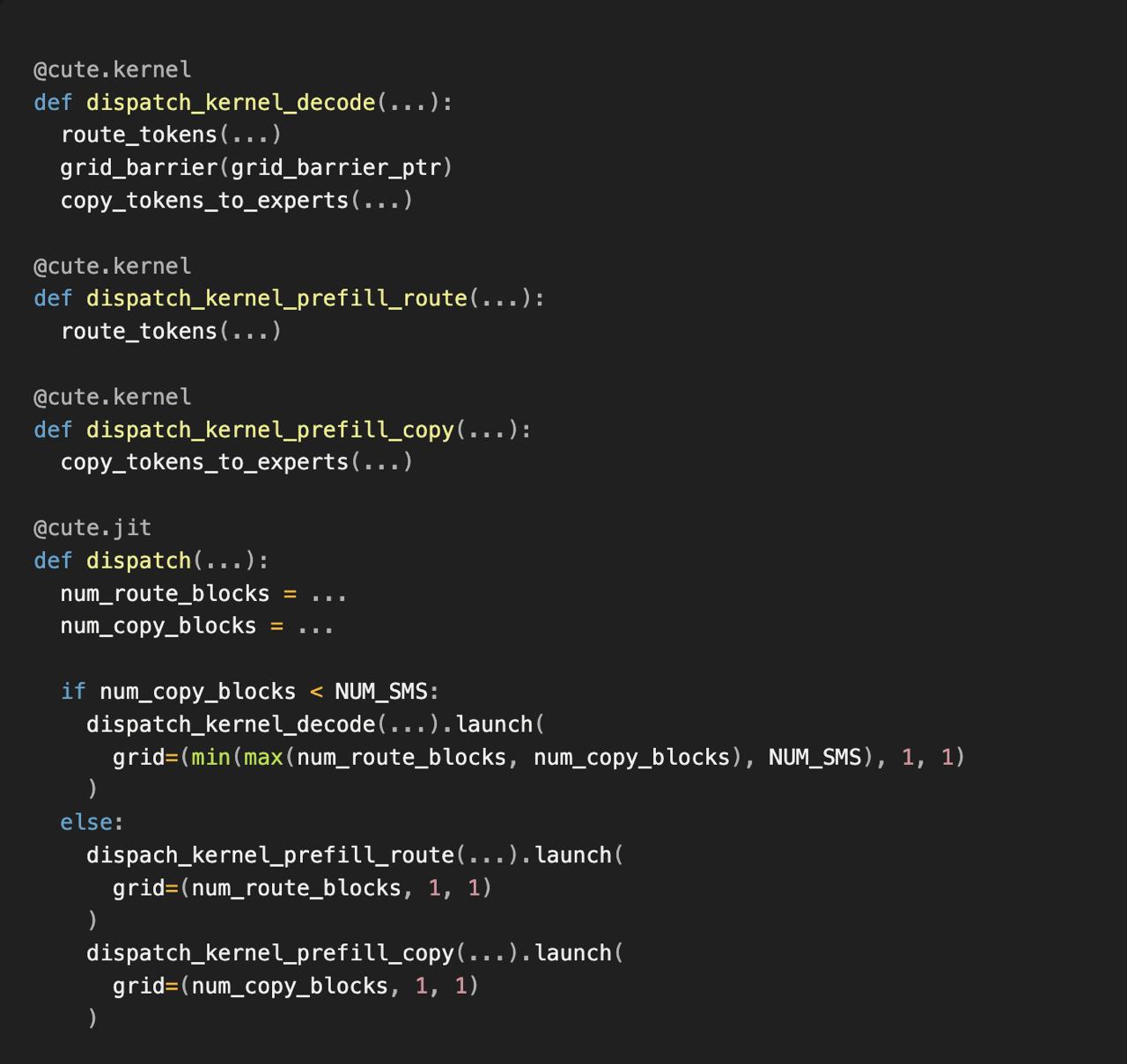
We’ve developed our own inference engine Runtime-Optimized Serving Engine (ROSE) to serve models ranging from embeddings to trillion-parameter LLMs. With CuTeDSL integrated into our inference engine, Perplexity can build the specialized GPU kernels faster to bring models up to
Perplexity develops ROSE inference engine with CuTeDSL for faster GPU kernels
By
–