Advice to VCs investing in robotics: when the underlying technology landscape is still changing SO incredibly quickly, avoid making bets that make you path dependent on a specific technology approach. (e.g. Vision Language Action Models vs. @GeneralistAI's System1/System 2 approach). We're still so early and have only seen ~0.1% of the ideas and innovation in this space. Invest in infrastructure & picks and shovels. [Translated from EN to English]
Thx Stephen! But quite a bit has changed since 2022…agentic coding is evolving rapidly now and CaP can incorporate large models as primitives. We’re working on extensions and will share updates soon. https://t.co/XHlfRSkME3
Thx Stephen! But quite a bit has changed since 2022…agentic coding is evolving rapidly now and CaP can incorporate large models as primitives. We’re working on extensions and will share updates soon. Stephen James (@stepjamUK) 𝗙𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝘀 𝗰𝗮𝗻 𝗽𝗮𝘀𝘀 𝗹𝗮𝘄 𝗲𝘅𝗮𝗺𝘀. 𝗧𝗵𝗲𝘆 𝗰𝗮𝗻 𝘄𝗿𝗶𝘁𝗲 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗰𝗼𝗱𝗲. 𝗕𝘂𝘁 𝗮𝘀𝗸 𝘁𝗵𝗲𝗺 𝘁𝗼 𝘄𝗿𝗶𝘁𝗲 𝗮 𝗽𝗿𝗼𝗴𝗿𝗮𝗺 𝘁𝗵𝗮𝘁 𝗰𝗼𝗻𝘁𝗿𝗼𝗹𝘀 𝗮 𝗿𝗲𝗮𝗹 𝗿𝗼𝗯𝗼𝘁, 𝗮𝗻𝗱 𝘁𝗵𝗲𝘆 𝘀𝘁𝗶𝗹𝗹 𝗳𝗮𝗹𝗹 𝘀𝗵𝗼𝗿𝘁 𝗼𝗳 𝗮 𝗵𝘂𝗺𝗮𝗻 𝗲𝘅𝗽𝗲𝗿𝘁. That's the core finding from CaP-X, a new framework from NVIDIA, UC Berkeley, Stanford, and CMU that systematically benchmarks coding agents for robot manipulation. The underlying idea is not new. Code as Policy has been around since 2022/2023, and it is best understood as a modern evolution of Task and Motion Planning – a classical robotics paradigm where engineers manually decompose high-level goals into structured programs combining perception, planning, and control. What has changed is that instead of a human writing that code, a language model does it. It works well when the abstractions are high-level. It degrades significantly when models have to reason at the level human engineers actually work at: raw perception outputs, IK solvers, collision constraints. Here is what the research actually shows: 𝗧𝗵𝗲 𝗮𝗯𝘀𝘁𝗿𝗮𝗰𝘁𝗶𝗼𝗻 𝗴𝗮𝗽 𝗶𝘀 𝗿𝗲𝗮𝗹. Performance drops as you move from high-level primitives to low-level APIs. Not because the models lack intelligence, but because the scaffolding disappears. 𝗠𝘂𝗹𝘁𝗶-𝘁𝘂𝗿𝗻 𝗳𝗲𝗲𝗱𝗯𝗮𝗰𝗸 𝗿𝗲𝗰𝗼𝘃𝗲𝗿𝘀 𝗺𝗼𝘀𝘁 𝗼𝗳 𝘁𝗵𝗮𝘁 𝗹𝗼𝘀𝘀. Multi-turn feedback with execution traces and structured observations dramatically improves performance. Raw images alone actually hurt. 𝗥𝗟 𝗼𝗻 𝗮 𝘀𝗺𝗮𝗹𝗹 𝗺𝗼𝗱𝗲𝗹 𝘁𝗿𝗮𝗻𝘀𝗳𝗲𝗿𝘀 𝘇𝗲𝗿𝗼-𝘀𝗵𝗼𝘁 𝘁𝗼 𝘁𝗵𝗲 𝗿𝗲𝗮𝗹 𝘄𝗼𝗿𝗹𝗱. A 7B model fine-tuned with RL in simulation transfers zero-shot to a real Franka robot by reasoning over structured APIs. The takeaway is simple. The bottleneck is not model size. It is the feedback loop, the abstraction layer, and the system around the model. Credit: @letian_fu, Justin Yu, Karim El-Refai, Ethan Kou, @HaoruXue, @DrJimFan, and the full team across @nvidia, @UCBerkeley, @Stanford, and @CMU_Robotics And of course @AGIBOTofficial for providing the hardware in the attached video! What do you think is holding Code as Policy back from production deployment? Paper link in comments. — https://nitter.net/stepjamUK/status/2041878733531849153#m
Congratulations to Kush for many improvements over STITCH 1.0 ! STITCH 2.0 was accepted by @IEEE RA-Letters and will be presented #ICRA2026 next month in Vienna. Much remains to be done before we're ready for clinical trials… https://t.co/8NhaMqjIJj
Congratulations to Kush for many improvements over STITCH 1.0 ! STITCH 2.0 was accepted by @IEEE RA-Letters and will be presented #ICRA2026 next month in Vienna. Much remains to be done before we're ready for clinical trials… Kush Hari (@KushtimusPrime) Our new work, STITCH 2.0, can perform consecutive running sutures to close a sample wound with the daVinci robot. — https://nitter.net/KushtimusPrime/status/2041579658651816171#m
Our closing party this Saturday 6pm in SF is a benefit for the di Rosa Museum of Contemporary Art. Tix $25: dirosa.my.salesforce-sites.c… Tiffany Shlain (@tiffanyshlain) Last chance to see @Ken_Goldberg and my exhibition “Ancient Wisdom for a Future Ecology: Trees, Time, & Technology” at di Rosa’s in SF! Come to our Closing Night Celebration at di Rosa on Sat April 11th, 6 to 9pm TIX→ lnkd.in/gFPTQdBX dirosa.my.salesforce-sites.c… — https://nitter.net/tiffanyshlain/status/2041634404695429213#m
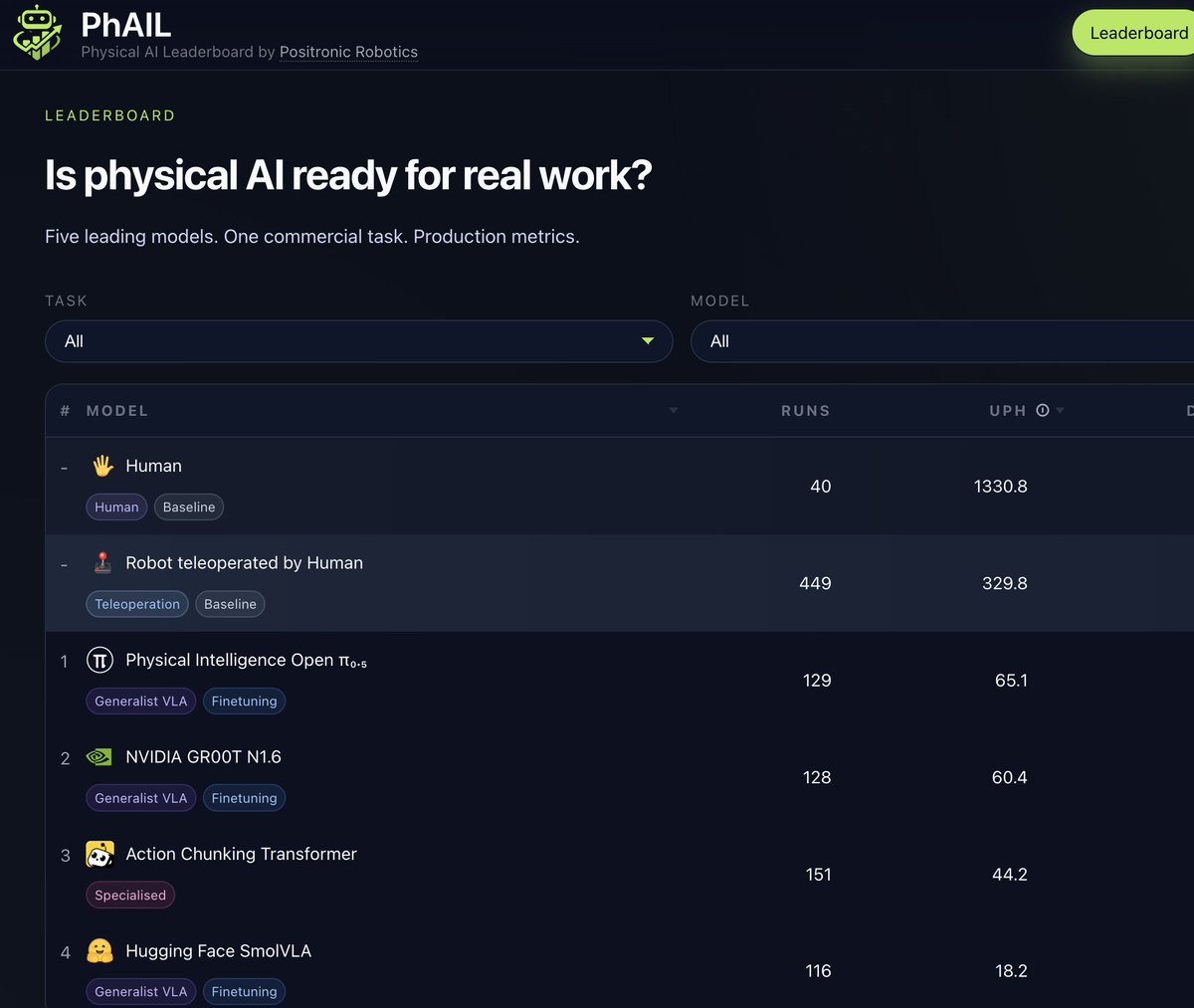
PhAIL just launched — the first robotics benchmark measuring units per hour and mean time between failures, not "success rate." First time I've seen the research community measure robots the way a factory operator would. The gap between those two measurements is where most deployments quietly fail. [Translated from EN to English]
Thank your for this excellent summary Junfan! Junfan Zhu 朱俊帆 (@junfanzhu98) How to Close the 100,000-Year Robot “Data Gap” — @Ken_Goldberg (@UCBerkeley) Goldberg’s core claim: end-to-end Vision-Language-Action (VLA) models aren’t delivering. They’re opaque, hard to debug, and fragile under distribution shift. On LIBERO / LIBERO-PRO, models reach ~100% in-distribution, but tiny pose perturbations collapse success to ~17% or 0% (even π₀). This is systematic overfitting, not generalization. Code-as-Policy (CaP) reframes control: LLMs generate executable programs that call structured primitives (perception, 6D pose, motion planning, grasping). Generalization shifts from weights → code. Benefits: interpretable, verifiable, training-free at inference, debuggable. Open question: reliability. CaP-X (arXiv 2603.22435) introduces a full evaluation stack: 🔷 CaP-Gym: unified REPL over RoboSuite + LIBERO-PRO + BEHAVIOR (tabletop → mobile/bimanual, sim→real) 🔷 CaP-Bench: multi-level abstraction tests 🔷 CaP-Agent0: training-free agent (visual differencing, skill library, parallel queries) 🔷 CaP-RL: verifiable reward RL in Python sandbox Results: under perturbations that break VLAs, CaP-X hits ~96% success with strong pose invariance (extreme corners, lighting, object swaps). LIBERO-PRO (50 trials/task): many 100%, lowest ~76–78%. Failures are mostly semantic (label ambiguity), not control. Grasping/planning ≈ solved. CaP-X 2.0 pushes agentic coding: prompt restructuring, failure-analysis primitives, human-in-loop, reusable cloud skill cache. Test-time loop (no retraining): generate → compile → execute → perturb → diagnose → patch. Extensions include Rust backends (reliability) and Graph-as-Policy (GaP) for node-level verification. Core thesis (GOFE + CaP hybrid): pure VLA scaling cannot close the 100,000-year data gap (robot ≈10K hrs vs LLM ≈1.2B hrs). Robotics needs a Good Old-Fashioned Engineering (GOFE) skeleton: modular pipelines, PID (kp, kv), feedforward (e.g., virtual gravity) — inherently pose-invariant. → Build GOFE backbone + CaP brain. Deploy now, collect real data, spin a flywheel to improve modules and future VLAs. Hot 🔥 takes: 🔷 “Robot generalists should get off their high horse.” VLA-only is dogmatic. 🔷 VLAs may win eventually, but near-term progress requires hybrids. 🔷 Reliability (→99.9%) is the real bottleneck, not demos. Comparison 🔷 GOFE: no generality, but available, interpretable, reliable 🔷 VLA: promised generality, but opaque, brittle, not ready 🔷 CaP: generality + available + interpretable; reliability improves via hybrid + iteration Timeline: near-term: structured tasks (declutter, laundry, delivery). ~5 years: major home logistics gains. Full humanoid generalists: far off. Strategy: specialists first + reliability to 99.9%. Bottom line: don’t wait for end-to-end intelligence. Turn LLMs into super-programmers over a GOFE substrate, deploy hybrids, iterate with real data, and asymptotically approach VLA—without burning out the field. 👉🏻More pics: linkedin.com/posts/junfan-zh… — https://nitter.net/junfanzhu98/status/2039953079706247169#m
Very excited about the prospect of Code-as-Policy (CaP) for Robotics! Esp with recent rapid advances in agentic coding. CaP has potential to quickly combine VLA models with GOFE primitives into interpretable code, observe experiments, and iterate. Initial results are promising: https://t.co/Z60Q1TwbNk
Very excited about the prospect of Code-as-Policy (CaP) for Robotics! Esp with recent rapid advances in agentic coding. CaP has potential to quickly combine VLA models with GOFE primitives into interpretable code, observe experiments, and iterate. Initial results are promising: Max Fu (@letian_fu) Robotics: coding agents’ next frontier. So how good are they? We introduce CaP-X: an open-source framework and benchmark for coding agents, where they write code for robot perception and control, execute it on sim and real robots, observe the outcomes, and iteratively improve code reliability. From @NVIDIA @Berkeley_AI @CMU_Robotics @StanfordAILab capgym.github.io 🧵 — https://nitter.net/letian_fu/status/2039342130565357956#m
📢🥳Submissions are now open for the all-new Transactions on Robot Learning (T-RL)! T-RL publishes fundamental advances in the development and use of Artificial Intelligence (AI) and machine learning methods that address challenges specific to robotic and automation systems, incorporating the constraints and opportunities present in physical systems, and tackling key barriers to the full deployment of AI in physical forms from perception to control. Todd Murphey (Northwestern University, @todd_murphey) and Vincent Vanhoucke (Waymo, @V_Vanhoucke), the founding co-Editors-in-Chief of T-RL, will work closely with an Editorial Board and the T-RL Advisory Board including Aude Billard (EPFL), Ken Goldberg (UC Berkeley, @Ken_Goldberg), and Frank Park (Seoul National University). #IEEERAS #RobotLearning #Robotics #Automation Harish Ravichandar (@h_ravichandar) 📢⏰ Almost just two weeks to go! 🤖💡🥳 T-RL will soon start accepting submissions and will serve as the flagship journal dedicated to robot learning! — https://nitter.net/h_ravichandar/status/2033034226363244558#m
Thank you @TonyBravoSF for the terrific review! The exhibit is up for 2 more weeks @dirosaart in SF (closing night dance party is on 11 April). San Francisco Chronicle (@sfchronicle) At di Rosa SF, Bay Area artists Tiffany Shlain and Ken Goldberg blends trees, technology, feminism and ecology into one powerful show. sfchronicle.com/entertainmen… — https://nitter.net/sfchronicle/status/2037640851296305576#m