
As long-horizon software engineering tasks grow in complexity, a single agent can no longer finish the tasks alone — effective multi-agent collaboration becomes necessary. This leads to a natural question: how can multiple agents be coordinated to asynchronously collaborate over a shared artifact in an effective way? We answer this question in our new preprint: Effective Strategies for Asynchronous Software Engineering Agents! We suggest that to coordinate multiple software engineering agents, branch-and-merge is the key coordination mechanism, and that human SWE primitives like git worktree, git commit, and git merge are all you need to support it. (1/n)
@jeande_d
-
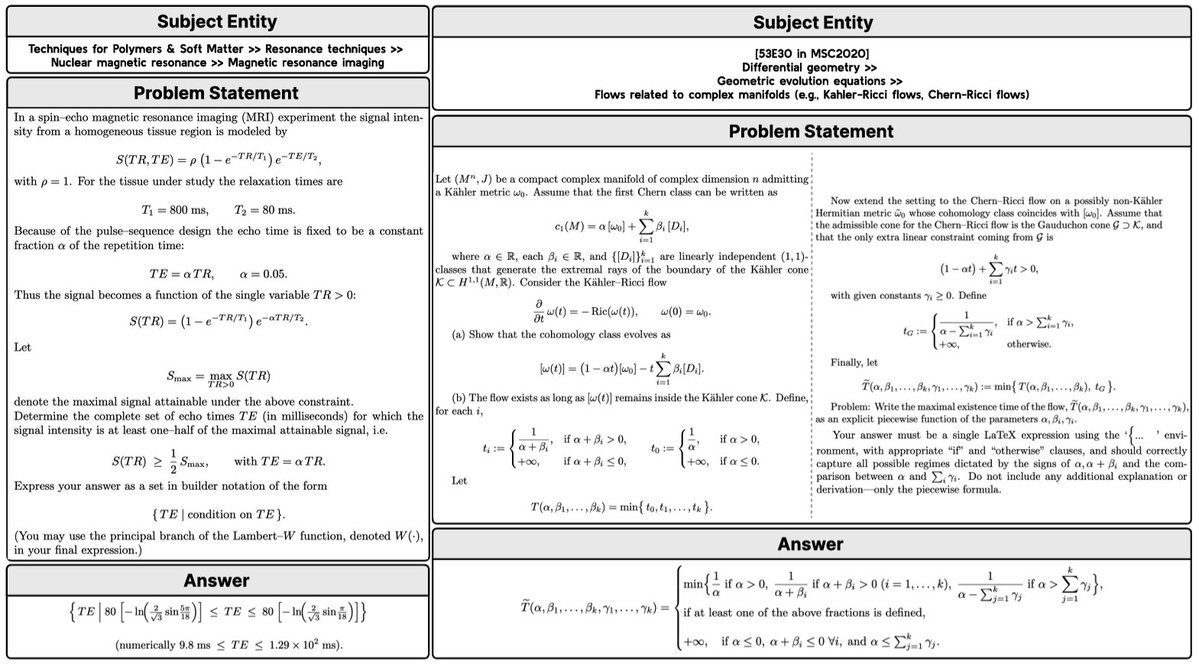
New LM Reasoning Benchmarks for Complex Mathematical Objects
By
–
🧮New work from @AIatMeta & @LTIatCMU! LM reasoning benchmarks mostly use simple answers like numbers (AIME) or multiple-choice options (GPQA). But for complex mathematical objects, performance drops sharply. We propose a set of solutions to solve this: arxiv.org/abs/2603.18886
-
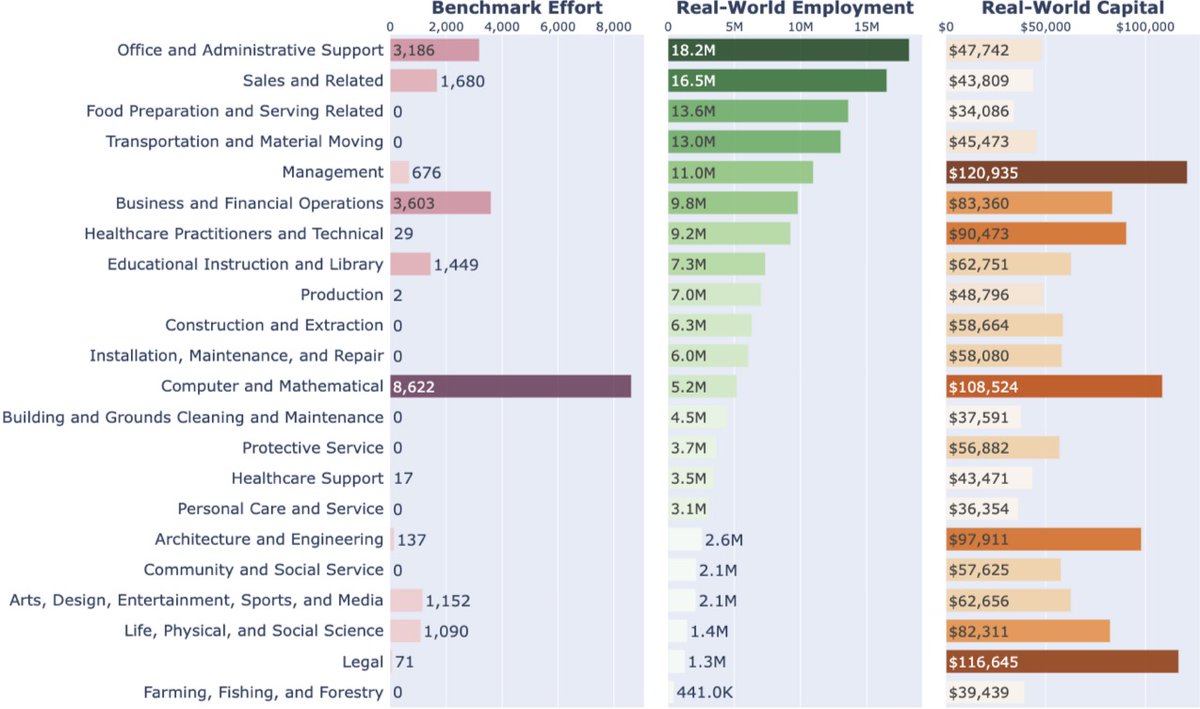
AI Agents Benchmarks Don’t Match Real Human Work
By
–
AI agents are tackling more and more "human work" But are they benchmarked on the work people actually do? tl;dr: Not really Most benchmarks focus on math & coding, while most human labor and capital lie elsewhere. 📒 We built a database linking agent benchmarks & real-world work Submit new tasks + agent trajectories today 🧵
-

Midtraining in ML Pipelines: When It Helps and When It Fails
By
–
Midtraining is a new part of many training pipelines, but when does it help and can it backfire? 🤔 In our new preprint, we use controlled experiments to pin this down. TL;DR; midtraining helps the most when it “bridges” pretraining and posttraining, and mitigates forgetting after posttraining. Timing is also very important. 🧵
-
Agent Data Protocol Accepted to ICLR 2026 Oral Presentation
By
–
Updates: Excited to share that Agent Data Protocol (ADP) is accepted to ICLR 2026 Oral! 🎉 We also added support for 3 new datasets: SWE-Play, MiniCoder, and Toucan, bringing us to 3M trajectories supported. If you're training agentic LMs, try ADP + tell us what dataset/agent format you want next. PRs & requests welcome. Let's make this the open standard for agent training data 🔥 🚀Original post: nitter.net/yueqi_song/status/1983… 📄Read our paper: arxiv.org/abs/2510.24702 🌐Check our project website: agentdataprotocol.com
-

OpenScholar Scientific Deep Research Agents Accepted to Nature
By
–
Thrilled to share: OpenScholar – our work on scientific deep research agents for reliable literature synthesis -has been accepted to Nature! 🎉 Huge thanks to collaborators across institutions who made this possible!
-

CooperBench: AI Agents Perform 50% Worse in Teams
By
–

Introducing the curse of coordination. Agents perform 50% worse in teams than working alone. People building human-AI collaboration today don't realize why current LLMs fail to be good teammates. We built CooperBench to study this. For humans, we recognize that teamwork isn't just the sum of individual capability. Communication and coordination often outweigh raw skill. But for AI? We're only hill-climbing benchmarks that evaluate solo technical abilities. CooperBench A benchmark to evaluate agent cooperation in realistic software teamwork tasks. The setup is intuitive: two agents, two tasks, two VMs, one chat channel (agents can send over arbitrary text, even the entire patch they wrote). We evaluate whether the merged solution from both agents passes the requirements of both tasks. The curse of coordination The most striking result: agents perform 50% worse in teams (black line) than working alone (blue line). Why is this happening? Is it because they can't use the communication tool? No. They spent 20% of their time sending messages. The problem? Those messages were repetitive, vague, ignored questions, or straight-up hallucinated. But bad communication is only part of the story. We found two deeper failures: Commitment: Agents don't do what they promised. Expectations: Agents don't expect others to keep promises either. Without these, cooperation collapses. However, there is a silver lining We also find emergent coordination behaviors, e.g. role division, resource division, and negotiation, which gives us hope that we can use reinforcement learning to improve coordination. What's next? It is true that highly-engineered multi-agent orchestration could largely sidestep the coordination problem. However, we care more about the AI's capability: if we truly want AI to be our teammates, we need them to be natively capable of effective communicating and coordinating. Two agents on software tasks is just the beginning. The real goal: agents that can cooperate with us well enough to actually empower us. CooperBench is our first step. If you're working on this too, let's talk.
-

SP3F: Improving LLM Reasoning in Lower-Resource Languages
By
–
We introduce SP3F: an algorithm to improve LLM reasoning in lower-resource languages (e.g., Indonesian, Bengali, and Swahili), no manual data collection needed! SP3F produces models that out-perform fully post-trained models across multiple tasks and languages🧵 [1/N]
-
Free Online Modern AI Course with LLM Chatbot Building
By
–
I've decided to release a minimal, free online version of my upcoming "10-202 – Intro to Modern AI" course, starting January 26: modernaicourse.org. As a brief summary, this course introduces students to the elements of modern AI systems: you'll build and train a simple LLM chatbot from scratch in PyTorch, without any pre-built layers or pre-trained models at all. More information about the course, and a link to enroll, is available on the webpage link above. In the free online version, you can watch all lecture videos and submit all the assignments (all of which are autograded in the full course anyway). There won't be quizzes/exams, and there's no credit offered via CMU; this is purely for educational purposes. The online course will begin two weeks after the CMU version, and lectures and assignments will all be released with the same two-week delay after the in-person version. Note that this is a first-time offering for this course, so I certainly expect some hiccups along the way. But I hope the material will prove useful for many people. Zico Kolter (@zicokolter) I'm teaching a new "Intro to Modern AI" course at CMU this Spring: modernaicourse.org. It's an early-undergrad course on how to build a chatbot from scratch (well, from PyTorch). The course name has bothered some people – "AI" usually means something much broader in academic contexts – but I think the time has come where the first thing that many students interested in AI should see is how the AI they are familiar with actually works (because it's really simple!) The more people who understand it the better. I'll be trying to put as much material as I can that we develop online (assignments + autograding, hopefully lecture videos), though as a first-time course there are also likely to be some bumps along the way. Hopefully it becomes a good resource over time, though. Feedback welcome. — https://nitter.net/zicokolter/status/1987938761498411376#m
-
Robotic Steering: Mechanistic Interpretability for VLA Finetuning
By
–
🎉Despite massive pretraining, VLAs need to adapt to specific physical contexts. We introduce Robotic Steering, a novel finetuning method using mechanistic interpretability to surpass standard FT:
— Chancharik Mitra (@chancharikm) 26 décembre 2025
🎁 22× fewer parameters
🎁 +53% on unseen tasks
🎁 Interpretable
Thread below👇 pic.twitter.com/RsSU8RANNq🎉Despite massive pretraining, VLAs need to adapt to specific physical contexts. We introduce Robotic Steering, a novel finetuning method using mechanistic interpretability to surpass standard FT: 🎁 22× fewer parameters 🎁 +53% on unseen tasks 🎁 Interpretable Thread below👇